The Problem With Everything You’ve Read So Far
Most AI Mode coverage falls into one of two failure modes. The first is breathless product journalism that describes features without explaining the underlying machine. The second is reassuring takes from practitioners who’ve absorbed Google’s talking points and passed them along — “standard SEO is all you need,” “quality content wins,” “nothing has fundamentally changed.”
Both are wrong in ways that will cost brands money.
This piece goes underneath the marketing. It’s built on Google’s patent filings, verified quantitative studies, and a few findings the broader community has conspicuously failed to take seriously. The goal is simple: by the end, you should understand exactly how AI Mode works, exactly why it breaks traditional SEO orthodoxy, and exactly what to do about it.
We’re going to cover a lot of ground. Start with the most important thing, which almost everyone has gotten wrong.
What AI Mode Actually Is (And What It’s Not)
Here is the most expensive misconception in your industry right now: that AI Mode is a smarter version of something you already know.
Actually, it isn’t. And conflating it with familiar systems has been causing real strategic errors — brands optimizing for AI Overviews visibility and assuming it transfers, SEO teams citing ChatGPT behavior as an analogue, practitioners treating AI Mode like a more sophisticated Featured Snippet. These are category mistakes. They lead to wrong investment decisions and wrong measurement frameworks.
So let’s be surgical about the taxonomy.
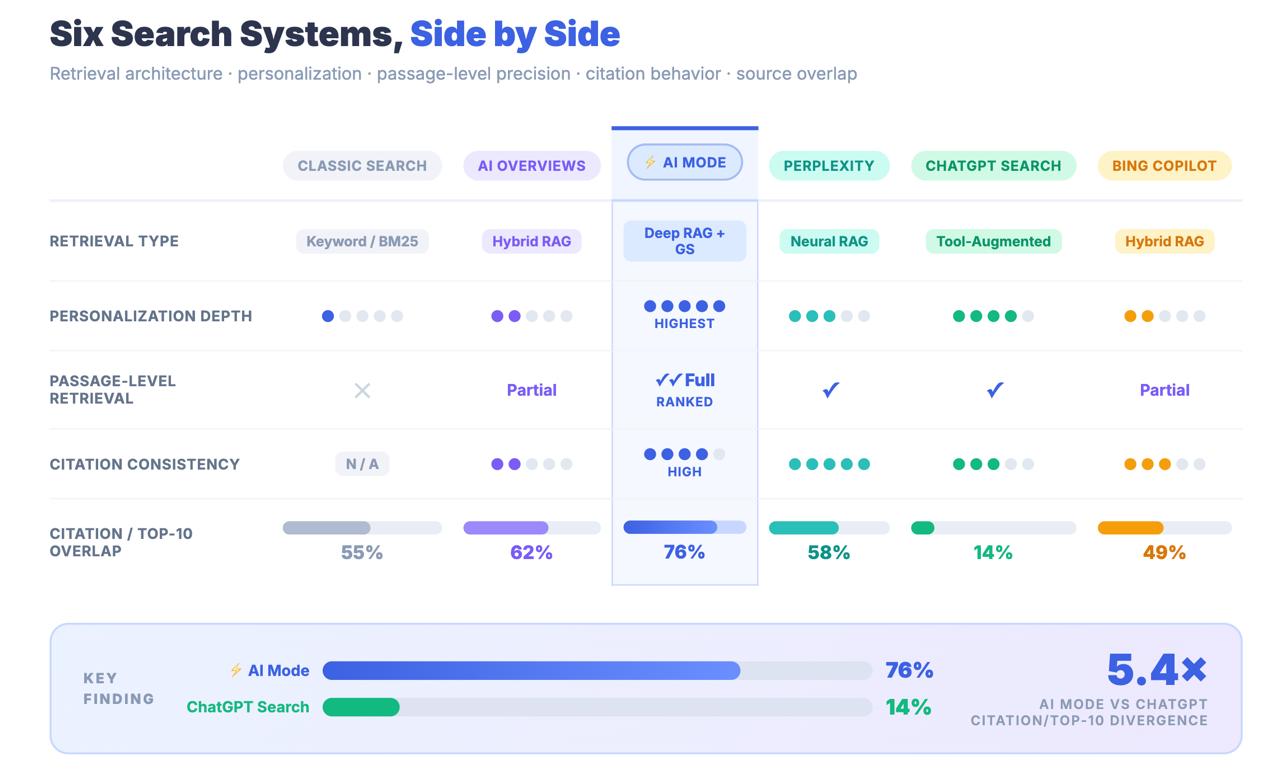
Classic Search
A document retrieval system. You input a query; it returns a ranked list of URLs. Google’s job ends at the SERP. What you do with the blue links is your business. The optimization game here has been stable for twenty years: signal authority to the crawler, match keyword intent, earn engagement signals. You know this system.
