Das Problem mit allem, was Sie bis jetzt gelesen haben
Die meisten Berichte über den KI-Modus fallen in eine von zwei Arten von Fehlern. Der erste ist atemloser Produktjournalismus, der Funktionen beschreibt, ohne die zugrunde liegende Maschine zu erklären. Die zweite sind beruhigende Aussagen von Praktikern, die Googles Argumente aufgesogen und weitergegeben haben - "Standard-SEO ist alles, was Sie brauchen", "Qualitätsinhalte gewinnen", "nichts hat sich grundlegend geändert".
Beides ist in einer Weise falsch, die die Marken Geld kosten wird.
Dieser Artikel geht hinter das Marketing zurück. Er basiert auf den Patentanmeldungen von Google, verifizierten quantitativen Studien und einigen Erkenntnissen, die von der breiteren Community auffallend wenig ernst genommen werden. Das Ziel ist einfach: Am Ende sollten Sie genau verstehen, wie AI Mode funktioniert, warum er mit der traditionellen SEO-Orthodoxie bricht und was Sie dagegen tun können.
Wir werden eine Menge Themen behandeln. Beginnen Sie mit dem Wichtigsten, was fast jeder falsch verstanden hat.
Was der KI-Modus wirklich ist (und was er nicht ist)
Hier ist der teuerste Irrglaube in Ihrer Branche: dass der KI-Modus eine intelligentere Version von etwas ist, das Sie bereits kennen.
Eigentlich ist es das nicht. Und die Vermischung mit vertrauten Systemen hat zu echten strategischen Fehlern geführt - Marken, die für die Sichtbarkeit von AI Overviews optimieren und davon ausgehen, dass sie übertragen wird, SEO-Teams, die das ChatGPT-Verhalten als Analogon zitieren, Praktiker, die den AI-Modus wie ein ausgefeilteres Featured Snippet behandeln. Dies sind Kategoriefehler. Sie führen zu falschen Investitionsentscheidungen und falschen Messrahmen.
Lassen Sie uns also bei der Taxonomie chirurgisch vorgehen.
Klassische Suche
Ein System zum Abrufen von Dokumenten. Sie geben eine Suchanfrage ein, und Google gibt eine Rangliste von URLs zurück. Die Arbeit von Google endet mit der SERP. Was Sie mit den blauen Links machen, ist Ihre Sache. Das Optimierungsspiel hier ist seit zwanzig Jahren stabil: signalisieren Sie dem Crawler Autorität, stimmen Sie die Suchbegriffe ab, verdienen Sie Engagement-Signale. Sie kennen dieses System.
KI Übersichten (AIO)
Eine generative Ebene, die auf die klassische Suche aufgesetzt wird. AIO nimmt die vorhandenen Suchergebnisse von Google und fasst sie in einem zusammenfassenden Absatz zusammen. Dabei werden fast ausschließlich Seiten verwendet, die bereits auf den vorderen Plätzen rangieren - 76,1 % der Zitate in AI Overview stammen aus den Top-10-Ergebnissen. Es handelt sich um eine UI-Funktion, nicht um ein neues Suchsystem. Stellen Sie sich das Ganze wie ein intelligentes Snippet vor, bei dem ein Sprachmodell den Text schreibt. Der darunter liegende Index ist unverändert, die darunter liegenden Ranking-Signale sind unverändert. Klassisches SEO, das gut angewandt wird, ist weitgehend ausreichend für die AIO-Förderung.
SGE (Generative Sucherfahrung)
Tot. Das Laborexperiment, das bis 2023-2024 lief. Hören Sie auf, es als lebendes System zu bezeichnen.
Zwillinge (Standalone)
Ein LLM-Assistent. Keine dauerhafte Verbindung zum Live-Suchindex von Google. Keine Knowledge Graph-Integration. Kein Shopping Graph. Seine Antworten stammen aus Trainingsdaten, nicht aus Echtzeitabfragen. Eine völlig andere Inferenzpipeline als alles andere auf dieser Liste.
Perplexity und ChatGPT Suche
Retrieval-augmented Generation (RAG) Systeme, die öffentliche Web-Indizes abrufen und Antworten synthetisieren. Perplexity verwendet einen Echtzeit-Crawl; ChatGPT holt den gesamten URL-Inhalt zur Laufzeit über die Bing-API ab. Ihre Abfrage ist vergleichsweise einfach - kein persistentes Benutzermodell, keine mehrschichtige Wissensinfrastruktur, kein zustandsabhängiger Kontext über Sitzungen hinweg.
AI-Modus
Keine der oben genannten Möglichkeiten.
AI Mode ist eine mehrstufige, zustandsabhängige, personalisierte Such- und Synthese-Engine auf Passagenebene, die mehrere parallele Unterabfragen an die gesamte Wissensinfrastruktur von Google - Suchindex, Knowledge Graph, Shopping Graph (50B+ Produkte) und Maps - stellt einen benutzerdefinierten Korpus von abgerufenen Passagen zusammen, ordnet sie mithilfe eines paarweisen LLM neu ein und generiert eine Antwort mit Zitationsprüfung auf Fragmentebene.
