あなたがこれまで読んできたすべての問題点
ほとんどのAIモード報道は、2つの失敗モードのいずれかに分類される。1つ目は、基礎となるマシンを説明することなく機能を説明する、息を呑むような製品ジャーナリズムである。もうひとつは、グーグルの論点を吸収し、それを伝えてきた実務家による安心させるような受け売りだ。「標準的なSEOがすべて」「質の高いコンテンツが勝つ」「根本的には何も変わっていない」。
どちらもブランドにとって損になる方法で間違っている。
この記事はマーケティングの根底にあるものだ。グーグルの特許申請、検証された定量的研究、そして、より広いコミュニティが目立って真剣に受け止めてこなかったいくつかの発見を基に構成されている。ゴールはシンプルである。最後まで読めば、AIモードがどのように機能するのか、なぜそれが従来のSEOの正統性を破るのか、そして、それに対して何をすべきなのかを正確に理解できるはずだ。
私たちは多くの分野をカバーするつもりだ。ほとんどの人が間違えている、最も重要なことから始めよう。
AIモードとは何か?
今、あなたの業界で最も高価な誤解がここにある:AIモードは、あなたがすでに知っている何かをより賢くしたものだ。
実はそうではない。ブランドはAIオーバービューの可視性を最適化し、それが転送されると仮定し、SEOチームはChatGPTの行動を類似として引用し、実務家はAIモードをより洗練されたFeatured Snippetのように扱う。これらは範疇の間違いである。これらは間違った投資決定と間違った測定フレームワークにつながる。
だから、分類法について外科的に考えてみよう。
クラシック検索
文書検索システム。クエリを入力すると、ランク付けされたURLのリストを返す。グーグルの仕事はSERPで終わる。青いリンクで何をするかは、あなたの仕事である。クローラーにオーソリティを示し、キーワードの意図にマッチさせ、エンゲージメントシグナルを獲得する。あなたはこのシステムを知っている。
AIの概要(AIO)
クラシック検索に追加された生成レイヤー。AIOは、Googleの既存の検索結果を取り込み、それらを要約段落に合成し、ほとんどすべてをすでに上位にランクされたページから引っ張ってくる。これはUI機能であり、新しい検索システムではない。言語モデルがコピーを書くスマートスニペットだと考えてほしい。その下のインデックスに変更はなく、その下のランキングシグナルにも変更はない。古典的なSEOをうまく適用すれば、AIOの資格はほぼ十分である。
SGE(サーチ・ジェネレイティブ・エクスペリエンス)
死んだ。2023年から2024年まで行われたラボの実験。ライブシステムとして参照するのはやめてください。
ジェミニ(スタンドアローン)