AI Overviews (AIO)
A generative layer bolted on top of Classic Search. AIO takes Google’s existing retrieval results and synthesizes them into a summary paragraph, pulling almost entirely from already-top-ranked pages — 76.1% of AI Overview citations come from the top 10 results. It is a UI feature, not a new retrieval system. Think of it as a smart snippet with a language model writing the copy. The index beneath it is unchanged; the ranking signals beneath it are unchanged. Classic SEO, applied well, is largely sufficient for AIO eligibility.
SGE (Search Generative Experience)
Dead. The Labs experiment that ran through 2023–2024. Stop referencing it as a live system.
Gemini (standalone)
An LLM assistant. No persistent connection to Google’s live search index. No Knowledge Graph integration. No Shopping Graph. Its responses are drawn from training data, not real-time retrieval. A completely different inference pipeline from everything else on this list.
Perplexity and ChatGPT Search
Retrieval-augmented generation (RAG) systems that pull from public web indices and synthesize answers. Perplexity uses a real-time crawl; ChatGPT fetches full URL content at runtime against the Bing API. Their retrieval is comparatively simple — no persistent user model, no multi-tier knowledge infrastructure, no stateful context across sessions.
AI Mode
None of the above.
AI Mode is a multi-stage, stateful, personalized, passage-level retrieval and synthesis engine that fires multiple parallel sub-queries against Google’s full knowledge infrastructure — Search index, Knowledge Graph, Shopping Graph (50B+ products), and Maps — assembles a custom corpus of retrieved passages, re-ranks them using a pairwise LLM, and generates a response with fragment-level citation verification.
It is not a wrapper around Classic Search. It is a parallel search system that happens to live inside the same product. And the number that should stop you cold:
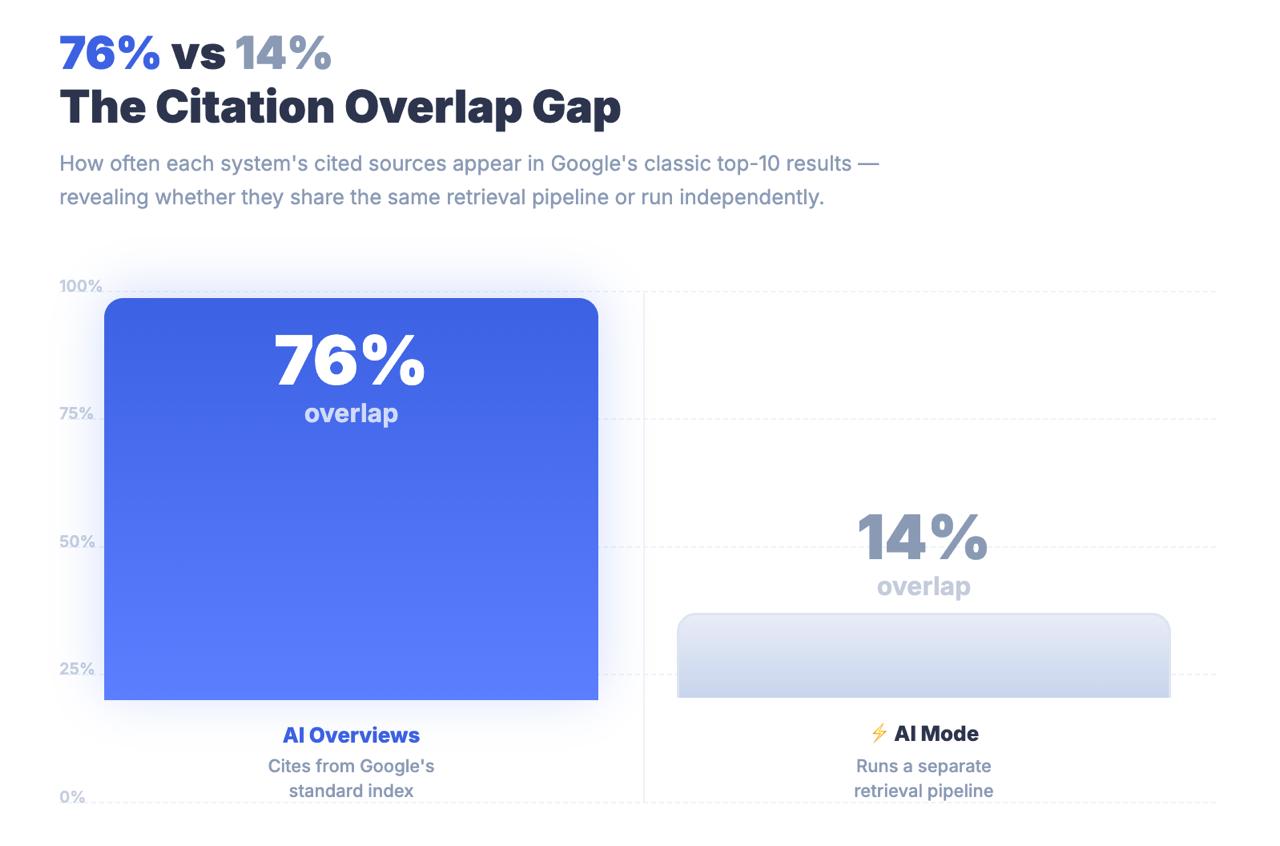
Only 14% of URLs cited by AI Mode rank in Google’s traditional top 10.
