المشكلة في كل ما قرأته حتى الآن
تقع معظم التغطيات حول وضع الذكاء الاصطناعي في أحد نمطي فشل. الأول صحافة منتجات متحمسة تصف الميزات دون شرح الآلة الكامنة وراءها. والثاني قراءات مطمئنة من ممارسين استوعبوا نقاط حديث Google ومرّروها — «SEO القياسي هو كل ما تحتاجه»، «المحتوى عالي الجودة يفوز»، «لم يتغير شيء جذريًا».
كلاهما خاطئ بطرق ستكلّف العلامات التجارية أموالًا.
يتجاوز هذا المقال التسويق. وهو مبني على إيداعات براءات اختراع Google، ودراسات كمية مُتحقق منها، وبعض النتائج التي أخفق المجتمع الأوسع بشكل لافت في أخذها على محمل الجد. الهدف بسيط: بحلول النهاية، ينبغي أن تفهم بدقة كيف يعمل وضع الذكاء الاصطناعي، ولماذا يكسر أرثوذكسية SEO التقليدية، وما الذي يجب فعله حياله.
سنغطي الكثير من النقاط. ابدأ بأهم شيء، وهو ما أخطأ فيه تقريبًا الجميع.
ما هو وضع الذكاء الاصطناعي فعلاً (وما ليس كذلك)
إليك أغلى سوء فهم في صناعتك الآن: أن وضع الذكاء الاصطناعي نسخة أذكى من شيء تعرفه بالفعل.
في الواقع، ليس كذلك. وخلطه بأنظمة مألوفة تسبب في أخطاء استراتيجية حقيقية — علامات تجارية تُحسّن للظهور في AI Overviews وتفترض أن ذلك ينتقل، وفرق SEO تستشهد بسلوك ChatGPT بوصفه نظيرًا، وممارسون يتعاملون مع وضع الذكاء الاصطناعي كأنه Featured Snippet أكثر تطورًا. هذه أخطاء تصنيفية. وهي تقود إلى قرارات استثمار خاطئة وأطر قياس خاطئة.
لذا فلنكن دقيقين في التصنيف.
البحث الكلاسيكي
نظام لاسترجاع المستندات. تُدخل استعلامًا؛ فيُرجع قائمة مرتبة من عناوين URL. ينتهي دور Google عند صفحة نتائج البحث (SERP). وما تفعله بالروابط الزرقاء شأنك. لعبة التحسين هنا مستقرة منذ عشرين عامًا: إرسال إشارات السلطة إلى الزاحف، ومطابقة نية الكلمات المفتاحية، وكسب إشارات التفاعل. أنت تعرف هذا النظام.
AI Overviews (AIO)
طبقة توليدية مُضافة فوق البحث الكلاسيكي. يأخذ AIO نتائج الاسترجاع الحالية لدى Google ويُركّبها في فقرة ملخصة، مستندًا تقريبًا بالكامل إلى الصفحات الأعلى ترتيبًا بالفعل — 76.1 % من استشهادات AI Overview تأتي من أفضل 10 نتائج. إنها ميزة واجهة مستخدم، وليست نظام استرجاع جديدًا. فكّر فيها كقصاصة ذكية يكتب نصها نموذج لغوي. الفهرس تحتها لم يتغير؛ وإشارات الترتيب تحتها لم تتغير. SEO الكلاسيكي، عند تطبيقه جيدًا، يكون كافيًا إلى حد كبير لأهلية الظهور في AIO.
SGE (Search Generative Experience)
انتهى. تجربة Labs التي امتدت خلال 2023–2024. توقّف عن الإشارة إليها كنظام حي.
Gemini (مستقل)
مساعد LLM. لا اتصال دائمًا بفهرس البحث الحي لدى Google. لا تكامل مع Knowledge Graph. ولا Shopping Graph. تُستمد ردوده من بيانات التدريب، لا من استرجاع لحظي. خط استدلال مختلف تمامًا عن كل ما في هذه القائمة.
Perplexity و ChatGPT Search
أنظمة توليد معززة بالاسترجاع (RAG) تسحب من فهارس الويب العامة وتُركّب الإجابات. يستخدم Perplexity زحفًا في الوقت الفعلي؛ ويجلب ChatGPT محتوى عناوين URL كاملة وقت التشغيل عبر واجهة Bing API. استرجاعها أبسط نسبيًا — لا نموذج مستخدم دائم، ولا بنية معرفة متعددة الطبقات، ولا سياق حالّي عبر الجلسات.
وضع الذكاء الاصطناعي
لا شيء مما سبق.
وضع الذكاء الاصطناعي محرك استرجاع وتركيب متعدد المراحل، حالّي، مُخصص، وعلى مستوى المقاطع، يُطلق عدة استعلامات فرعية متوازية عبر بنية المعرفة الكاملة لدى Google — فهرس البحث، وKnowledge Graph، وShopping Graph (أكثر من 50B منتجًا)، وMaps — ويجمع مجموعة مخصصة من المقاطع المسترجعة، ثم يعيد ترتيبها باستخدام LLM بالمقارنة الثنائية، ويولّد استجابة مع تحقق من الاستشهادات على مستوى الشذرات.