LLMのアシスタント。Googleのライブ検索インデックスへの永続的な接続なし。ナレッジグラフの統合なし。ショッピンググラフなし。その応答は、リアルタイムの検索ではなく、トレーニングデータから引き出される。このリストの他の全てとは全く異なる推論パイプライン。
PerplexityとChatGPT検索
検索補強生成(RAG)システムは、公共のウェブインデックスから取得し、答えを合成する。Perplexityはリアルタイムクロールを使用し、ChatGPTはBing APIに対して実行時に完全なURLコンテンツをフェッチする。これらの検索は比較的シンプルで、永続的なユーザーモデルも、多階層の知識インフラも、セッションをまたぐステートフルなコンテキストもない。
AIモード
上記のどれでもない。
AIモードは、検索インデックス、ナレッジグラフ、ショッピンググラフ(50B以上の商品)、マップといったグーグルのナレッジインフラストラクチャ全体に対して、複数のサブクエリを並行して実行し、検索された文章のカスタムコーパスを組み立て、ペアワイズLLMを使用してそれらを再ランク付けし、フラグメントレベルの引用検証を含むレスポンスを生成する、多段階、ステートフル、パーソナライズされた、文章レベルの検索および合成エンジンです。
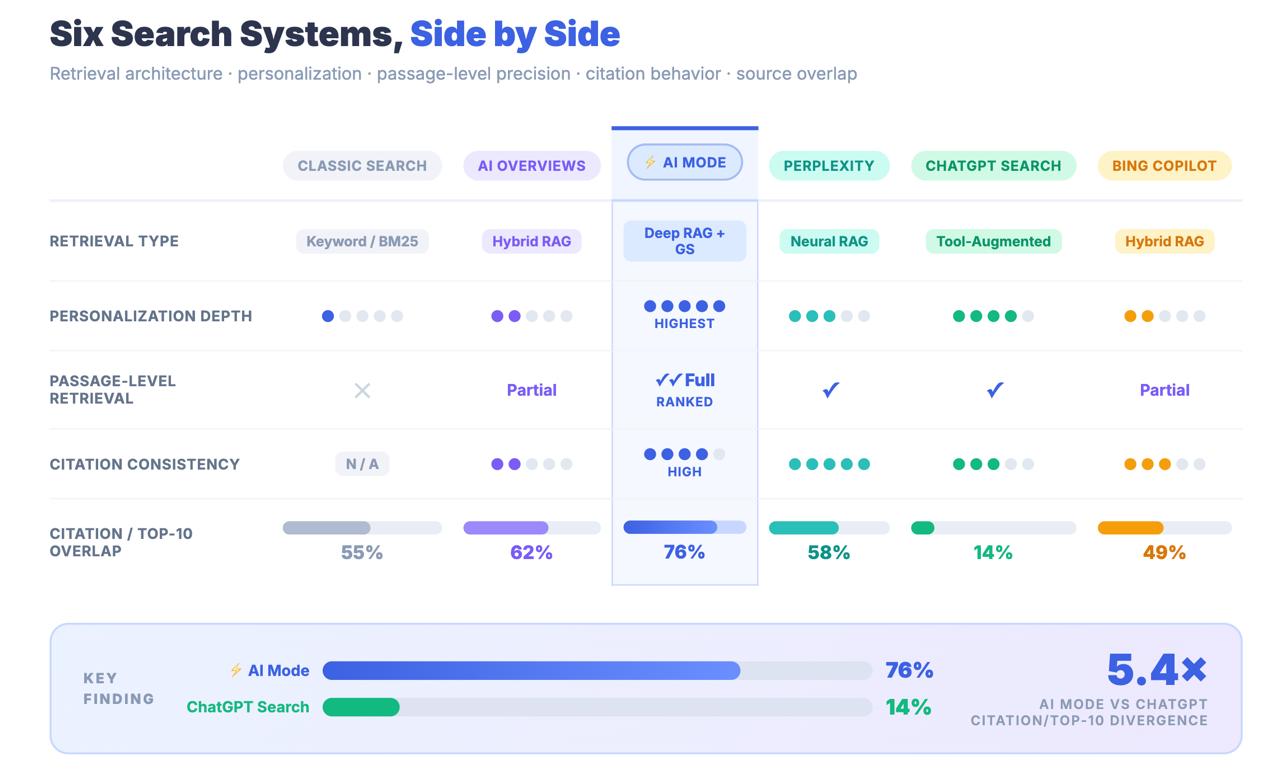
クラシック・サーチのラッパーではない。同じ製品の中にたまたま存在する並列検索システムなのだ。そして、この数字があなたを凍りつかせる:
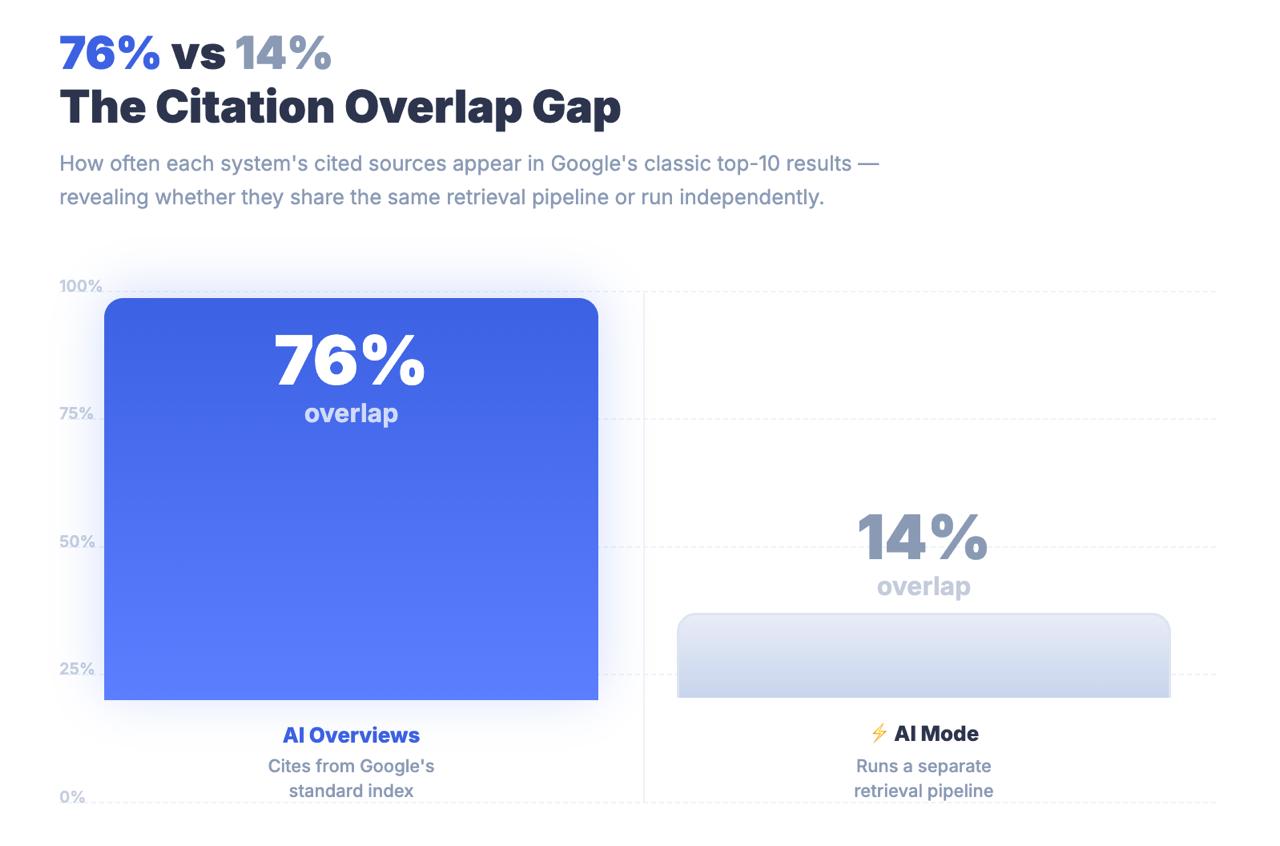
AIモードによって引用されたURLのうち、Googleの従来のトップ10にランクインしたのはわずか14%。
AIオーバービューの場合、この数字は76%である。この2つの数字の差は、丸め誤差ではない。これは、AIモードが古典的なランキングシグナルを通じてコンテンツを発見しているのではないことを物語る、アーキテクチャ上の発見である。全く異なる検索パイプラインを通じてコンテンツを発見しているのであり、1ページ目に到達した最適化戦略は、引用されるかどうかとはほとんど無関係かもしれない。
Googleの1ページ目に表示されることは、AIオーバービューの可視化には必要だが、AIモードにはほとんど関係ない。
このシステムは、図書館とリサーチ・アシスタントが関係しているのと同じだ。どちらも本を扱っている。一方はランク付けされた書棚を手渡す。もう一方はあなたに代わって本を読み、答えを総合し、どの文章が引用に値するかを判断する。どちらに最適化するかによって、あなたの仕事は根本的に違ってくる-そして今現在、ほとんどのチームは、リサーチ・アシスタントが彼らのオーディエンスが使っているものである場合、本棚に最適化している。