For AI Overviews, that number is 76%. The gap between those two figures is not a rounding error. It is an architectural finding that tells you AI Mode is not finding content through classical ranking signals. It is finding content through a completely different retrieval pipeline — and the optimization strategies that got you to page one may be largely irrelevant to whether you get cited at all.
Being on page one of Google is necessary for AI Overview visibility; for AI Mode, it is largely irrelevant.
The systems are related the way a library and a research assistant are related. Both deal in books. One hands you a ranked shelf. The other reads the books for you, synthesizes the answer, and decides which passages were worth citing. Your job is fundamentally different depending on which one you’re optimizing for — and right now, most teams are optimizing for the shelf when the research assistant is what their audience is using.
Key Takeaway: AI Mode shares a brand with Google Search and a URL with AI Overviews, but it is a structurally distinct retrieval system. Only 14% of AI Mode citations come from traditional top-10 results — compared to 76% for AI Overviews. Treating AI Mode as an AIO extension is a measurement error with real strategic consequences.
The Architecture: How a Query Becomes an Answer
Most explanations of AI Mode describe what it does from the outside: “it understands your query better,” “it synthesizes multiple sources,” “it provides conversational answers.” These descriptions are not wrong. They are useless for optimization.
What follows is the full pipeline, named component by component, with the patents that govern each stage. This is what optimization actually means to target — because you can’t systematically improve a system you can’t name.
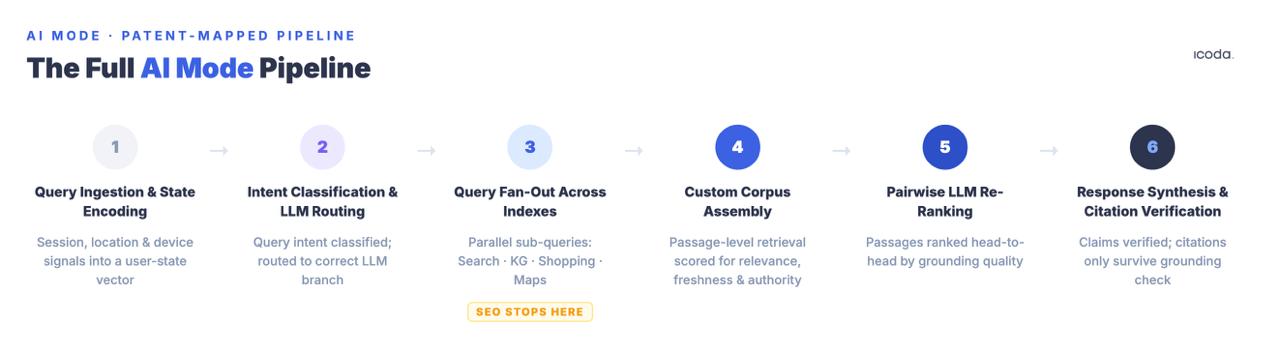
The six-stage pipeline is what you’re actually optimizing for. Most current practice addresses one stage.
Stage 1: Query Ingestion and User State Encoding
The raw query does not enter retrieval directly. It is first paired with the user’s stateful context vector — a dense embedding built from session history, prior queries across all sessions, device, location, time of day, and Google ecosystem signals (Search, Maps, Gmail, YouTube). This personalization vector modifies what “this query means” before any retrieval begins.
Two users typing identical queries are effectively issuing different retrieval instructions. The implications of this are significant enough to deserve their own section — which comes immediately after this one.