Es ist kein Wrapper für die klassische Suche. Es handelt sich um ein paralleles Suchsystem, das zufällig im selben Produkt enthalten ist. Und die Zahl, die Sie kalt lassen sollte:
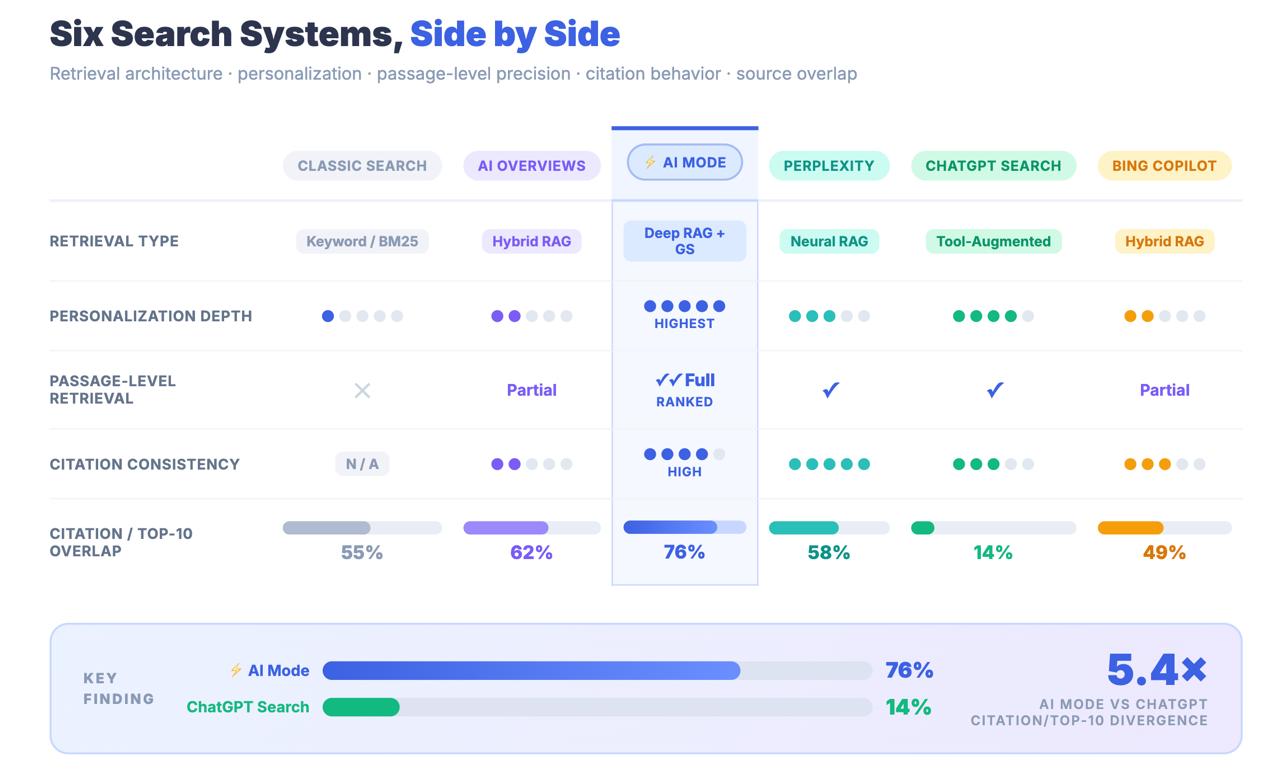
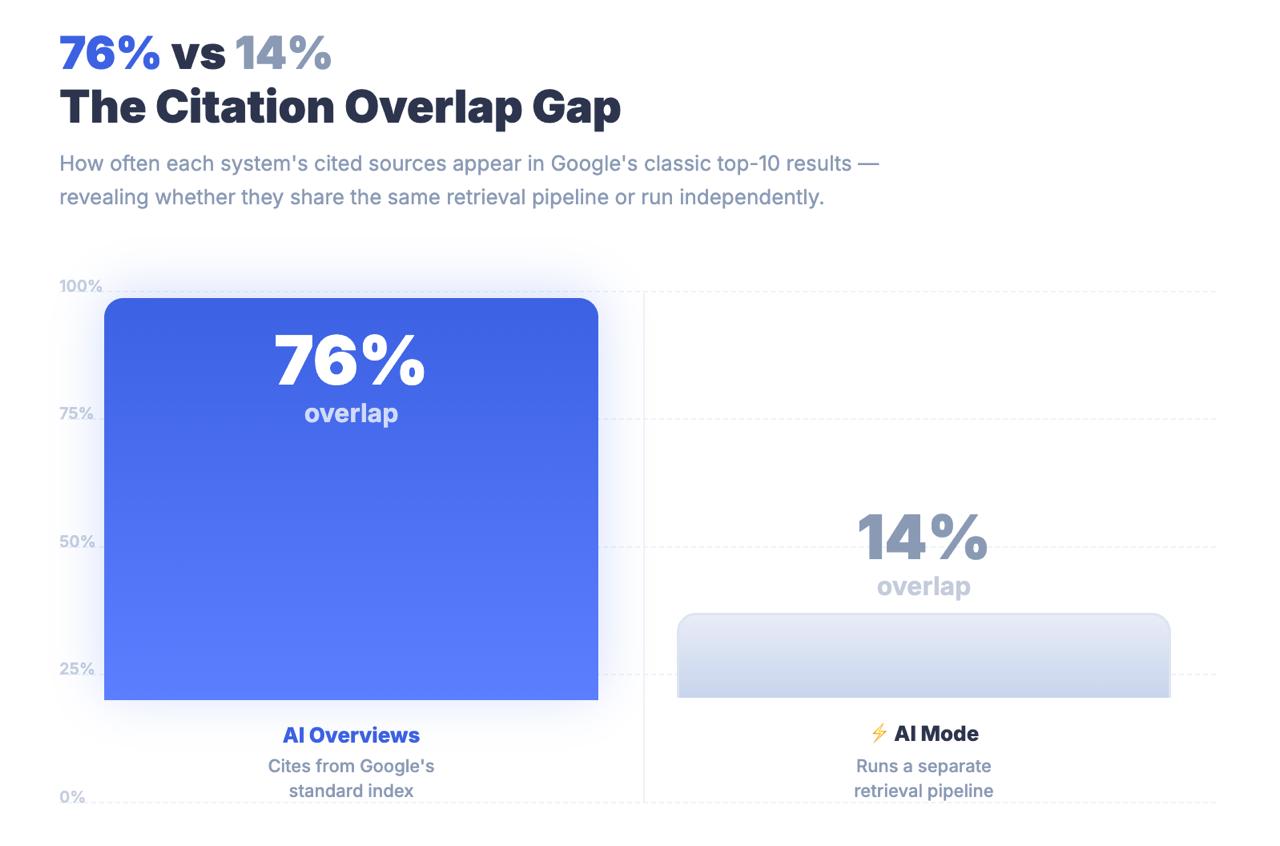
Nur 14% der von AI Mode zitierten URLs rangieren in den traditionellen Top 10 von Google.