ليس غلافًا حول البحث الكلاسيكي. إنه نظام بحث موازٍ يعيش داخل المنتج نفسه. والرقم الذي ينبغي أن يوقفك تمامًا:
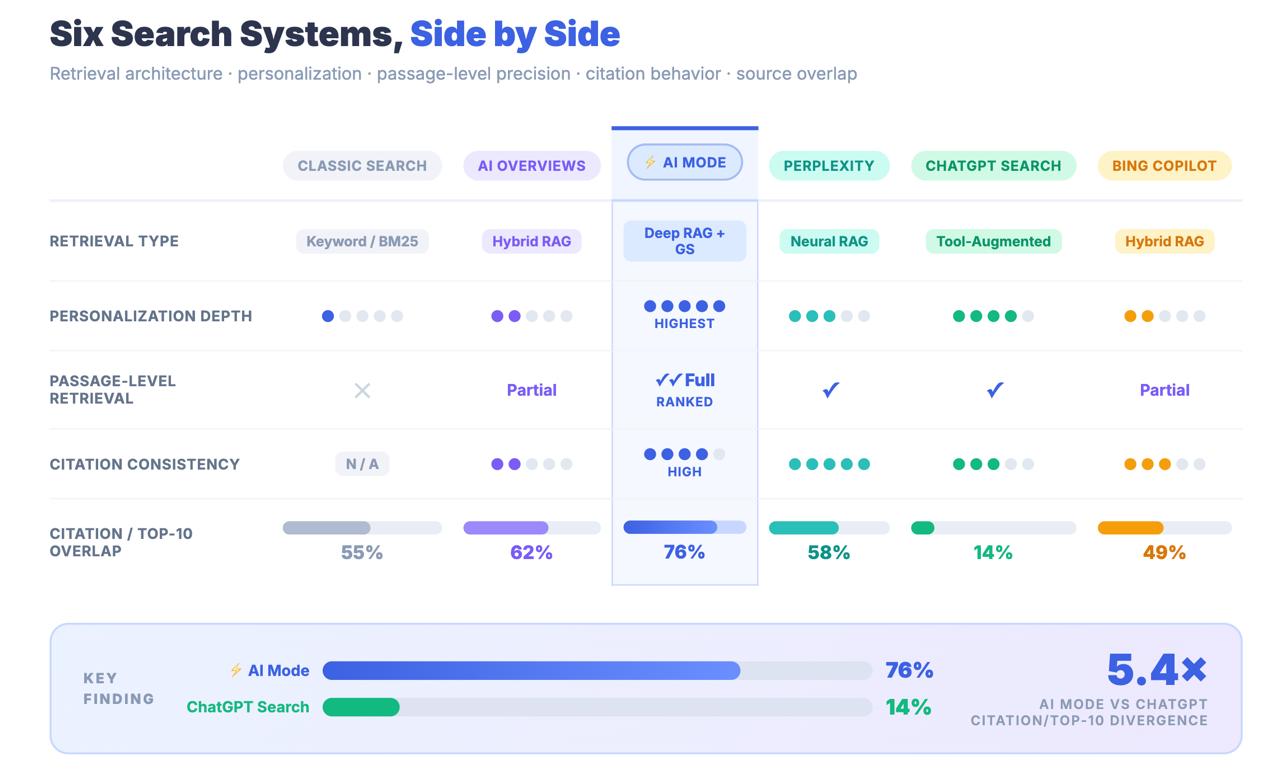
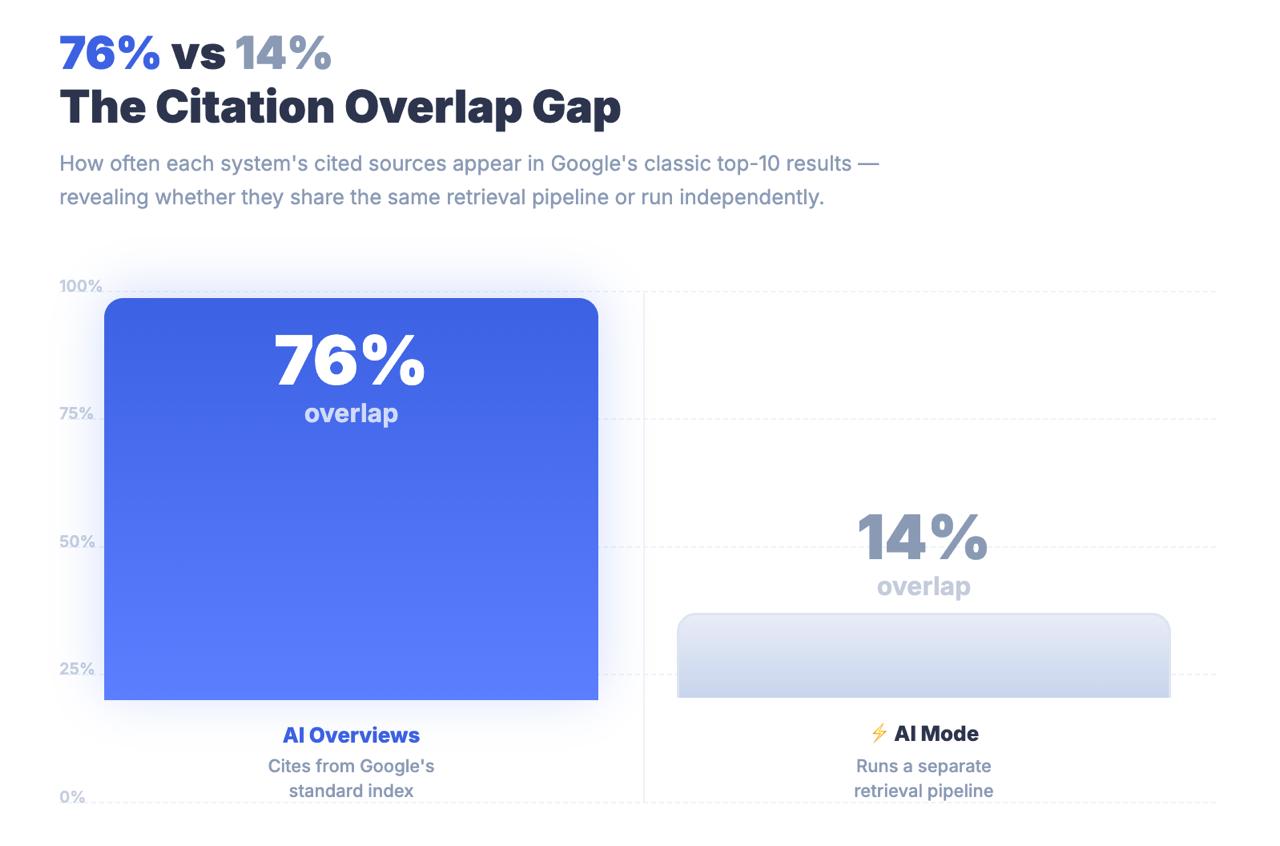
فقط 14 % من عناوين URL التي يستشهد بها وضع الذكاء الاصطناعي تقع ضمن أفضل 10 نتائج تقليدية في Google.