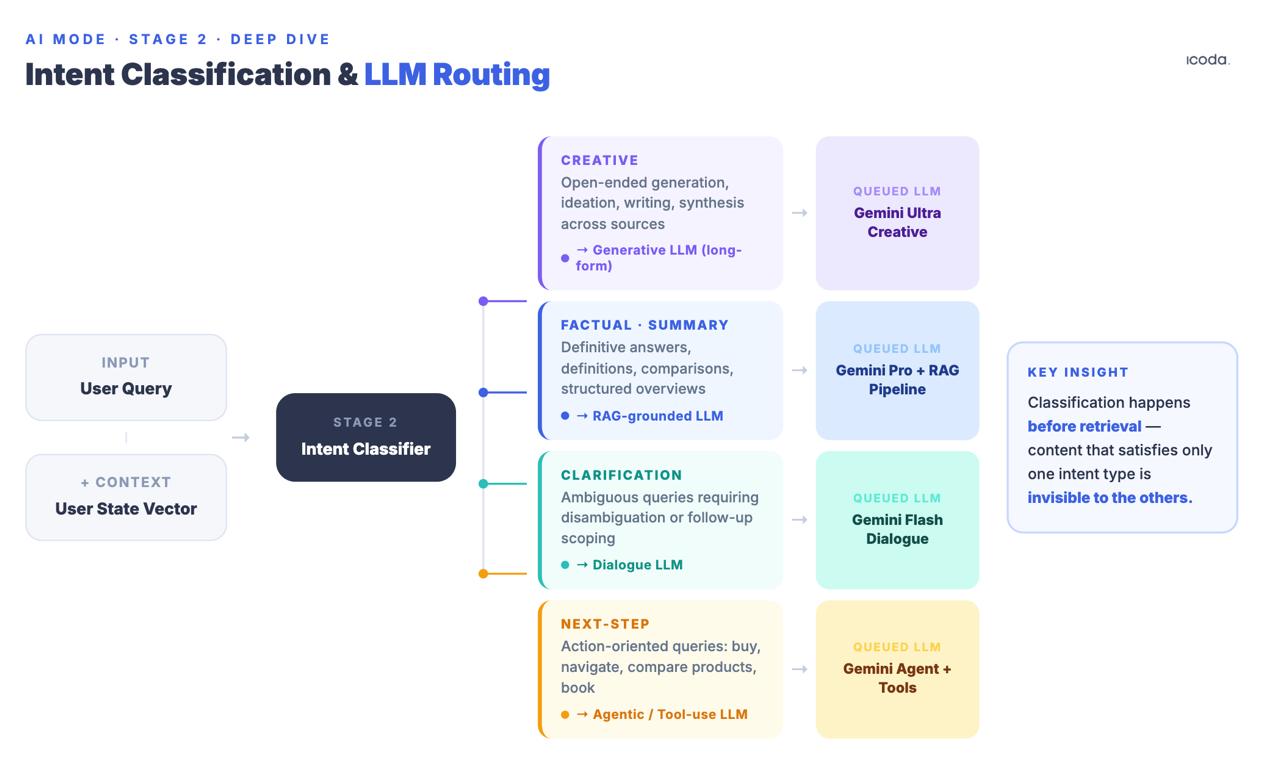
Stage 2: Query Intent Classification and LLM Routing
Before retrieval, the system classifies the query into intent categories: creative, factual/summary, clarification, or next-step/task. Based on this classification, different downstream language models are queued. The stateful chat patent (US20240289407A1) names them explicitly: Creative Text LLM, SRP Generative LLM, Clarification LLM, Next Step LLM.
This happens before retrieval. The classification determines not just which model synthesizes the response, but which retrieval signals matter most. A page that ranks well for informational queries may not enter the candidate pool at all if the intent classifier routes this session to a next-step LLM optimizing for task completion rather than information synthesis.
Stage 3: Query Fan-Out
This is where AI Mode diverges most sharply from every system that came before it.
The system generates multiple synthetic sub-queries from the original, covering eight documented variant types: equivalent, related, implicit, comparative, clarification, temporal, geographic, and professional-context. Note the filing date. Google has been building multi-query fan-out for seven years. AI Mode is the consumer product of a long architectural runway.
The “implicit” and “comparative” variant types deserve particular attention because they generate queries the user didn’t ask but would likely need. If someone searches “best CRM for startups,” the fan-out generates not just reformulations but implicit queries (“what CRM scales past Series A?”), comparative queries (“Salesforce vs. HubSpot for early-stage companies”), temporal queries (“CRM pricing changes 2025”), and professional-context variants that distinguish a founder researching from a RevOps manager deciding.