Für AI Overviews liegt diese Zahl bei 76%. Der Unterschied zwischen diesen beiden Zahlen ist kein Rundungsfehler. Es handelt sich um eine architektonische Erkenntnis, die Ihnen sagt, dass der KI-Modus Inhalte nicht über klassische Ranking-Signale findet. Er findet Inhalte über eine völlig andere Suchpipeline - und die Optimierungsstrategien, die Sie auf die erste Seite gebracht haben, sind möglicherweise weitgehend irrelevant dafür, ob Sie überhaupt zitiert werden.
Für die Sichtbarkeit von AI Overview ist es notwendig, auf der ersten Seite von Google zu stehen; für AI Mode ist es weitgehend irrelevant.
Die Systeme sind so miteinander verwandt, wie eine Bibliothek und ein wissenschaftlicher Mitarbeiter miteinander verwandt sind. Beide handeln mit Büchern. Der eine übergibt Ihnen ein geordnetes Regal. Der andere liest die Bücher für Sie, fasst die Antwort zusammen und entscheidet, welche Passagen es wert sind, zitiert zu werden. Ihre Aufgabe unterscheidet sich grundlegend, je nachdem, wofür Sie optimieren - und im Moment optimieren die meisten Teams für das Regal, wenn der Rechercheassistent das ist, was ihr Publikum benutzt.
Das Wichtigste zum Schluss: AI Mode teilt sich eine Marke mit Google Search und eine URL mit AI Overviews, ist aber ein strukturell unterschiedliches Abfragesystem. Nur 14% der Zitate im AI Mode stammen aus den traditionellen Top-10-Ergebnissen - im Vergleich zu 76% für AI Overviews. AI Mode als eine AIO-Erweiterung zu behandeln, ist ein Messfehler mit echten strategischen Konsequenzen.
Die Architektur: Wie eine Anfrage zu einer Antwort wird
Die meisten Erklärungen zu KI Mode beschreiben, was sie von außen betrachtet tut: "sie versteht Ihre Anfrage besser", "sie synthetisiert mehrere Quellen", "sie liefert dialogorientierte Antworten". Diese Beschreibungen sind nicht falsch. Sie sind für die Optimierung nutzlos.
Im Folgenden finden Sie die gesamte Pipeline, Komponente für Komponente benannt, mit den Patenten, die für jede Stufe gelten. Das ist es, was Optimierung tatsächlich bedeutet - denn Sie können ein System, das Sie nicht benennen können, nicht systematisch verbessern.
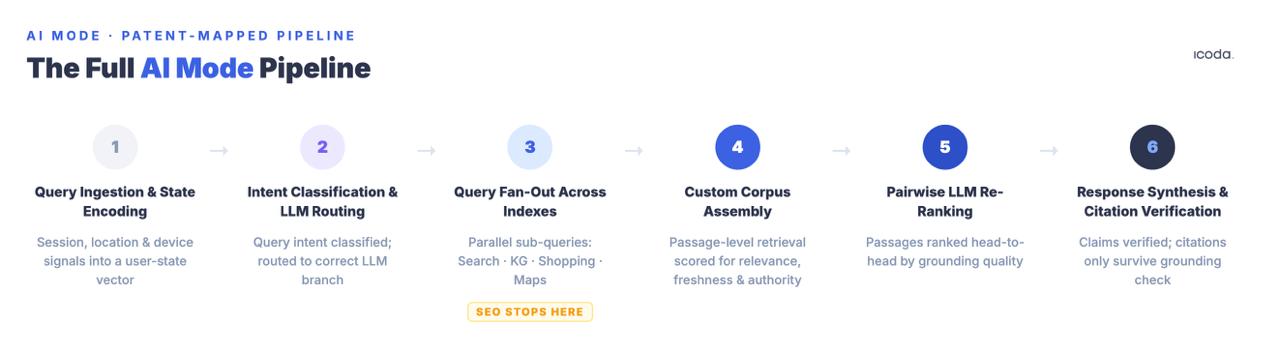
Die sechsstufige Pipeline ist das, wofür Sie eigentlich optimieren sollten. Die meisten aktuellen Verfahren befassen sich mit einer Stufe.
Stufe 1: Abfrage-Ingestion und Kodierung des Benutzerstatus
Die rohe Anfrage geht nicht direkt in den Abruf ein. Sie wird zunächst mit dem Kontextvektor des Nutzers gepaart - eine dichte Einbettung, die aus dem Sitzungsverlauf, früheren Abfragen in allen Sitzungen, dem Gerät, dem Standort, der Tageszeit und Signalen aus dem Google-Ökosystem (Suche, Maps, Gmail, YouTube) besteht. Dieser Personalisierungsvektor ändert, was "diese Anfrage bedeutet", bevor die Abfrage beginnt.
Zwei Benutzer, die identische Abfragen eingeben, erteilen effektiv unterschiedliche Abrufanweisungen. Die Auswirkungen dieser Tatsache sind so bedeutsam, dass sie einen eigenen Abschnitt verdienen - der unmittelbar nach diesem Abschnitt folgt.