بالنسبة إلى AI Overviews، هذا الرقم 76 %. الفجوة بين الرقمين ليست خطأ تقريبيًا. إنها نتيجة معمارية تخبرك أن وضع الذكاء الاصطناعي لا يعثر على المحتوى عبر إشارات الترتيب الكلاسيكية. إنه يعثر على المحتوى عبر خط استرجاع مختلف تمامًا — وقد تكون استراتيجيات التحسين التي أوصلتك إلى الصفحة الأولى غير ذات صلة إلى حد كبير بما إذا كان سيتم الاستشهاد بك أصلًا.
الوجود في الصفحة الأولى من Google ضروري للظهور في AI Overview؛ أما في وضع الذكاء الاصطناعي فهو غير ذي صلة إلى حد كبير.
العلاقة بين النظامين تشبه العلاقة بين مكتبة ومساعد بحث. كلاهما يتعامل مع الكتب. أحدهما يعطيك رفًا مرتبًا. والآخر يقرأ الكتب نيابةً عنك، ويُركّب الإجابة، ويقرر أي المقاطع تستحق الاستشهاد. وظيفتك تختلف جذريًا بحسب النظام الذي تُحسّن له — والآن، معظم الفرق تُحسّن للرف بينما مساعد البحث هو ما يستخدمه جمهورها.
الخلاصة الرئيسية: يشترك وضع الذكاء الاصطناعي في العلامة مع بحث Google وفي عنوان URL مع AI Overviews، لكنه نظام استرجاع مختلف بنيويًا. فقط 14 % من استشهادات وضع الذكاء الاصطناعي تأتي من أفضل 10 نتائج تقليدية — مقارنة بـ 76 % لـ AI Overviews. التعامل مع وضع الذكاء الاصطناعي كامتداد لـ AIO خطأ قياس له تبعات استراتيجية حقيقية.
البنية: كيف يتحول الاستعلام إلى إجابة
تصف معظم شروحات وضع الذكاء الاصطناعي ما يفعله من الخارج: «يفهم استعلامك بشكل أفضل»، «يُركّب مصادر متعددة»، «يوفر إجابات حوارية». هذه الأوصاف ليست خاطئة. لكنها عديمة الفائدة للتحسين.
ما يلي هو خط الأنابيب الكامل، مُسمّى مكوّنًا بمكوّن، مع براءات الاختراع التي تحكم كل مرحلة. هذا ما يعنيه التحسين فعليًا لاستهدافه — لأنك لا تستطيع تحسين نظام بشكل منهجي إذا لم تستطع تسميته.
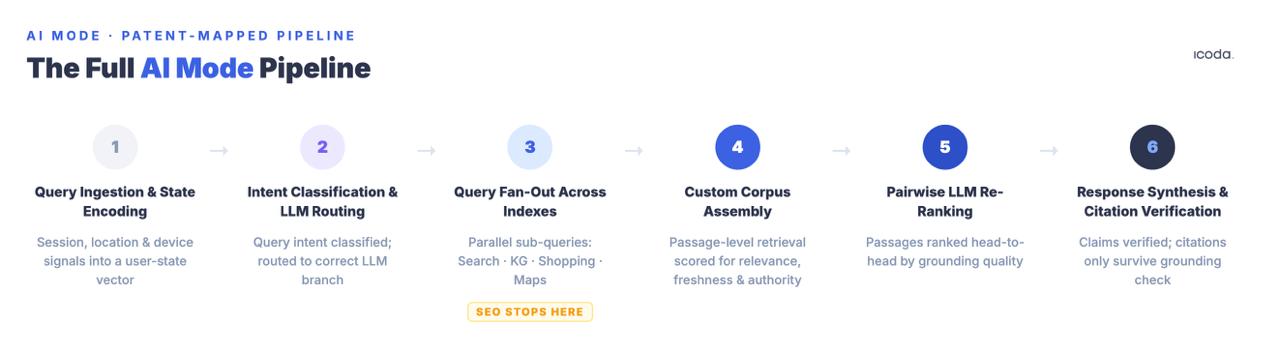
خط الأنابيب ذي المراحل الست هو ما تُحسّن له فعليًا. معظم الممارسات الحالية تعالج مرحلة واحدة.
المرحلة 1: إدخال الاستعلام وترميز حالة المستخدم
لا يدخل الاستعلام الخام إلى الاسترجاع مباشرة. بل يُقرن أولًا بمتجه سياق المستخدم الحالّي — تضمين كثيف مبني من سجل الجلسة، والاستعلامات السابقة عبر جميع الجلسات، والجهاز، والموقع، ووقت اليوم، وإشارات منظومة Google (Search وMaps وGmail وYouTube). يعدّل متجه التخصيص هذا معنى «ما الذي يعنيه هذا الاستعلام» قبل بدء أي استرجاع.
مستخدمان يكتبان الاستعلام نفسه فعليًا يرسلان تعليمات استرجاع مختلفة. وتداعيات ذلك كبيرة بما يكفي لتستحق قسمًا خاصًا — يأتي مباشرة بعد هذا القسم.