All sub-queries fire concurrently across Google Search index, Knowledge Graph, Shopping Graph, and Maps. Google has confirmed AI Mode can run “hundreds of searches” for a single complex query. The Thematic Search patent (US12158907B1) organizes results into semantic clusters; sub-themes trigger additional retrieval rounds iteratively — meaning the fan-out can recurse, not just burst once.
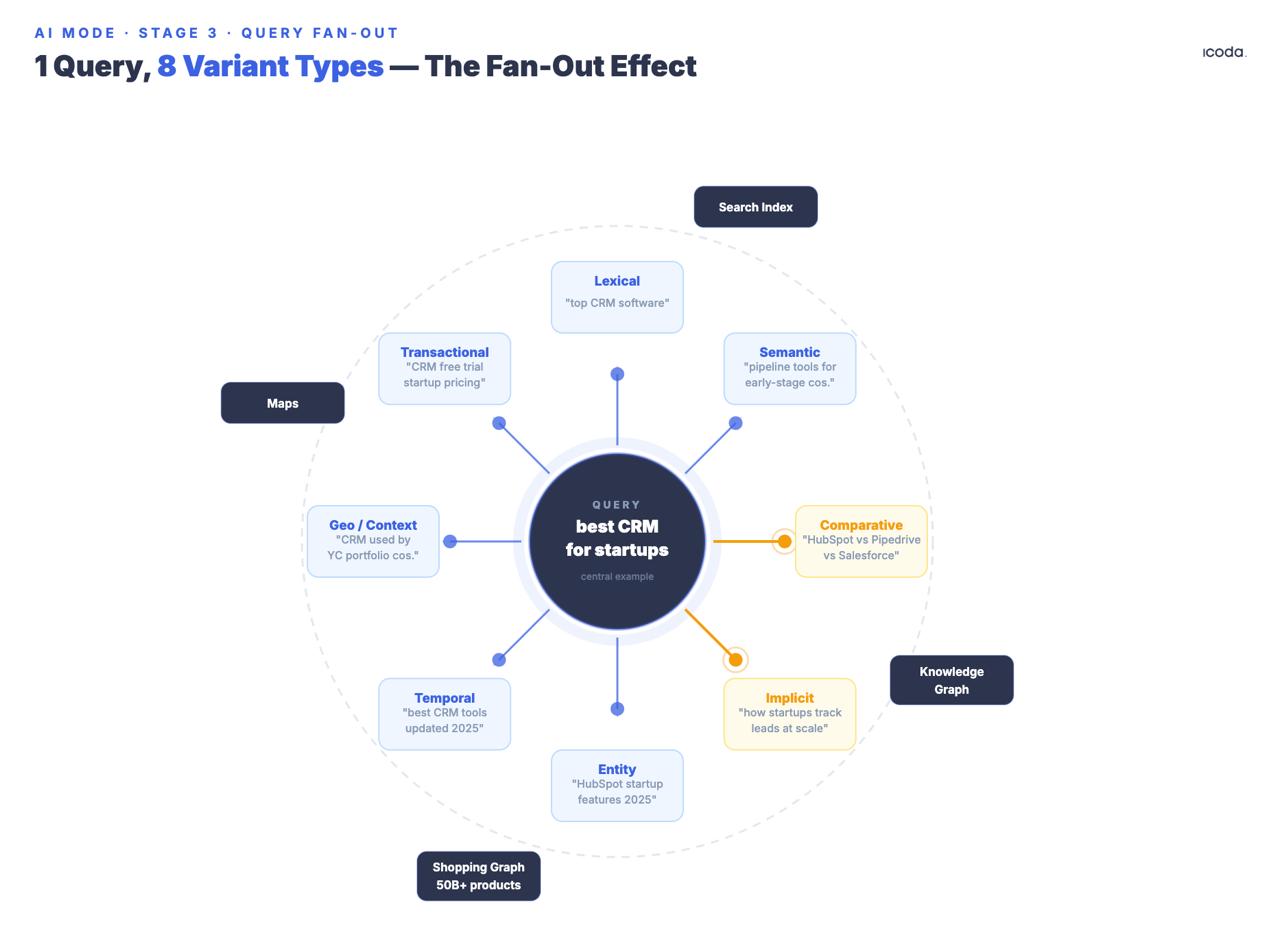
Google filed the foundational fan-out patent in 2018 — AI Mode is the consumer product of a seven-year architectural build.