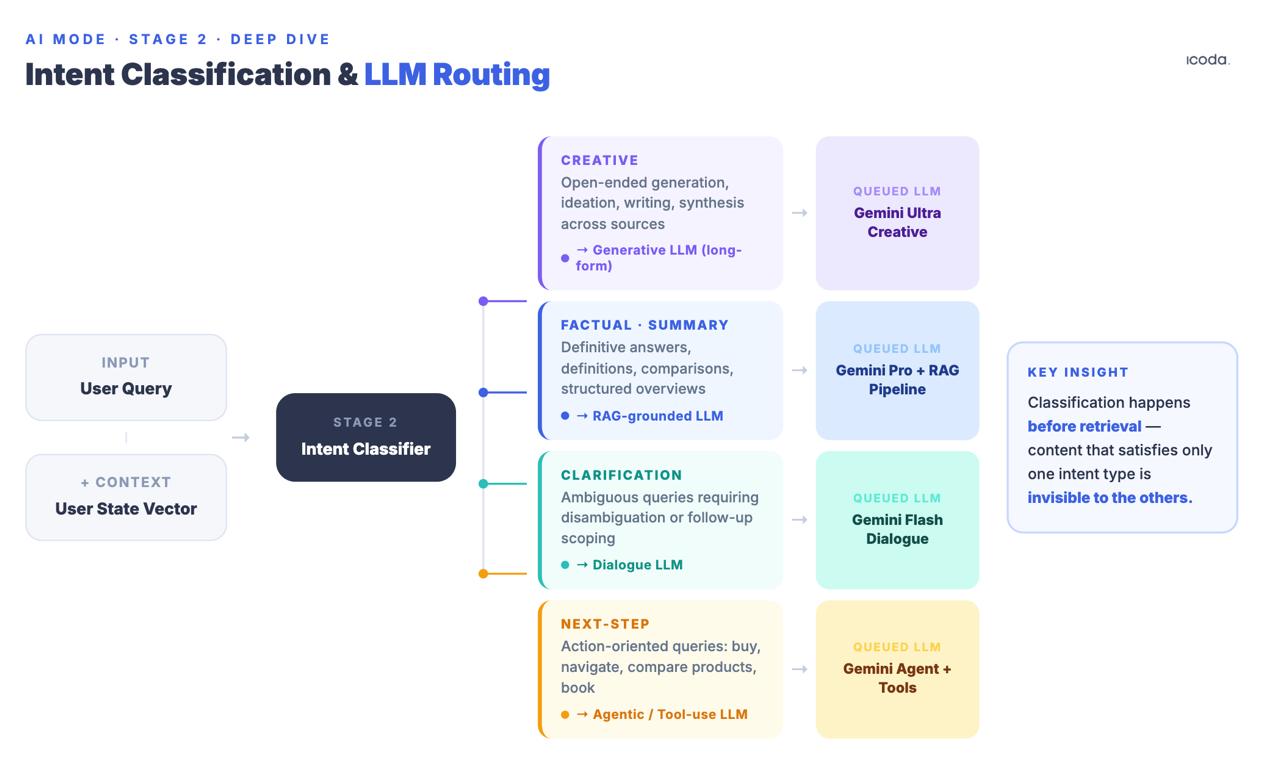
Stufe 2: Klassifizierung von Abfrageabsichten und LLM-Routing
Vor dem Abruf klassifiziert das System die Anfrage in Absichtskategorien: kreativ, sachlich/zusammenfassend, klärend oder nächster Schritt/Aufgabe. Auf der Grundlage dieser Klassifizierung werden verschiedene nachgeschaltete Sprachmodelle in eine Warteschlange gestellt. Im Stateful-Chat-Patent (US20240289407A1) werden diese ausdrücklich genannt: Kreativer Text LLM, SRP Generativer LLM, Klärung LLM, Nächster Schritt LLM.
Dies geschieht vor dem Abruf. Die Klassifizierung bestimmt nicht nur, welches Modell die Antwort synthetisiert, sondern auch, welche Abfragesignale am wichtigsten sind. Eine Seite, die bei Informationsanfragen gut abschneidet, kommt möglicherweise gar nicht in den Kandidatenpool, wenn der Intent-Klassifikator diese Sitzung an ein LLM der nächsten Stufe weiterleitet, das für die Aufgabenerfüllung und nicht für die Informationssynthese optimiert ist.
Stufe 3: Fan-Out abfragen
Hier unterscheidet sich der KI-Modus am deutlichsten von allen anderen Systemen, die vor ihm entwickelt wurden.
Das System generiert aus dem Original mehrere synthetische Unterabfragen, die acht dokumentierte Variantentypen abdecken: äquivalent, verwandt, implizit, vergleichend, klärend, zeitlich, geografisch und im beruflichen Kontext. Beachten Sie das Datum der Einreichung. Google entwickelt bereits seit sieben Jahren Multi-Abfrage-Fan-Outs. AI Mode ist das Endprodukt einer langen architektonischen Laufbahn.
Die Varianten "implizit" und "vergleichend" verdienen besondere Aufmerksamkeit, da sie Abfragen generieren, die der Nutzer nicht gestellt hat, die er aber wahrscheinlich braucht. Wenn jemand nach "bestes CRM für Startups" sucht, generiert der Fan-Out nicht nur Umformulierungen, sondern auch implizite Abfragen ("Welches CRM skaliert über die Serie A hinaus?"), vergleichende Abfragen ("Salesforce vs. HubSpot für Unternehmen in der Frühphase"), zeitliche Abfragen ("CRM-Preisänderungen 2025″) und Varianten mit beruflichem Kontext, die einen Gründer, der recherchiert, von einem RevOps-Manager, der entscheidet, unterscheiden.
Alle Unterabfragen werden gleichzeitig über den Google Suchindex, Knowledge Graph, Shopping Graph und Maps abgefeuert. Google hat bestätigt, dass AI Mode "Hunderte von Suchanfragen" für eine einzige komplexe Anfrage durchführen kann. Das Patent für die Thematische Suche (US12158907B1) organisiert die Ergebnisse in semantischen Clustern; Unterthemen lösen iterativ weitere Abfragerunden aus - was bedeutet, dass der Fan-Out rekursiv sein kann und nicht nur einmal ausbricht.