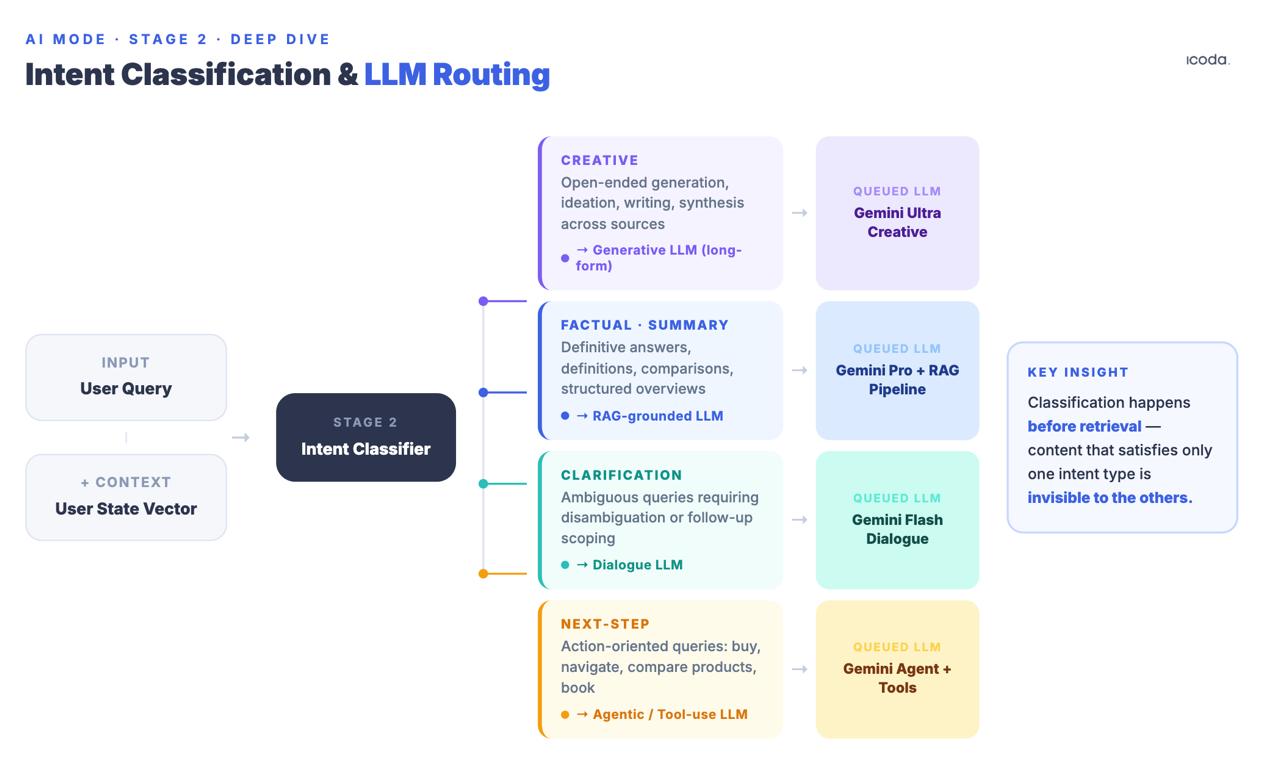
المرحلة 2: تصنيف نية الاستعلام وتوجيه LLM
قبل الاسترجاع، يصنّف النظام الاستعلام ضمن فئات نية: إبداعي، أو واقعي/ملخص، أو توضيح، أو خطوة تالية/مهمة. وبناءً على هذا التصنيف، تُصفّ نماذج لغوية مختلفة لاحقًا. وتذكر براءة الدردشة الحالّية (US20240289407A1) أسماءها صراحة: Creative Text LLM و SRP Generative LLM و Clarification LLM و Next Step LLM.
يحدث هذا قبل الاسترجاع. يحدد التصنيف ليس فقط أي نموذج يركّب الاستجابة، بل أيضًا أي إشارات استرجاع هي الأهم. قد لا تدخل صفحة تتصدر للاستعلامات المعلوماتية ضمن مجموعة المرشحين أصلًا إذا وجّه مصنف النية هذه الجلسة إلى Next Step LLM الذي يُحسّن لإتمام المهمة بدل تركيب المعلومات.
المرحلة 3: تشعب الاستعلام
هنا ينحرف وضع الذكاء الاصطناعي بأكبر قدر عن كل نظام سبقه.
يولّد النظام عدة استعلامات فرعية اصطناعية من الأصل، تغطي ثمانية أنواع موثقة من المتغيرات: مكافئ، مرتبط، ضمني، مقارن، توضيحي، زمني، جغرافي، وسياق مهني. لاحظ تاريخ الإيداع. تبني Google تشعب الاستعلامات المتعددة منذ سبع سنوات. وضع الذكاء الاصطناعي هو المنتج الاستهلاكي لمسار معماري طويل.
يستحق نوعا المتغيرات «الضمني» و«المقارن» اهتمامًا خاصًا لأنهما يولّدان استعلامات لم يسأل عنها المستخدم لكنه غالبًا سيحتاجها. إذا بحث شخص عن «أفضل CRM للشركات الناشئة»، فإن التشعب لا يولّد فقط إعادة صياغة، بل استعلامات ضمنية («ما CRM الذي يتوسع بعد Series A؟»)، واستعلامات مقارنة («Salesforce مقابل HubSpot للشركات في المراحل المبكرة»)، واستعلامات زمنية («تغييرات تسعير CRM 2025»)، ومتغيرات سياق مهني تميّز بين مؤسس يبحث ومدير RevOps يقرر.
تُطلق جميع الاستعلامات الفرعية بالتزامن عبر فهرس بحث Google وKnowledge Graph وShopping Graph وMaps. وقد أكدت Google أن وضع الذكاء الاصطناعي يمكنه إجراء «مئات عمليات البحث» لاستعلام معقد واحد. وتنظم براءة Thematic Search (US12158907B1) النتائج في عناقيد دلالية؛ وتطلق الموضوعات الفرعية جولات استرجاع إضافية تكراريًا — ما يعني أن التشعب يمكن أن يتكرر، لا أن ينفجر مرة واحدة فقط.