A brand that has authoritative content on “best CRM” but nothing comparative, nothing temporal, and nothing targeting professional-context variants is absent from multiple query types that fire on every relevant session. The fan-out doesn’t care about your domain authority — it cares whether each variant sub-query surfaces a passage that wins pairwise comparison.
Stage 4: Custom Corpus Assembly
Retrieved passages — not documents, passages — are assembled into a custom corpus. Patent WO2024064249A1 describes how the system may retrieve up to five adjacent chunks around a relevant passage to preserve contextual coherence. This means prose flow through a document section matters. A well-structured argument that earns a retrieval hit pulls the surrounding paragraphs into the corpus with it.
The corpus is custom. Every user, every session, every query produces a different one. There is no universal document pool your content is competing within — there are millions of user-specific pools assembled on demand.
Stage 5: Pairwise LLM Re-Ranking
Passages from across all fan-out sub-queries compete against each other. The ranking mechanism is not BM25. It is not TF-IDF. An LLM compares passages in pairs — which passage better satisfies a given sub-query? — across multiple comparison rounds. Winners advance; losers exit.
This stage is where most SEO investment currently fails to make contact. Dense, direct, factual passages that answer specific sub-questions in the first sentence cleanly win pairwise comparisons. Narrative, discursive, opinion-heavy content — the kind that performs well in long-form editorial SEO — tends to lose, because it makes an LLM work harder to extract the relevant claim. A Reddit thread that opens with a direct answer to a niche question can outperform a 3,000-word authoritative guide that buries the answer in paragraph eight. The pairwise mechanism rewards immediate payoff, not accumulated credibility.
Stage 6: Response Synthesis and Citation Verification
The surviving passages are fed to Gemini. Gemini generates a natural-language response. Then the Response Linkifying Engine performs fragment-level verification: it matches each fragment of the generated response against specific corpus passages and embeds citations inline.
This is not page-level attribution. A sentence in the response that matches a passage on your blog earns a citation. The rest of your page may not be referenced at all. A factually dense 400-word article can out-cite a 3,000-word authoritative guide — because it produces more verifiable fragments per unit of text. The mechanism structurally rewards assertion density over comprehensive coverage. This is a direct inversion of what traditional long-form SEO optimizes for.
Key Takeaway: AI Mode is a six-stage pipeline. Traditional SEO primarily addresses Stage 3 (retrieval eligibility). Citation is won or lost at Stages 4–6 — passage-level density, pairwise LLM competition, and fragment-level factual grounding — none of which are addressed by standard optimization practice.
The Personalization Layer: Why Rank Tracking Is Measuring a Fiction
There is a fact embedded in the AI Mode architecture that the SEO industry has not fully reckoned with. Let’s state it plainly:
The same query issued by two different users produces different retrieval sets. Not different rankings of the same documents. Different documents entirely.
The User Embedding Models patent describes how Google encodes behavioral signals — queries, clicks, dwell time, location history, Maps activity, YouTube watch history, Gmail content — into dense vectors that are paired with every incoming query. The personalization vector modifies retrieval before any traditional ranking signal is applied.
You are not in a race against competitors for a universal ranked position. You are in a race for relevance within specific user-persona query contexts that you cannot directly observe, cannot directly measure, and cannot replicate in a rank tracking tool.
What Feeds the User Embedding
The stateful chat patent (US20240289407A1) and the User Embedding Models patent together describe a personalization stack drawing from:
- Full query history across all Google Search sessions (for logged-in users)
- Click, hover, and dwell patterns at aggregate behavioral scale
- Device type and location signals
- Google ecosystem data: Maps check-ins, YouTube watch time by topic, Gmail content
That last category is worth dwelling on. The “Personal Context” feature — previewed at Google I/O 2025 and in partial deployment as of early 2026 — will explicitly incorporate Gmail, Calendar, and Google account data directly into retrieval. When it fully launches, a user who emailed about ski trips last week will get different AI Mode responses to “outdoor winter gear” than someone who recently purchased running shoes on Google Shopping. The concept of a canonical search result for any query will be functionally dead. Every result will be a product of the user’s behavioral history across the full Google ecosystem — not just their search queries.