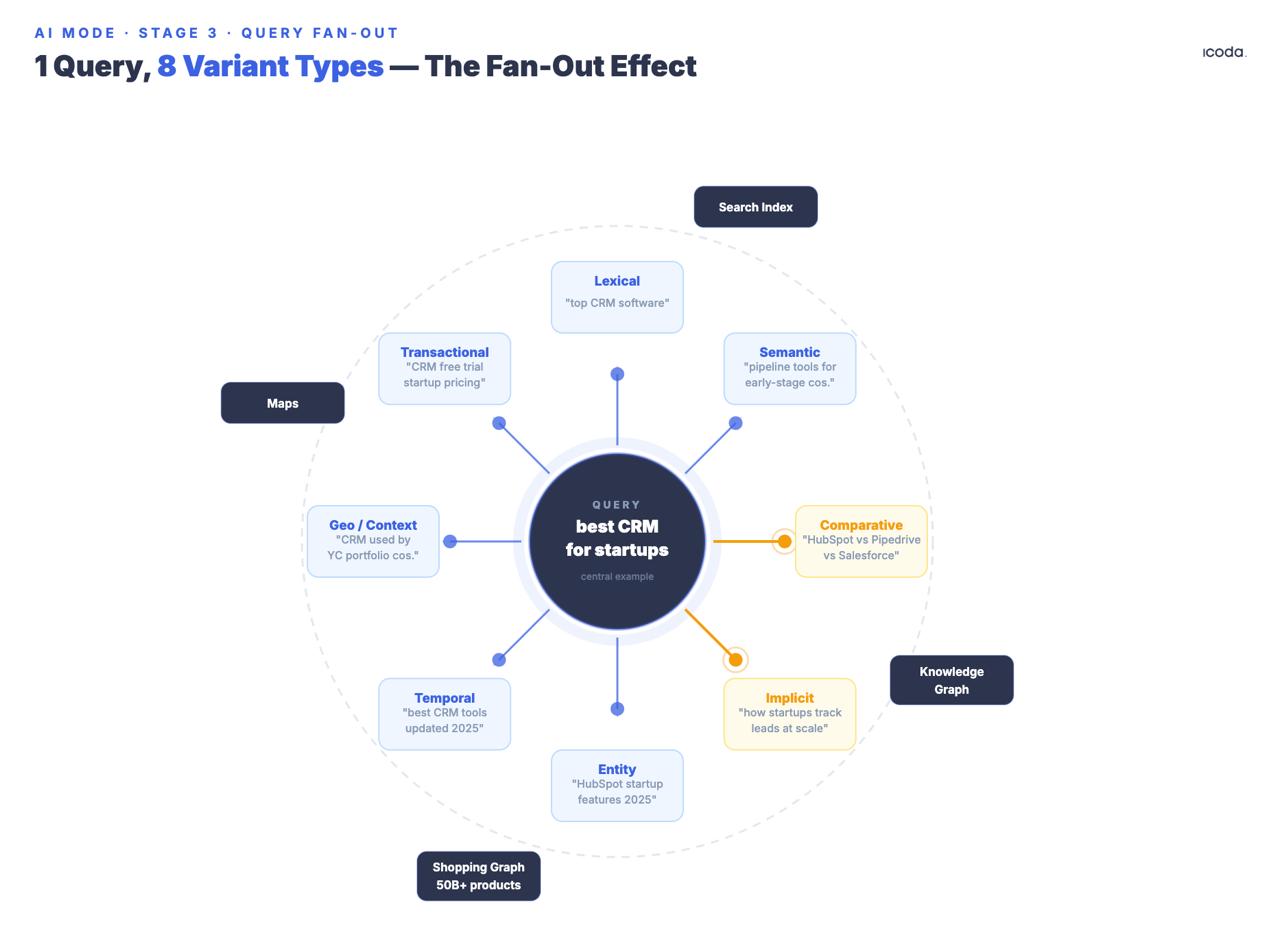
Google meldete das grundlegende Fan-Out-Patent 2018 an - der AI Mode ist das Endprodukt einer siebenjährigen Architekturentwicklung.
Eine Marke, die über maßgebliche Inhalte zum Thema "bestes CRM" verfügt, aber nichts Vergleichbares, nichts Zeitliches und nichts, das auf Varianten im professionellen Kontext abzielt, wird von mehreren Abfragetypen, die bei jeder relevanten Sitzung abgefeuert werden, nicht berücksichtigt. Der Fan-Out kümmert sich nicht um Ihre Domain-Autorität - er kümmert sich darum, ob bei jeder Unterabfrage eine Passage auftaucht, die den paarweisen Vergleich gewinnt.
Stufe 4: Benutzerdefinierte Korpusmontage
Die abgerufenen Passagen - keine Dokumente, sondern Passagen - werden zu einem benutzerdefinierten Korpus zusammengestellt. Das Patent WO2024064249A1 beschreibt, wie das System bis zu fünf benachbarte Abschnitte um eine relevante Passage herum abrufen kann, um die kontextuelle Kohärenz zu wahren. Das bedeutet, dass der Prosafluss in einem Dokumentabschnitt wichtig ist. Ein gut strukturiertes Argument, das einen Treffer bei der Suche erzielt, zieht die umliegenden Absätze mit in den Korpus.
Der Korpus ist individuell. Jeder Benutzer, jede Sitzung, jede Abfrage erzeugt einen anderen. Es gibt keinen universellen Dokumentenpool, in dem Ihre Inhalte miteinander konkurrieren - es gibt Millionen von benutzerspezifischen Pools, die bei Bedarf zusammengestellt werden.
Stufe 5: Paarweises LLM Re-Ranking
Passagen aus allen Fan-Out-Unterabfragen treten gegeneinander an. Der Ranking-Mechanismus ist nicht BM25. Es ist nicht TF-IDF. Ein LLM vergleicht Passagen paarweise - welche Passage erfüllt eine bestimmte Unterabfrage besser? - über mehrere Vergleichsrunden hinweg. Die Gewinner kommen weiter, die Verlierer scheiden aus.