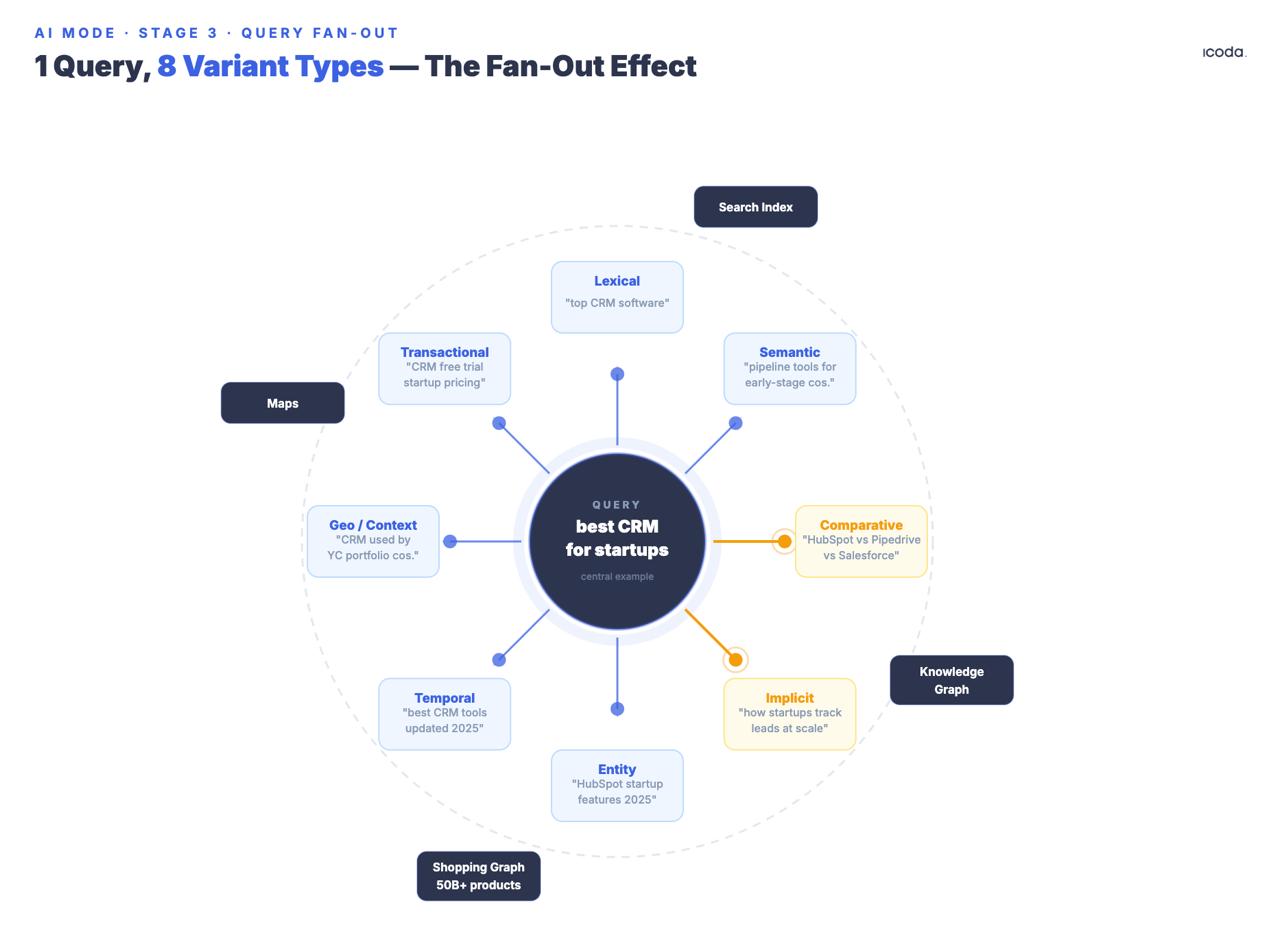
قدمت Google براءة الاختراع التأسيسية للتشعب في 2018 — ووضع الذكاء الاصطناعي هو المنتج الاستهلاكي لبناء معماري استمر سبع سنوات.
علامة تجارية لديها محتوى موثوق حول «أفضل CRM» لكنها لا تملك شيئًا مقارنًا، ولا شيئًا زمنيًا، ولا شيئًا يستهدف متغيرات السياق المهني، ستكون غائبة عن عدة أنواع من الاستعلامات التي تُطلق في كل جلسة ذات صلة. التشعب لا يهتم بسلطة نطاقك — بل يهتم بما إذا كان كل استعلام فرعي متغير يُظهر مقطعًا يفوز في المقارنة الثنائية.
المرحلة 4: تجميع مجموعة مخصصة
تُجمع المقاطع المسترجعة — لا المستندات، بل المقاطع — في مجموعة مخصصة. وتصف براءة WO2024064249A1 كيف قد يسترجع النظام ما يصل إلى خمس كتل متجاورة حول مقطع ذي صلة للحفاظ على تماسك السياق. هذا يعني أن تدفق النثر عبر قسم من المستند مهم. حجة جيدة البنية تكسب ضربة استرجاع تسحب الفقرات المحيطة معها إلى المجموعة.
المجموعة مخصصة. كل مستخدم، وكل جلسة، وكل استعلام ينتج مجموعة مختلفة. لا توجد مجموعة مستندات عالمية يتنافس محتواك داخلها — بل ملايين المجموعات الخاصة بالمستخدمين تُجمع عند الطلب.
المرحلة 5: إعادة ترتيب LLM بالمقارنة الثنائية
تتنافس المقاطع عبر جميع الاستعلامات الفرعية المتشعبة بعضها مع بعض. آلية الترتيب ليست BM25. وليست TF-IDF. يقارن LLM المقاطع في أزواج — أي مقطع يلبّي استعلامًا فرعيًا معينًا بشكل أفضل؟ — عبر عدة جولات مقارنة. يتقدم الفائزون؛ ويخرج الخاسرون.