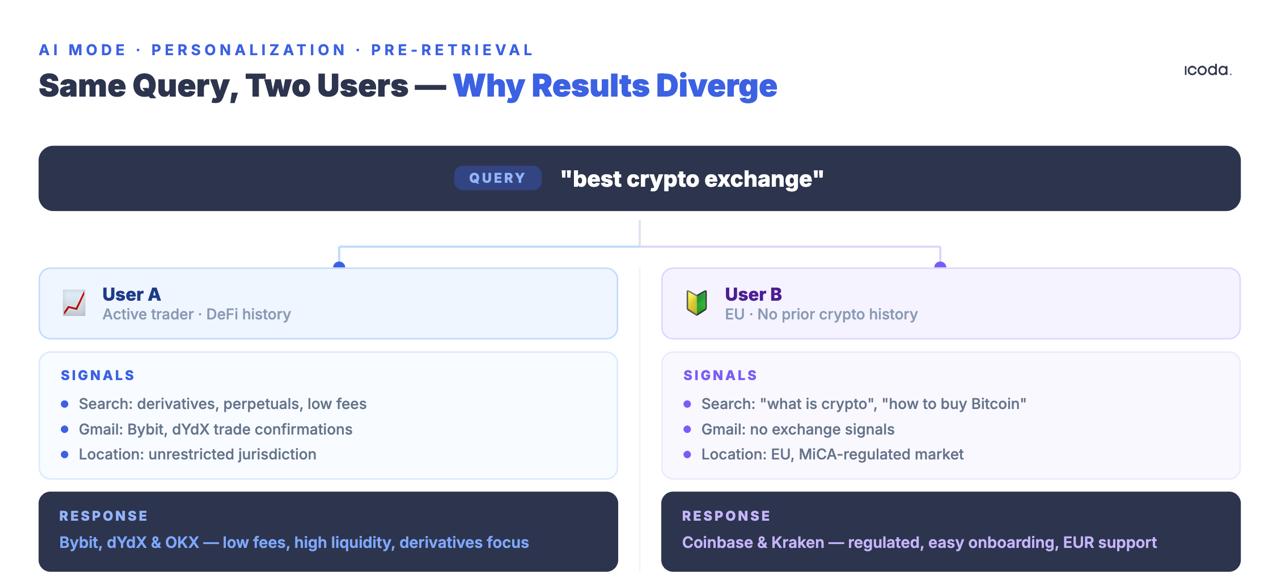
The Measurement Consequence
Rank tracking tools query from clean-room, uncontextualized environments. Real users are deeply contextualized. The tool is measuring a hypothetical position that no real user sees.
This is not a precision complaint. It is a validity complaint. The measurement is not imprecise — it is measuring the wrong thing entirely. A position-tracking number from a rank tracker running against AI Mode represents the experience of a user with no search history, no location signal, no ecosystem data, and no session context. That user does not exist at any meaningful volume.
The antitrust ruling sharpens this point in an ironic way. The December 2025 remedy requires Google to share its search index with competitors twice over five years. But it cannot share the user embedding models. Index data — now becoming a commodity — is not what drives AI Mode personalization. The learning flywheel is: 14 billion daily queries, continuously feeding updated user embeddings that no competitor can replicate. Competitors get a snapshot of the shelf. Google keeps the librarian who has read every patron’s face.
What Actually Works for Measurement
The brands best positioned to navigate this aren’t the ones with the highest-fidelity rank tracking. They’re the ones who’ve accepted that personalized AI retrieval requires a different measurement paradigm and built toward it. The four proxies that have real signal:
Brand share-of-voice in AI responses, tracked via third-party tools (Profound, ZipTie, Ahrefs Brand Radar). Sampling-based approximations, not complete coverage — but they measure citation presence, which is the correct output variable. Track this against competitors, not against an absolute score.
GSC impression/click decoupling at the query segment level. Informational queries showing rising impressions with declining CTR is the primary visible signature of AI Mode cannibalization. Segment by intent type; watch the divergence sharpen over time.
Manual AI Mode citation audits for your 20 most commercially important queries. Note which pages are cited, which passages appear in the response, and whether your brand appears in competitor-focused fan-out sub-queries — because it sometimes does. AI Mode generates 3.3 entity mentions per response on average versus 1.3 for AI Overviews. Your brand may be present in sessions where your domain is never clicked.
Branded search volume as a downstream signal. If AI Mode is generating brand awareness without driving direct clicks — which the architecture suggests it increasingly does — branded search volume should move as a lagging indicator over a 60–90 day window.