In dieser Phase scheitern die meisten SEO-Investitionen derzeit. Dichte, direkte, sachliche Passagen, die spezifische Unterfragen im ersten Satz beantworten, gewinnen den paarweisen Vergleich klar. Erzählerische, diskursive, meinungslastige Inhalte - die Art, die bei redaktionellem SEO in langer Form gut abschneidet - verlieren in der Regel, weil sie einen LLM dazu zwingen, sich mehr Mühe zu geben, um die relevante Aussage zu extrahieren. Ein Reddit-Thread, der mit einer direkten Antwort auf eine Nischenfrage beginnt, kann einen 3.000 Wörter umfassenden Leitfaden, der die Antwort in Absatz acht versteckt, ausstechen. Der paarweise Mechanismus belohnt den sofortigen Gewinn, nicht die angesammelte Glaubwürdigkeit.
Stufe 6: Synthese der Antworten und Überprüfung der Zitate
Die überlebenden Passagen werden an Gemini weitergeleitet. Gemini generiert eine Antwort in natürlicher Sprache. Anschließend führt die Response Linkifying Engine eine Überprüfung auf Fragmentebene durch: Sie gleicht jedes Fragment der generierten Antwort mit bestimmten Korpuspassagen ab und bettet Zitate in die Zeile ein.
Es handelt sich dabei nicht um eine Attribution auf Seitenebene. Ein Satz in der Antwort, der mit einer Passage in Ihrem Blog übereinstimmt, verdient eine Quellenangabe. Der Rest Ihrer Seite wird möglicherweise gar nicht zitiert. Ein sachlich dichter Artikel mit 400 Wörtern kann einen maßgeblichen Leitfaden mit 3.000 Wörtern übertreffen - weil er mehr überprüfbare Fragmente pro Texteinheit enthält. Der Mechanismus belohnt strukturell die Behauptungsdichte gegenüber einer umfassenden Berichterstattung. Dies ist eine direkte Umkehrung dessen, worauf traditionelles SEO mit langen Texten optimiert ist.
Das Wichtigste zum Mitnehmen: Der KI-Modus ist eine sechsstufige Pipeline. Traditionelles SEO befasst sich in erster Linie mit Stufe 3 (Abrufbarkeit). Die Zitation wird in den Stufen 4-6 gewonnen oder verloren - Dichte auf Passagenebene, paarweiser LLM-Wettbewerb und faktische Fundierung auf Fragmentebene -, von denen keine von der Standardoptimierungspraxis angesprochen wird.
Die Personalisierungsebene: Warum Rank Tracking eine Fiktion ist
Es gibt eine Tatsache in der Architektur des AI Mode, mit der die SEO-Branche noch nicht ganz gerechnet hat. Lassen Sie es uns klar und deutlich sagen:
Dieselbe Abfrage von zwei verschiedenen Nutzern ergibt unterschiedliche Abfragesätze. Nicht etwa unterschiedliche Einstufungen derselben Dokumente. Völlig unterschiedliche Dokumente.
Das Patent User Embedding Models beschreibt, wie Google Verhaltenssignale - Suchanfragen, Klicks, Verweildauer, Standortverlauf, Maps-Aktivitäten, YouTube-Verlauf, Gmail-Inhalte - in dichte Vektoren kodiert, die mit jeder eingehenden Suchanfrage gepaart werden. Der Personalisierungsvektor verändert den Abruf , bevor ein herkömmliches Ranking-Signal angewendet wird.
Sie befinden sich nicht in einem Rennen gegen Konkurrenten um eine universelle Rangposition. Sie befinden sich in einem Wettlauf um Relevanz innerhalb bestimmter Benutzer-Persona-Abfragekontexte, die Sie nicht direkt beobachten, nicht direkt messen und nicht in einem Ranking-Tool replizieren können.
Was den Benutzer füttert Einbettung
Das Stateful-Chat-Patent (US20240289407A1) und das User Embedding Models-Patent beschreiben zusammen einen Personalisierungsstapel, der auf der Grundlage von:
- Vollständiger Abfrageverlauf über alle Google-Suchsitzungen (für angemeldete Nutzer)
- Klick-, Hover- und Verweilmuster auf aggregierter Verhaltensebene
- Gerätetyp und Ortsangaben
- Google Ökosystem-Daten: Maps-Check-Ins, YouTube-Sehdauer nach Thema, Gmail-Inhalte
Diese letzte Kategorie ist es wert, näher betrachtet zu werden. Die Funktion "Personal Context" - die auf der Google I/O 2025 vorgestellt wurde und ab Anfang 2026 teilweise eingesetzt wird - wird explizit Gmail-, Kalender- und Google-Kontodaten direkt in die Abfrage einbeziehen. Wenn die Funktion vollständig eingeführt ist, wird ein Nutzer, der letzte Woche eine E-Mail über Skireisen geschrieben hat, andere KI-Antworten auf "Outdoor-Winterausrüstung" erhalten als jemand, der kürzlich Laufschuhe bei Google Shopping gekauft hat. Das Konzept eines kanonischen Suchergebnisses für eine beliebige Abfrage wird funktionell tot sein. Jedes Ergebnis wird ein Produkt aus dem Verhalten des Nutzers im gesamten Google-Ökosystem sein - nicht nur bei seinen Suchanfragen.