هذه المرحلة هي حيث يفشل معظم استثمار SEO الحالي في تحقيق تماس. المقاطع الكثيفة، المباشرة، والواقعية التي تجيب عن أسئلة فرعية محددة في الجملة الأولى بوضوح تفوز في المقارنات الثنائية. أما المحتوى السردي، والاستطرادي، والمثقل بالآراء — وهو النوع الذي ينجح في SEO التحريري طويل الشكل — فيميل إلى الخسارة، لأنه يجعل LLM يعمل أكثر لاستخراج الادعاء ذي الصلة. قد يتفوق موضوع في Reddit يبدأ بإجابة مباشرة لسؤال متخصص على دليل موثوق من 3,000 كلمة يدفن الإجابة في الفقرة الثامنة. تكافئ الآلية الثنائية العائد الفوري، لا المصداقية المتراكمة.
المرحلة 6: تركيب الاستجابة والتحقق من الاستشهادات
تُغذّى المقاطع الناجية إلى Gemini. يولّد Gemini استجابة بلغة طبيعية. ثم يجري Response Linkifying Engine تحققًا على مستوى الشذرات: يطابق كل شذرة من الاستجابة المولدة مع مقاطع محددة من المجموعة ويضمّن الاستشهادات ضمن النص.
هذا ليس إسنادًا على مستوى الصفحة. جملة في الاستجابة تطابق مقطعًا على مدونتك تكسب استشهادًا. وقد لا يُشار إلى بقية صفحتك إطلاقًا. يمكن لمقال كثيف الحقائق من 400 كلمة أن يتفوق في الاستشهادات على دليل موثوق من 3,000 كلمة — لأنه ينتج شذرات قابلة للتحقق أكثر لكل وحدة نص. تكافئ الآلية بنيويًا كثافة الادعاءات على حساب التغطية الشاملة. وهذا انقلاب مباشر لما يُحسّن له SEO التقليدي طويل الشكل.
الخلاصة الرئيسية: وضع الذكاء الاصطناعي خط أنابيب من ست مراحل. يعالج SEO التقليدي أساسًا المرحلة 3 (أهلية الاسترجاع). أما الاستشهاد فيُكسب أو يُخسر في المراحل 4–6 — كثافة المقاطع على مستوى الفقرة، ومنافسة LLM بالمقارنة الثنائية، والتأسيس الواقعي على مستوى الشذرات — ولا يعالج أيًا منها التحسين القياسي.
طبقة التخصيص: لماذا يتتبع تتبع الترتيب خيالًا
هناك حقيقة مضمنة في بنية وضع الذكاء الاصطناعي لم تتعامل معها صناعة SEO بالكامل بعد. لنقلها بوضوح:
الاستعلام نفسه عند إصداره من مستخدمين مختلفين ينتج مجموعات استرجاع مختلفة. ليس ترتيبات مختلفة للمستندات نفسها. بل مستندات مختلفة بالكامل.
تصف براءة User Embedding Models كيف ترمز Google إشارات السلوك — الاستعلامات، والنقرات، ومدة البقاء، وسجل المواقع، ونشاط Maps، وسجل مشاهدة YouTube، ومحتوى Gmail — إلى متجهات كثيفة تُقرن بكل استعلام وارد. يعدّل متجه التخصيص الاسترجاع قبل تطبيق أي إشارة ترتيب تقليدية.
أنت لست في سباق ضد المنافسين على موضع عالمي مُرتّب. أنت في سباق على الملاءمة ضمن سياقات استعلامات مرتبطة بشخصيات مستخدم محددة لا يمكنك ملاحظتها مباشرة، ولا قياسها مباشرة، ولا تكرارها في أداة تتبع الترتيب.
ما الذي يغذي تضمين المستخدم
تصف براءة الدردشة الحالّية (US20240289407A1) وبراءة User Embedding Models معًا طبقة تخصيص تستمد من:
- سجل الاستعلامات الكامل عبر جميع جلسات بحث Google (للمستخدمين المسجلين)
- أنماط النقر والتمرير ومدة البقاء على نطاق سلوكي تجميعي
- إشارات نوع الجهاز والموقع
- بيانات منظومة Google: تسجيلات الوصول في Maps، ووقت مشاهدة YouTube حسب الموضوع، ومحتوى Gmail
تستحق الفئة الأخيرة التوقف عندها. ميزة «السياق الشخصي» — التي عُرضت في Google I/O 2025 وفي نشر جزئي حتى أوائل 2026 — ستدمج Gmail وCalendar وبيانات حساب Google مباشرة في الاسترجاع بشكل صريح. عند إطلاقها بالكامل، سيحصل مستخدم أرسل بريدًا عن رحلات تزلج الأسبوع الماضي على ردود مختلفة من وضع الذكاء الاصطناعي لاستعلام «معدات شتوية خارجية» مقارنةً بشخص اشترى مؤخرًا أحذية جري عبر Google Shopping. سيصبح مفهوم نتيجة بحث معيارية لأي استعلام ميتًا وظيفيًا. كل نتيجة ستكون نتاج سجل سلوك المستخدم عبر منظومة Google كاملة — لا مجرد استعلامات بحثه.