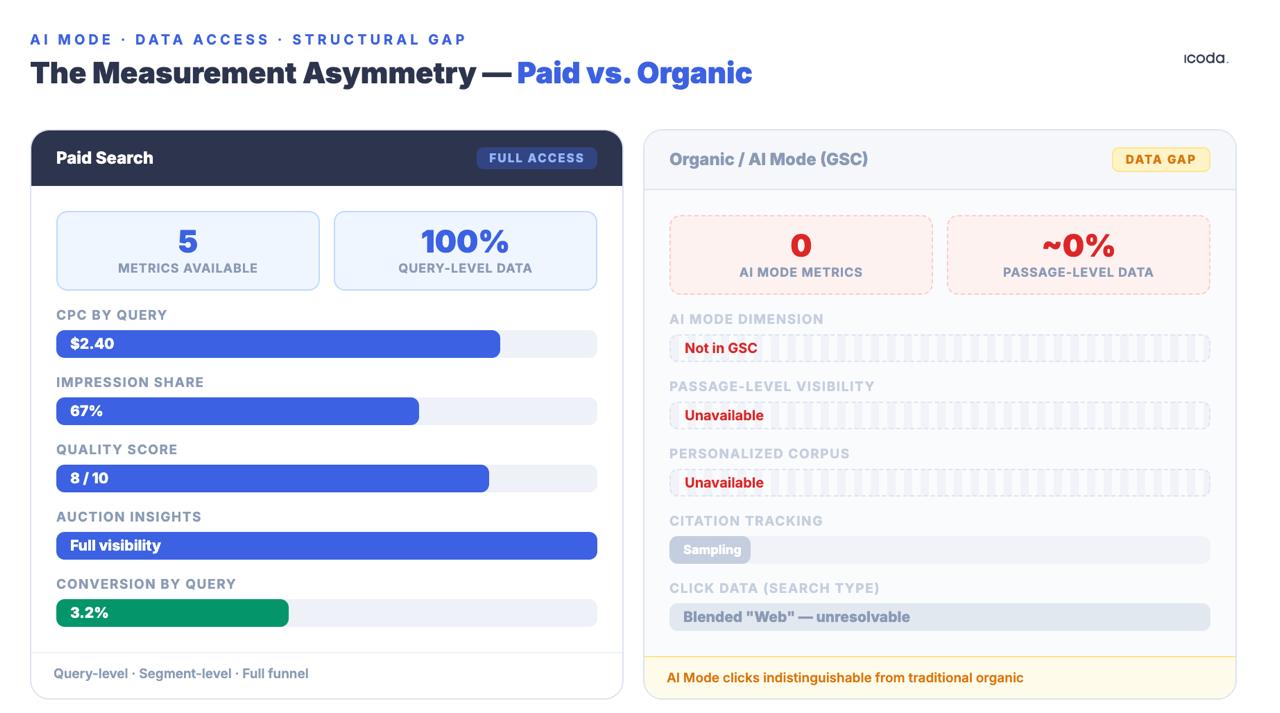
The measurement gap between paid and organic search has existed for years. AI Mode has widened it to a structural chasm.
None of these are perfect. The asymmetry with paid search teams is structural and significant: paid teams have CPC data, impression share, quality scores, and auction insights at the query level. Organic teams get GSC data that is deliberately aggregated, sampled, and anonymized — and AI Mode clicks are mixed into the generic “Web” search type, indistinguishable from traditional organic traffic. This gap is not a temporary tooling problem. It is a deliberate product architecture decision, and it is widening as AI Mode makes organic retrieval more opaque, not less.
The honest answer is that you cannot currently measure your AI Mode visibility with precision. You can measure proxies. You can track brand presence. You can watch the impression/click ratio deteriorate in real time and use it to prioritize. But you should not confuse proxy measurement with ground truth — and you should stop pretending that a rank tracker pointed at an uncontextualized query tells you anything meaningful about how a real, logged-in, contextualized user experiences your content inside AI Mode.
Key Takeaway: User embedding vectors modify AI Mode retrieval before classical ranking signals apply, making rank tracking — as currently practiced — a measurement of a user who doesn’t exist. Shift primary measurement from position to brand share-of-voice in AI responses, supplemented by GSC decoupling signals and manual citation audits.
Conclusion
AI Mode is not smarter Classic Search. It is a separate retrieval system — six stages, passage-level, personalized before any ranking signal applies — and it is already deciding which brands exist in the answers your audience is reading.
The 14% citation overlap with traditional top-10 results tells you everything: ranking and citation are now independent variables. You can own page one and be invisible in AI Mode. You can sit at position 47 and earn consistent citations if your content produces passages that win pairwise LLM comparisons for the right sub-query variants.
The architecture is documented. The patents are public. The window to adapt before AI Mode becomes the default search experience is measured in quarters, not years.
What happens next is a choice.
Share with


Rate the article