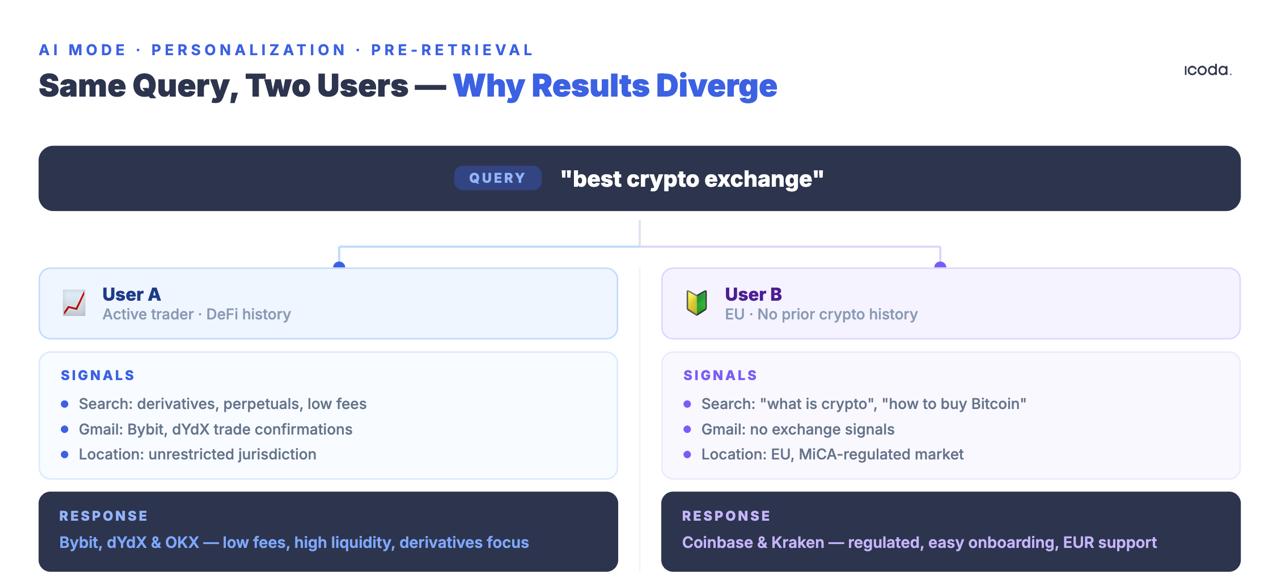
Die Messkonsequenz
Tools zur Ermittlung der Rangfolge stellen Abfragen in reinen, nicht kontextualisierten Umgebungen. Echte Benutzer sind stark kontextualisiert. Das Tool misst eine hypothetische Position, die kein echter Benutzer sieht.
Dies ist keine Beschwerde über die Genauigkeit. Es ist eine Beschwerde über die Gültigkeit. Die Messung ist nicht ungenau - sie misst das völlig Falsche. Eine Positionsverfolgungszahl von einem Rank Tracker, der gegen den KI-Modus läuft, repräsentiert die Erfahrung eines Nutzers ohne Suchverlauf, ohne Standortsignal, ohne Ökosystemdaten und ohne Sitzungskontext. Dieser Nutzer existiert nicht in einem sinnvollen Umfang.
Das Kartellurteil verschärft diesen Punkt auf ironische Art und Weise. Die Abhilfemaßnahme vom Dezember 2025 verlangt von Google, seinen Suchindex zweimal innerhalb von fünf Jahren mit Wettbewerbern zu teilen. Die Modelle zur Einbettung der Nutzer kann Google jedoch nicht teilen. Indexdaten - die jetzt zu einer Ware werden - sind nicht das, was die Personalisierung des KI-Modus antreibt. Es ist das Schwungrad des Lernens: 14 Milliarden tägliche Suchanfragen, die kontinuierlich aktualisierte Benutzereinbettungen liefern, die kein Konkurrent replizieren kann. Die Konkurrenten erhalten eine Momentaufnahme des Regals. Google behält den Bibliothekar, der das Gesicht eines jeden Kunden gelesen hat.
Was bei der Messung tatsächlich funktioniert
Die Marken, die am besten positioniert sind, um dies zu meistern, sind nicht diejenigen, die das beste Ranking-Tracking haben. Sie sind diejenigen, die akzeptiert haben, dass die personalisierte KI-Abfrage ein anderes Messparadigma erfordert und sich darauf eingestellt haben. Die vier Proxies, die ein echtes Signal haben:
Anteil der Marke an den KI-Antworten, der über Tools von Drittanbietern (Profound, ZipTie, Ahrefs Brand Radar) verfolgt wird. Es handelt sich dabei um stichprobenartige Annäherungen, nicht um eine vollständige Abdeckung - aber sie messen die Zitationspräsenz, was die richtige Ausgangsvariable ist. Verfolgen Sie dies im Vergleich zu Wettbewerbern, nicht im Vergleich zu einer absoluten Punktzahl.
GSC Entkopplung von Impression/Klick auf der Ebene des Abfragesegments. Informationsanfragen, die steigende Impressionen bei sinkender CTR aufweisen, sind die erste sichtbare Signatur der Kannibalisierung durch den KI-Modus. Segmentieren Sie nach Art der Absicht und beobachten Sie, wie sich die Divergenz mit der Zeit verstärkt.
Manuelle KI-Modus-Zitatprüfungen für Ihre 20 kommerziell wichtigsten Suchanfragen. Achten Sie darauf, welche Seiten zitiert werden, welche Passagen in der Antwort vorkommen und ob Ihre Marke in konkurrentenbezogenen Fan-Out-Unterabfragen auftaucht - denn das ist manchmal der Fall. Der AI-Modus generiert im Durchschnitt 3,3 Erwähnungen von Unternehmen pro Antwort, gegenüber 1,3 bei AI Overviews. Ihre Marke kann in Sitzungen vorkommen, in denen Ihre Domain nie angeklickt wird.
Markensuchvolumen als ein nachgelagertes Signal. Wenn der KI-Modus Markenbekanntheit generiert, ohne direkte Klicks zu generieren - worauf die Architektur hindeutet -, sollte sich das Volumen der Markensuche als nachlaufender Indikator über ein Zeitfenster von 60-90 Tagen bewegen.