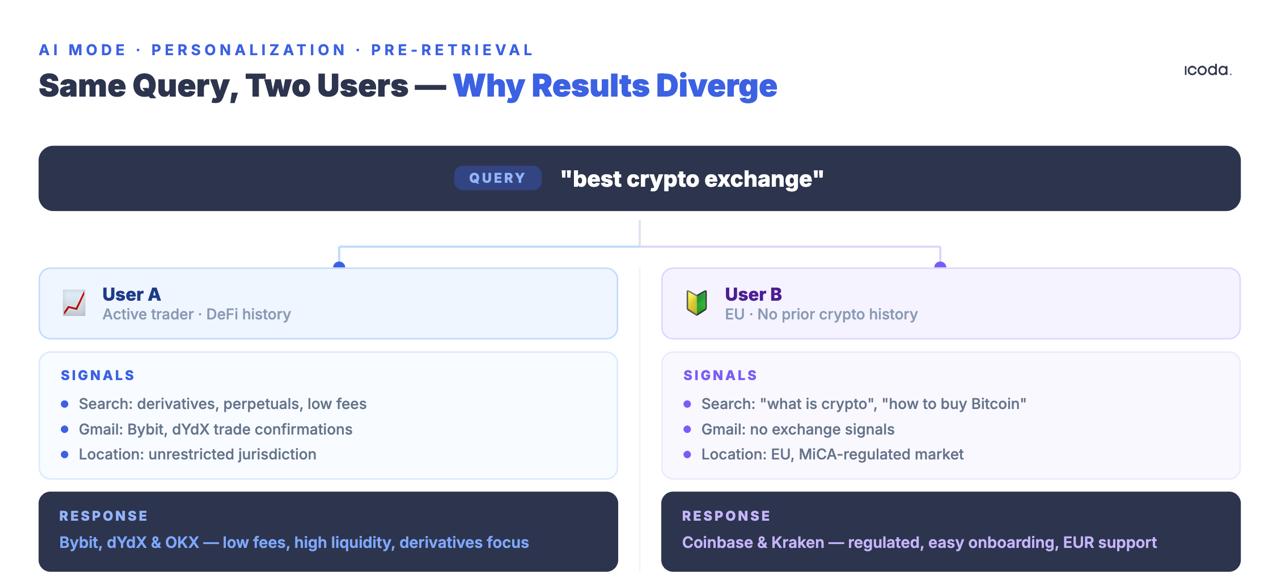
أثر ذلك على القياس
تستعلم أدوات تتبع الترتيب من بيئات معقمة بلا سياق. أما المستخدمون الحقيقيون فمُحمّلون بسياق عميق. الأداة تقيس موضعًا افتراضيًا لا يراه أي مستخدم حقيقي.
هذه ليست شكوى دقة. إنها شكوى صلاحية. القياس ليس غير دقيق — بل يقيس الشيء الخطأ بالكامل. رقم تتبع الموضع من أداة تتبع تعمل على وضع الذكاء الاصطناعي يمثل تجربة مستخدم بلا سجل بحث، وبلا إشارة موقع، وبلا بيانات منظومة، وبلا سياق جلسة. هذا المستخدم لا وجود له بأي حجم ذي معنى.
يُبرز حكم مكافحة الاحتكار هذه النقطة بطريقة ساخرة. علاج ديسمبر 2025 يفرض على Google مشاركة فهرس البحث مع المنافسين مرتين خلال خمس سنوات. لكنه لا يستطيع مشاركة نماذج تضمين المستخدم. بيانات الفهرس — التي أصبحت سلعة — ليست ما يقود تخصيص وضع الذكاء الاصطناعي. ما يقوده هو دولاب التعلم: 14 مليار استعلام يوميًا، تغذي باستمرار تضمينات مستخدم محدثة لا يستطيع أي منافس تكرارها. يحصل المنافسون على لقطة من الرف. وتحتفظ Google بأمين المكتبة الذي قرأ وجوه كل روادها.
ما الذي ينجح فعلاً في القياس
العلامات التجارية الأفضل تموضعًا للتعامل مع هذا ليست تلك التي تمتلك أعلى دقة في تتبع الترتيب. بل تلك التي تقبلت أن الاسترجاع بالذكاء الاصطناعي المُخصص يتطلب نموذج قياس مختلفًا وبنت نحوه. المؤشرات البديلة الأربعة ذات الإشارة الحقيقية:
حصة صوت العلامة التجارية في ردود الذكاء الاصطناعي، تُتبع عبر أدوات طرف ثالث (Profound وZipTie وAhrefs Brand Radar). تقديرات قائمة على أخذ عينات، لا تغطية كاملة — لكنها تقيس حضور الاستشهادات، وهو متغير المخرجات الصحيح. تتبع ذلك مقابل المنافسين، لا مقابل درجة مطلقة.
فك الارتباط بين مرات الظهور/النقرات في GSC على مستوى شريحة الاستعلام. الاستعلامات المعلوماتية التي تُظهر ارتفاعًا في مرات الظهور مع انخفاض CTR هي البصمة المرئية الأساسية لافتراس وضع الذكاء الاصطناعي. قسّم حسب نوع النية؛ وراقب اتساع التباعد بمرور الوقت.
تدقيقات يدوية لاستشهادات وضع الذكاء الاصطناعي لأهم 20 استعلامًا تجاريًا لديك. لاحظ أي الصفحات يُستشهد بها، وأي المقاطع تظهر في الاستجابة، وما إذا كانت علامتك تظهر في استعلامات التشعب الفرعية المتمحورة حول المنافسين — لأنها تظهر أحيانًا. يولّد وضع الذكاء الاصطناعي في المتوسط 3.3 ذكرًا للكيانات لكل استجابة مقابل 1.3 لـ AI Overviews. قد تكون علامتك حاضرة في جلسات لا يُنقر فيها على نطاقك مطلقًا.
حجم البحث عن العلامة التجارية كإشارة لاحقة. إذا كان وضع الذكاء الاصطناعي يولّد وعيًا بالعلامة دون دفع نقرات مباشرة — كما توحي البنية بأنه يفعل ذلك بشكل متزايد — فينبغي أن يتحرك حجم البحث عن العلامة كمؤشر متأخر ضمن نافذة 60–90 يومًا.