キーポイントAIモードはGoogle検索とブランドを共有し、AI概要とURLを共有しているが、構造的には異なる検索システムである。AIモードの引用のうち、従来のトップ10からの引用はわずか14%であるのに対し、AI Overviewsは76%である。AIモードをAIOの拡張機能として扱うことは、実際の戦略的結果を伴う測定ミスである。
アーキテクチャクエリが答えになるまで
AIモードの説明のほとんどは、AIモードが何をするのかを外側から説明している。"あなたのクエリをよりよく理解する"、"複数のソースを合成する"、"会話のような答えを提供する"。これらの説明は間違ってはいない。最適化には役に立たない。
以下は、コンポーネントごとに名前が付けられた完全なパイプラインと、各ステージを管理する特許である。これこそが、最適化が実際に目標とする意味である。なぜなら、名前を付けられないシステムを体系的に改善することはできないからだ。
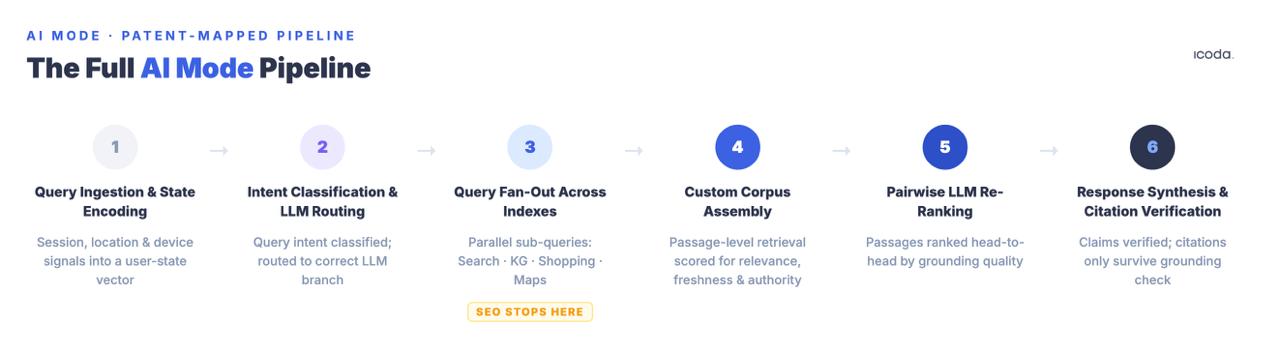
6段階のパイプラインは、あなたが実際に最適化しているものだ。現在の実践のほとんどは、1つのステージに取り組んでいる。
ステージ1クエリの取り込みとユーザー状態のエンコード
生のクエリは直接検索に入ることはない。まず、ユーザーのステートフルコンテキストベクトル(セッション履歴、全セッションにわたる過去のクエリ、デバイス、場所、時間帯、グーグルのエコシステムシグナル(検索、マップ、Gmail、YouTube)から構築された密な埋め込み)とペアリングされる。このパーソナライゼーション・ベクトルは、検索を開始する前に、「このクエリが意味するもの」を修正する。
2人のユーザーが同じクエリーを入力することは、事実上、異なる検索指示を出すことになる。このことの意味は、このセクションのすぐ後にある独立したセクションに値するほど重要である。
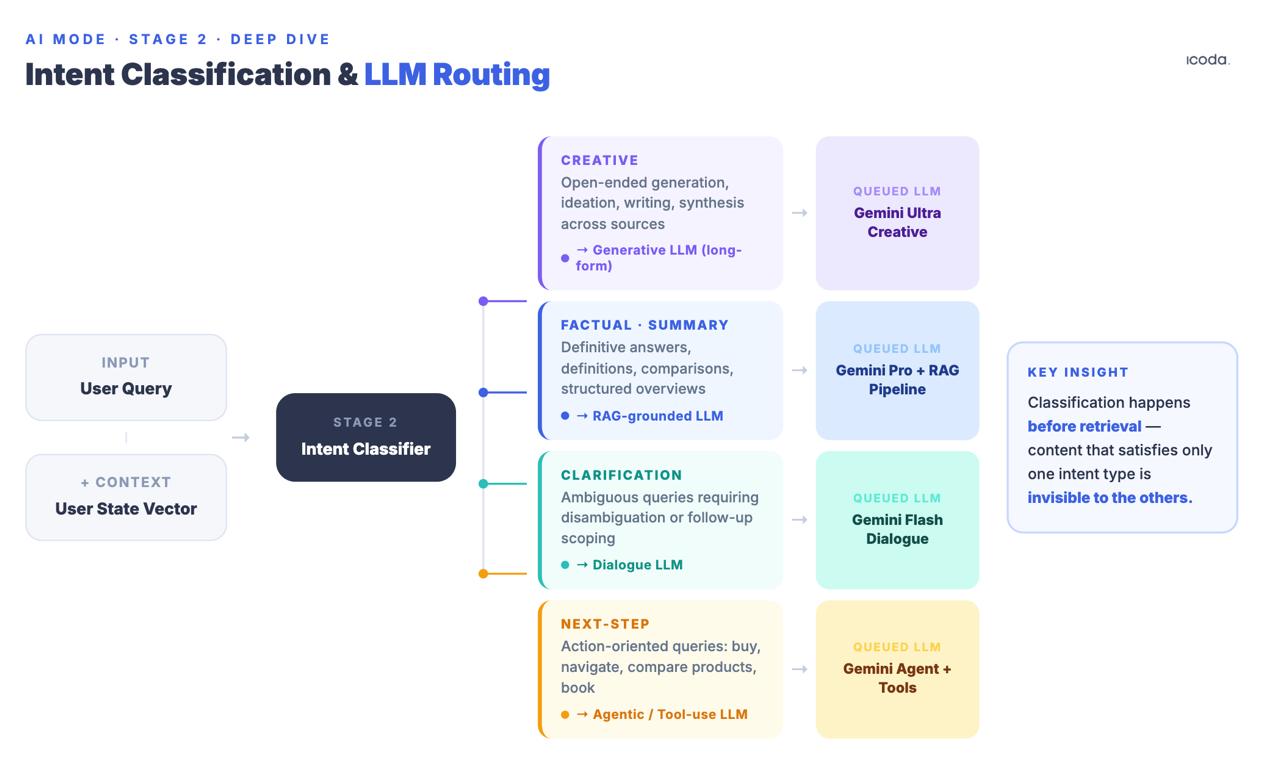
第2段階クエリーインテントの分類とLLMルーティング
検索する前に、システムはクエリを、創造的、事実/要約、明確化、次のステップ/タスクといった意図のカテゴリーに分類する。この分類に基づき、異なるダウンストリーム言語モデルがキューに入れられる。ステートフル・チャットの特許(US20240289407A1)は、それらを明示している:Creative Text LLM、SRP Generative LLM、Clarification LLM、Next Step LLM。
これは検索前に行われる。分類は、どのモデルがレスポンスを合成するかだけでなく、どの検索シグナルが最も重要かを決定する。情報クエリで上位にランクされるページは、インテント分類器がこのセッションを、情報合成よりもタスクの完了を最適化する次のステップのLLMにルーティングする場合、候補プールに全く入らないかもしれない。