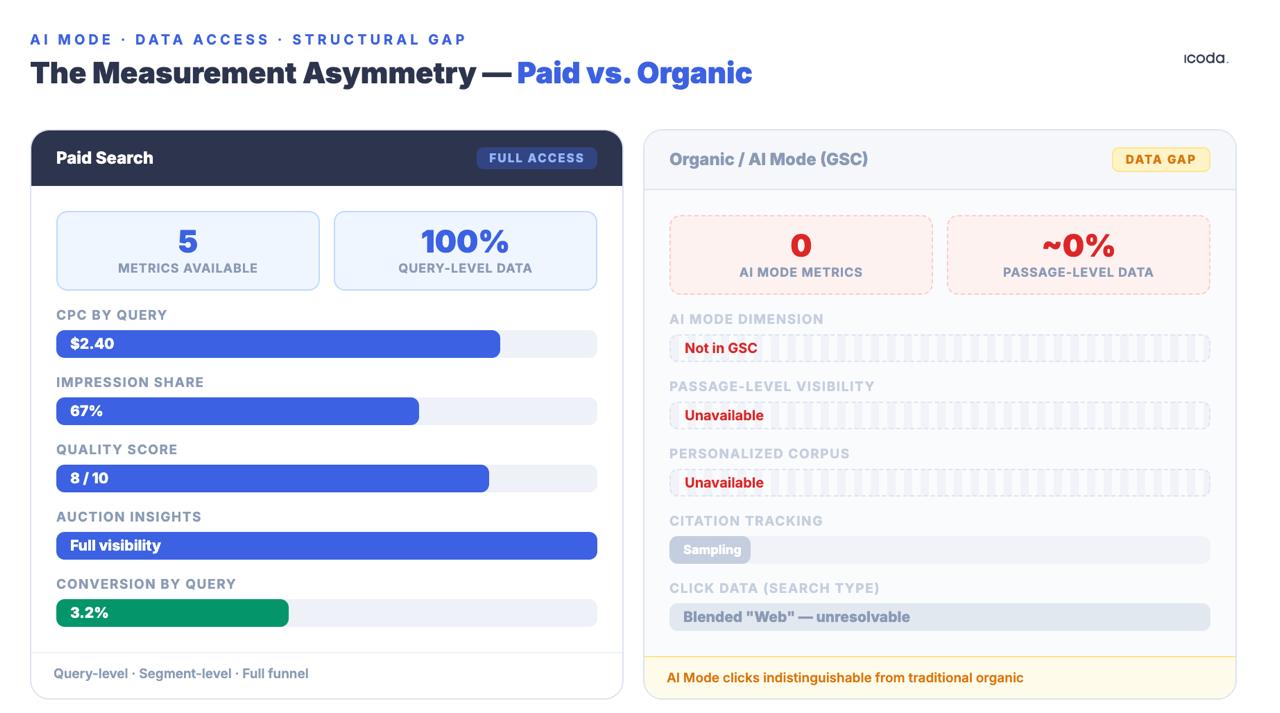
Die Messlücke zwischen bezahlter und organischer Suche besteht schon seit Jahren. Der KI-Modus hat sie zu einer strukturellen Kluft vergrößert.
Keines dieser Systeme ist perfekt. Die Asymmetrie mit den Teams der bezahlten Suche ist strukturell und signifikant: Die Teams der bezahlten Suche verfügen über CPC-Daten, Impression Share, Quality Scores und Auktionseinblicke auf Abfrageebene. Organische Teams erhalten GSC-Daten, die absichtlich aggregiert, stichprobenartig und anonymisiert sind - und AI Mode-Klicks werden in den generischen Suchtyp "Web" gemischt, der vom traditionellen organischen Traffic nicht zu unterscheiden ist. Diese Lücke ist kein vorübergehendes Tooling-Problem. Es handelt sich um eine bewusste Entscheidung der Produktarchitektur, und sie vergrößert sich, da AI Mode die organische Suche undurchsichtiger macht, nicht weniger.
Die ehrliche Antwort ist, dass Sie Ihre Sichtbarkeit im AI-Modus derzeit nicht genau messen können. Sie können Proxys messen. Sie können die Markenpräsenz verfolgen. Sie können beobachten, wie sich das Verhältnis zwischen Impressionen und Klicks in Echtzeit verschlechtert, und dies nutzen, um Prioritäten zu setzen. Aber Sie sollten die Proxy-Messung nicht mit Ground Truth verwechseln - und Sie sollten aufhören, so zu tun, als ob ein Rank Tracker, der auf eine unkontextualisierte Abfrage gerichtet ist, irgendetwas Aussagekräftiges darüber aussagt, wie ein echter, eingeloggter, kontextualisierter Nutzer Ihre Inhalte im KI-Modus erlebt.
Das Wichtigste zum Schluss: Vektoren zur Einbettung von Nutzern verändern die Abfrage von KI-Modi, bevor klassische Ranking-Signale zur Anwendung kommen. Dadurch wird das Ranking-Tracking - wie es derzeit praktiziert wird - zu einer Messung eines Nutzers, der gar nicht existiert. Verschieben Sie die primäre Messung von der Position zum Share-of-Voice der Marke in den KI-Antworten, ergänzt durch GSC-Entkopplungssignale und manuelle Zitationsprüfungen.
Fazit
Der KI-Modus ist keine intelligentere klassische Suche. Es handelt sich um ein separates Abfragesystem - sechs Stufen, auf Passagenebene, personalisiert, bevor ein Ranking-Signal angewendet wird - und es entscheidet bereits, welche Marken in den Antworten vorkommen, die Ihr Publikum liest.
Die 14%ige Überschneidung mit den traditionellen Top-10-Ergebnissen sagt Ihnen alles: Ranking und Zitierung sind jetzt unabhängige Variablen. Sie können auf Seite eins stehen und im KI-Modus unsichtbar sein. Sie können auf Position 47 sitzen und konsistente Zitate erhalten, wenn Ihr Inhalt Passagen enthält, die paarweise LLM-Vergleiche für die richtigen Unterabfragevarianten gewinnen.
Die Architektur ist dokumentiert. Die Patente sind öffentlich. Das Zeitfenster für die Anpassung, bevor der KI-Modus zum Standard für die Suche wird, wird in Quartalen gemessen, nicht in Jahren.
Was als nächstes passiert, ist eine Entscheidung.
Teilen Sie


Den Artikel bewerten