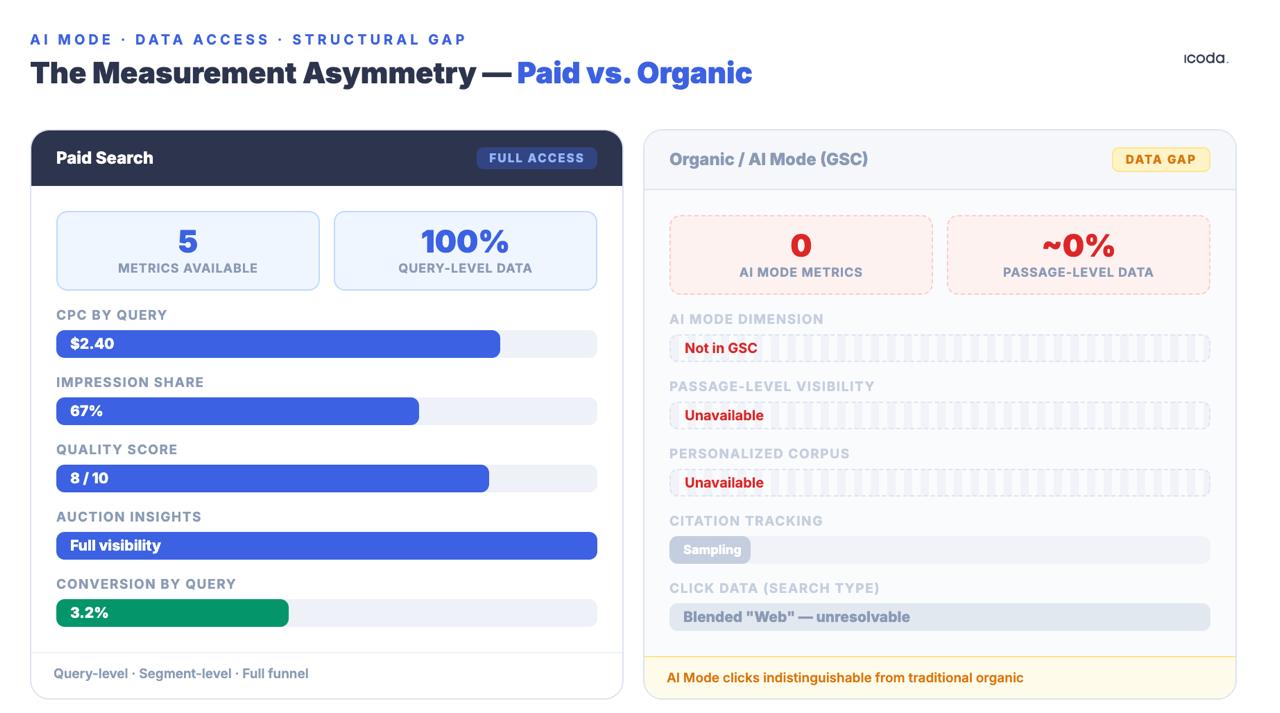
فجوة القياس بين البحث المدفوع والبحث العضوي موجودة منذ سنوات. وقد وسّعها وضع الذكاء الاصطناعي إلى هوة بنيوية.
لا شيء من ذلك مثالي. عدم التماثل مع فرق البحث المدفوع بنيوي ومهم: لدى الفرق المدفوعة بيانات CPC وحصة مرات الظهور ودرجات الجودة ورؤى المزاد على مستوى الاستعلام. أما الفرق العضوية فتحصل على بيانات GSC مُجمّعة عمدًا، ومأخوذة عينات، ومجهولة الهوية — كما تُخلط نقرات وضع الذكاء الاصطناعي ضمن نوع البحث العام «Web»، بحيث لا يمكن تمييزها عن الزيارات العضوية التقليدية. هذه الفجوة ليست مشكلة أدوات مؤقتة. إنها قرار معماري متعمد في المنتج، وهي تتسع مع جعل وضع الذكاء الاصطناعي الاسترجاع العضوي أكثر غموضًا لا أقل.
الإجابة الصادقة هي أنك لا تستطيع حاليًا قياس ظهورك في وضع الذكاء الاصطناعي بدقة. يمكنك قياس مؤشرات بديلة. يمكنك تتبع حضور العلامة. يمكنك مراقبة تدهور نسبة مرات الظهور/النقرات في الوقت الفعلي واستخدامها لتحديد الأولويات. لكن لا تخلط بين القياس بالوكالة والحقيقة على الأرض — وتوقف عن الادعاء بأن أداة تتبع ترتيب موجهة إلى استعلام بلا سياق تخبرك بأي شيء ذي معنى عن كيفية تجربة مستخدم حقيقي، مسجل الدخول، ومُحمّل بالسياق لمحتواك داخل وضع الذكاء الاصطناعي.
الخلاصة الرئيسية: تعدّل متجهات تضمين المستخدم استرجاع وضع الذكاء الاصطناعي قبل تطبيق إشارات الترتيب الكلاسيكية، ما يجعل تتبع الترتيب — كما يُمارس حاليًا — قياسًا لمستخدم غير موجود. انقل القياس الأساسي من الموضع إلى حصة صوت العلامة في ردود الذكاء الاصطناعي، مع دعم ذلك بإشارات فك الارتباط في GSC وتدقيقات الاستشهاد اليدوية.
الخاتمة
وضع الذكاء الاصطناعي ليس بحثًا كلاسيكيًا أذكى. إنه نظام استرجاع منفصل — ست مراحل، على مستوى المقاطع، مُخصص قبل تطبيق أي إشارة ترتيب — وهو يقرر بالفعل أي العلامات التجارية «موجودة» في الإجابات التي يقرأها جمهورك.
تداخل الاستشهاد بنسبة 14 % مع أفضل 10 نتائج تقليدية يخبرك بكل شيء: أصبح الترتيب والاستشهاد متغيرين مستقلين. يمكنك امتلاك الصفحة الأولى وأن تكون غير مرئي في وضع الذكاء الاصطناعي. ويمكنك أن تكون في الموضع 47 وتكسب استشهادات ثابتة إذا كان محتواك ينتج مقاطع تفوز في مقارنات LLM الثنائية للاستعلامات الفرعية المتغيرة الصحيحة.
البنية موثقة. وبراءات الاختراع عامة. ونافذة التكيف قبل أن يصبح وضع الذكاء الاصطناعي تجربة البحث الافتراضية تُقاس بالأرباع، لا بالسنوات.
ما سيحدث لاحقًا هو خيار.
شارك


قيم المقال