ステージ3クエリーのファンアウト
この点が、AIモードがそれ以前のすべてのシステムと最も大きく異なる点である。
このシステムは、原文から複数の合成サブクエリを生成し、文書化された8つのバリアントタイプ(同等、関連、暗黙、比較、明確化、時間的、地理的、専門的文脈)をカバーする。出願日に注意。グーグルは7年前からマルチクエリのファンアウトを構築している。AIモードは、長いアーキテクチャの滑走路の消費者向け製品である。
暗黙的 "と "比較 "バリアントタイプは、ユーザが質問していないが、おそらく必要であろうクエリを生成するため、特に注目に値する。もし誰かが "best CRM for startups"(スタートアップに最適なCRM)と検索した場合、ファンアウトは単なる改行だけでなく、暗黙的なクエリ("series Aを過ぎてもスケールするCRMは?")、比較クエリ("early-stage companiesのためのSalesforce vs. HubSpot")、時間的クエリ("CRM pricing changes 2025″)、そして創業者のリサーチとRevOpsマネジャーの決定を区別する専門的コンテキストのバリアントを生成する。
すべてのサブクエリは、Google検索インデックス、ナレッジグラフ、ショッピンググラフ、マップで同時に実行される。グーグルは、AIモードが1つの複雑なクエリに対して「数百の検索」を実行できることを確認している。テーマ検索特許(US12158907B1)は、結果をセマンティッククラスターに整理する。サブテーマは、反復的に追加の検索ラウンドをトリガーする。
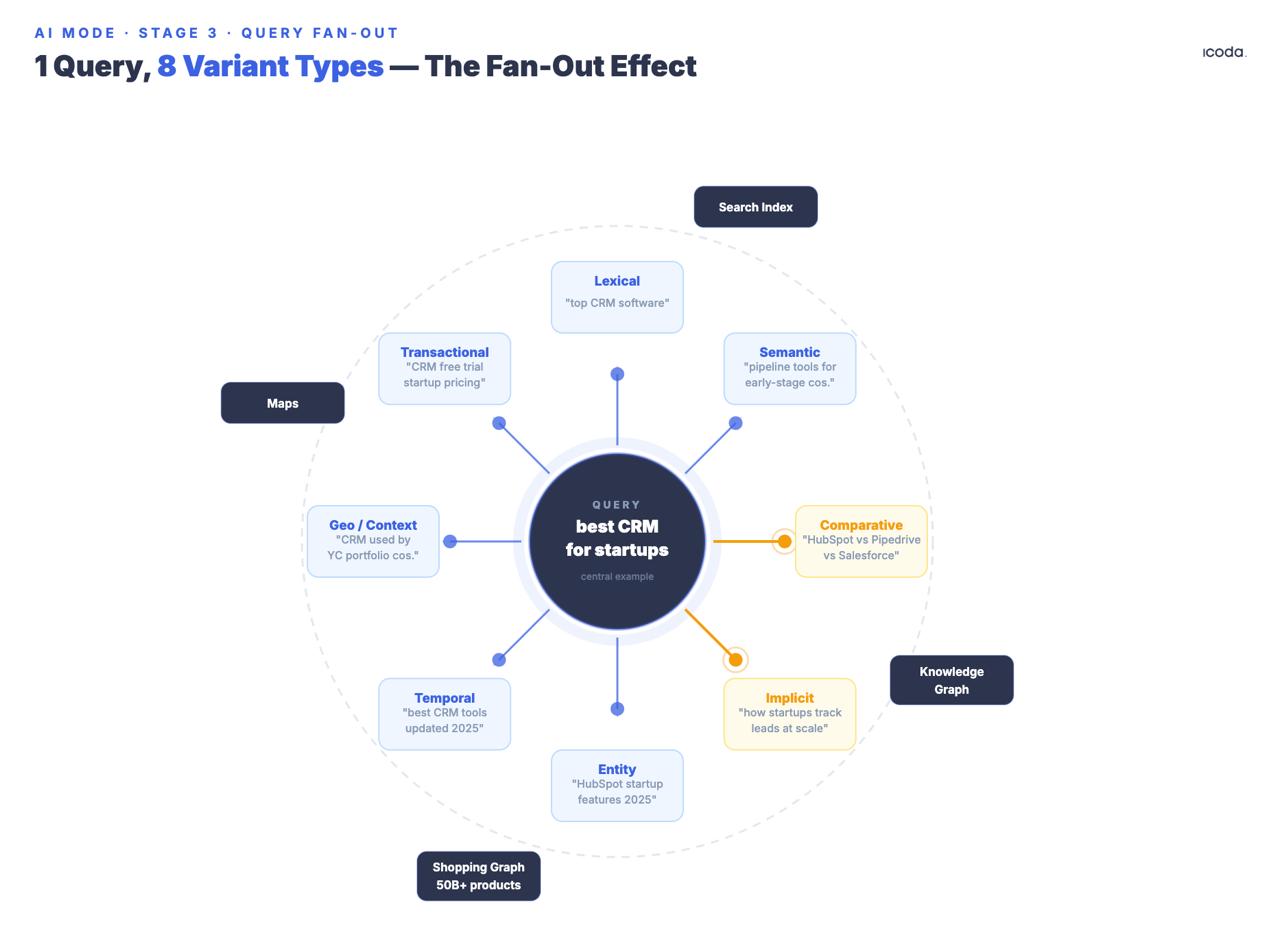
グーグルは2018年に基礎となるファンアウト特許を申請した。AIモードは7年間かけて構築されたアーキテクチャーの消費者向け製品である。
最高のCRM」に関する権威のあるコンテンツはあるが、比較的なものはなく、時間的なものもなく、プロフェッショナルなコンテキストのバリアントをターゲットにしたものもないブランドは、関連するすべてのセッションで発火する複数のクエリタイプから除外されます。ファンアウトは、あなたのドメインオーソリティを気にしているわけではなく、それぞれのバリアントサブクエリが、ペアワイズコンパイルに勝つかどうかを気にしているのです。
ステージ4:カスタム・コーパスの組み立て
取得されたパッセージ(文書ではなくパッセージ)はカスタムコーパスに組み立てられる。特許WO2024064249A1には、文脈の一貫性を保つために、システムが関連するパッセージの周囲にある最大5つの隣接するチャンクを検索する方法が記載されている。これは、文書セクションを流れる散文の流れが重要であることを意味する。検索にヒットするようなよく構成された論旨は、周囲の段落も一緒にコーパスに取り込む。
コーパスはカスタムである。すべてのユーザー、すべてのセッション、すべてのクエリが異なるものを生成します。あなたのコンテンツが競合する普遍的なドキュメントプールは存在しません。
第5ステージペアワイズLLM再ランキング
すべてのファンアウトのサブクエリからのパッセージが互いに競い合う。ランキングメカニズムはBM25ではない。TF-IDFでもない。LLMは、複数回の比較ラウンドを通して、どのパッセージが与えられたサブクエリをよりよく満たすか、というペアでパッセージを比較する。- を複数の比較ラウンドで比較する。勝者は勝ち進み、敗者は敗退する。
この段階は、現在ほとんどのSEO投資が接触に失敗する場所である。最初の一文で特定のサブクエスチョンに答えるような、濃密で直接的、事実に基づいた文章は、対比較できれいに勝利する。物語的で、説明的で、意見の多いコンテンツ(長文のエディトリアルSEOでうまく機能するタイプ)は、LLMが関連する主張を抽出するのに苦労するため、負ける傾向がある。ニッチな質問に対する直接的な答えで始まるRedditのスレッドは、8段落目に答えを埋めた3,000語の権威あるガイドを凌ぐことができる。ペアワイズ・メカニズムは、蓄積された信頼性ではなく、即時の報酬に報いる。
第6段階回答の統合と引用の検証
生き残った文章はジェミニに送られる。ジェミニは自然言語のレスポンスを生成する。生成されたレスポンスの各フラグメントを特定のコーパスの文章と照合し、引用をインラインで埋め込む。
これはページレベルの帰属ではありません。回答中の一文があなたのブログの一節と一致した場合、引用が認められます。あなたのページの残りの部分はまったく参照されないかもしれません。事実がぎっしり詰まった400ワードの記事は、3,000ワードの権威あるガイドを引用することができる。この仕組みは構造的に、包括的なカバー範囲よりも主張の密度に報酬を与えている。これは、従来の長文SEOが最適化することの正反対である。
キー・テイクアウェイAIモードは6段階のパイプラインである。従来のSEOは主にステージ3(検索適格性)に対応する。引用の勝敗は、ステージ4~6(パッセージレベルの密度、対LLM競争、断片レベルの事実の根拠)で決まりますが、いずれも標準的な最適化手法では対処できません。
パーソナライゼーション・レイヤーなぜ順位追跡は虚構なのか?
AIモードのアーキテクチャには、SEO業界が十分に考慮していない事実が埋め込まれている。率直に言おう:
2人の異なるユーザーが同じクエリを発行すると、異なる検索セットが生成される。同じ文書のランキングが異なるのではない。完全に異なる文書である。
User Embedding Models特許は、Googleが行動シグナル(クエリ、クリック、滞在時間、ロケーション履歴、マップアクティビティ、YouTube視聴履歴、Gmailコンテンツ)を、どのように高密度なベクトルにエンコードし、すべての入力クエリとペアにしているかを説明している。パーソナライゼーションベクトルは、従来のランキングシグナルが適用される前に検索を修正する。
あなたは、普遍的な順位を競う競争相手と競争しているのではありません。あなたは、直接観察することも、直接測定することも、ランク追跡ツールで再現することもできない、特定のユーザーペルソナのクエリコンテキスト内での関連性を求めて競争しているのです。
ユーザーへの埋め込み
ステートフル・チャットの特許(US20240289407A1)とユーザー・エンベッディング・モデルの特許を合わせると、パーソナライゼーション・スタックに関する記述がある:
- すべてのGoogle検索セッションの完全なクエリ履歴(ログインユーザーのみ)
- クリック、ホバー、滞留のパターンを行動規模で集計
- デバイスの種類と位置信号
- グーグルのエコシステム・データ:マップのチェックイン、YouTubeのトピック別視聴時間、Gmailのコンテンツ
最後のカテゴリーは、熟考する価値がある。Google I/O 2025でプレビューされ、2026年初頭の時点で部分的に展開されている「Personal Context」機能は、Gmail、カレンダー、Googleアカウントのデータを検索に直接組み込むことを明示している。この機能が本格的に始動すれば、先週スキー旅行についてEメールを送ったユーザーは、最近Googleショッピングでランニングシューズを購入したユーザーとは異なるAIモードの回答を「冬のアウトドア用品」に対して得ることになる。どのようなクエリに対しても、正規の検索結果という概念は機能的に消滅する。すべての検索結果は、検索クエリだけでなく、グーグルのエコシステム全体におけるユーザーの行動履歴の産物となる。
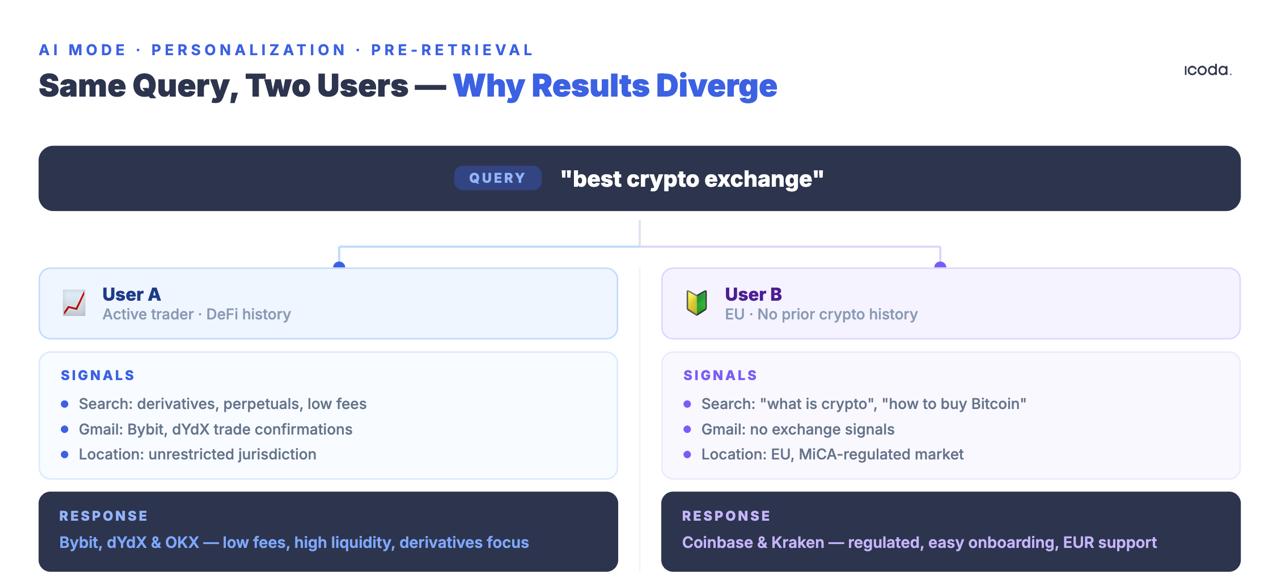
測定の結果
ランキング・トラッキング・ツールは、クリーンルームの、コンテクストのない環境からクエリーを行う。実際のユーザーは、深く文脈化されている。ツールは、実際のユーザーが見ていない仮想のポジションを測定している。
これは精度への不満ではない。妥当性の問題だ。測定が不正確なのではなく、完全に間違ったものを測定しているのだ。AIモードに対して実行されるランク・トラッカーからのポジション追跡の数字は、検索履歴も、ロケーション信号も、エコシステム・データも、セッション・コンテキストもないユーザーの経験を表している。そのユーザーは、意味のあるボリュームでは存在しない。
今回の反トラスト法判決は、この点を皮肉な形で鋭く突いている。2025年12月の救済措置では、グーグルは5年間で2回、競合他社と検索インデックスを共有することを求められている。しかし、ユーザー埋め込みモデルを共有することはできない。インデックスデータは、今やコモディティとなりつつあるが、AIモード・パーソナライゼーションを推進するものではない。学習のフライホイールである:毎日140億のクエリが、競合他社には真似のできないユーザー埋め込みモデルを更新し続けているのだ。競合他社は棚のスナップショットを得る。グーグルは、すべての利用者の顔を読み取った図書館員を維持している。
実際に測定に役立つもの
この状況を乗り切るのに最も適した立場にあるブランドは、最も忠実なランク追跡を行っているブランドではない。彼らは、パーソナライズされたAI検索には異なる測定パラダイムが必要であることを受け入れ、それに向かって構築している。実際のシグナルを持つ4つのプロキシ:
サードパーティツール(Profound、ZipTie、Ahrefs Brand Radar)を使って追跡した、AI回答におけるブランドのシェアオブボイス。サンプリングベースの近似値であり、完全なカバー率ではないが、正しい出力変数である引用のプレゼンスを測定している。絶対的なスコアではなく、競合他社と比較して追跡する。
クエリーセグメントレベルでのGSCインプレッション/クリックデカップリング。 インプレッションが上昇し、CTRが低下している情報クエリは、AIモードのカニバリゼーションの主な兆候です。インテントタイプ別にセグメントし、時間の経過とともに乖離が鮮明になっていく様子をご覧ください。
最も商業的に重要な20のクエリについて、AIモードによる引用監査を手動で行います。 どのページが引用されているか、どの文章が回答中に表示されているか、競合に焦点を当てたファンアウトのサブクエリに貴社ブランドが表示されているかどうかに注意してください。AIモードでは、回答1件あたり平均3.3件のエンティティの言及が生成されるのに対し、AI概要では1.3件です。あなたのドメインがクリックされることのないセッションに、あなたのブランドが存在する可能性があります。
下流シグナルとしてのブランド検索ボリューム。 AIモードが直接的なクリックを促進することなくブランド認知を生み出しているのであれば(アーキテクチャは、それがますますそうなっていることを示唆している)、ブランド検索ボリュームは、60-90日のウィンドウで遅行指標として動くはずである。
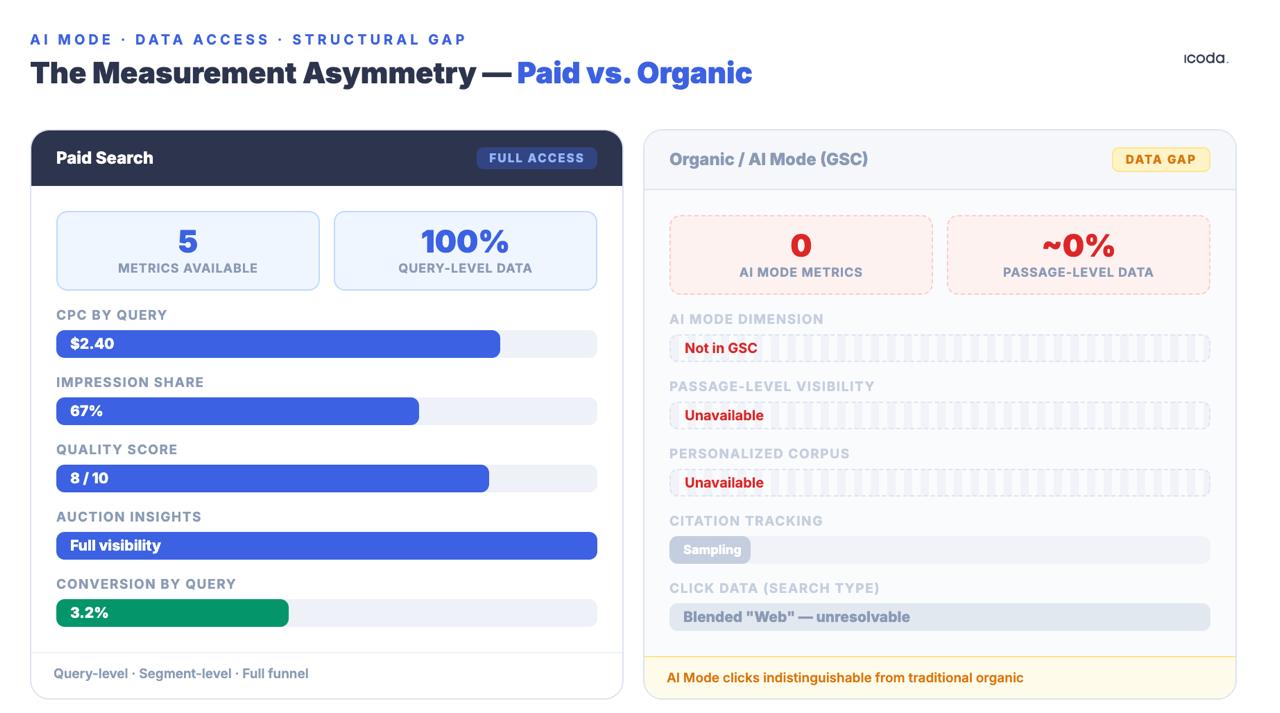
有料検索とオーガニック検索の測定ギャップは何年も前から存在していた。AIモードはそれを構造的な溝にまで広げた。
どれも完璧ではない。検索広告チームは、CPCデータ、インプレッションシェア、クオリティスコア、そして、クエリレベルのオークションインサイトを持っている。オーガニックチームは、意図的に集計され、サンプリングされ、匿名化されたGSCデータを得ている - そして、AIモードのクリックは、従来のオーガニックトラフィックと区別できない一般的な「ウェブ」検索タイプに混ぜられている。このギャップは、一時的なツールの問題ではない。これは意図的な製品アーキテクチャの決定であり、AIモードがオーガニック検索をより不透明なものにしているため、このギャップは広がっている。
正直なところ、現在のところAIモードの可視性を正確に測定することはできない。プロキシを測定することはできる。ブランドプレゼンスを追跡することはできる。インプレッションとクリックの比率がリアルタイムで悪化していくのを観察し、優先順位を決めるのに使うことができる。しかし、プロキシ測定とグランドトゥルースを混同してはいけません - そして、コンテクスチュアルでないクエリに向けられたランクトラッカーが、実際のログインしたコンテクスチュアルなユーザーがAIモード内でコンテンツをどのように体験するかについて意味のあることを教えてくれるかのように装うのはやめるべきです。
キーポイントユーザー埋め込みベクトルは、古典的なランキングシグナルが適用される前にAIモード検索を変更し、現在行われているランク追跡を、存在しないユーザーの測定にする。GSCのデカップリングシグナルと手動の引用監査によって補完される、AIレスポンスにおけるポジションからブランドシェアオブボイスに主要な測定をシフトする。
結論
AIモードは、よりスマートなクラシック検索ではありません。AIモードは、6つの段階、文章レベル、パーソナライズされた検索システムであり、ランキングシグナルが適用される前に、オーディエンスが読んでいる答えの中にどのブランドが存在するかをすでに決定している。
従来のトップ10結果との14%の引用の重なりがすべてを物語っている:ランキングと引用は今や独立した変数である。ランキングと引用は今や独立した変数なのだ。あなたのコンテンツが、適切なサブクエリのバリアントに対してペアワイズLLM比較で勝利するような文章を作成すれば、47位に座り、一貫した引用を獲得することができる。
アーキテクチャは文書化されている。特許は公開されている。AIモードがデフォルトの検索エクスペリエンスになる前に適応するための時間は、数年単位ではなく、数四半期単位で測られる。
次に何が起こるかは選択だ。
シェア


記事を評価する












