Проблема со всем, что Вы прочитали до сих пор
Большинство материалов, посвященных режиму искусственного интеллекта, попадают в один из двух неудачных режимов. Первый - это затаившая дыхание журналистика о продукте, которая описывает функции, не объясняя, что лежит в основе механизма. Второй - это успокаивающие статьи практиков, которые впитали тезисы Google и передали их дальше - "стандартное SEO - это все, что Вам нужно", "качественный контент побеждает", "ничего принципиально не изменилось".
Оба варианта ошибочны и будут стоить брендам денег.
В этой статье речь идет о маркетинге. Она основана на патентных документах Google, проверенных количественных исследованиях и нескольких выводах, которые широкое сообщество, как видно, не воспринимает всерьез. Цель проста: к концу статьи Вы должны понять, как именно работает AI SEO, почему он нарушает традиционную SEO-ортодоксию и что с этим делать.
Мы затронем много тем. Начнем с самого важного, в чем почти все ошибаются.
Что на самом деле представляет собой режим искусственного интеллекта (и чем он не является)
Вот самое дорогое заблуждение в Вашей отрасли на данный момент: что режим AI - это более умная версия того, что Вы уже знаете.
На самом деле, это не так. И смешение его с привычными системами приводит к реальным стратегическим ошибкам - бренды оптимизируют видимость AI Overviews и предполагают, что она переходит, SEO-команды приводят поведение ChatGPT в качестве аналога, специалисты-практики относятся к AI Mode как к более сложному Featured Snippet. Это ошибки категории. Они приводят к неправильным инвестиционным решениям и неверным системам измерения.
Так что давайте будем хирургически подходить к таксономии.
Классический поиск
Система поиска документов. Вы вводите запрос; он возвращает ранжированный список URL. Работа Google заканчивается на SERP. То, что Вы делаете с голубыми ссылками, - это Ваше дело. Игра в оптимизацию здесь стабильна уже двадцать лет: сигнализируйте об авторитете для краулера, соответствуйте намерениям ключевого слова, зарабатывайте сигналы вовлеченности. Вы знаете эту систему.
Обзоры ИИ (AIO)
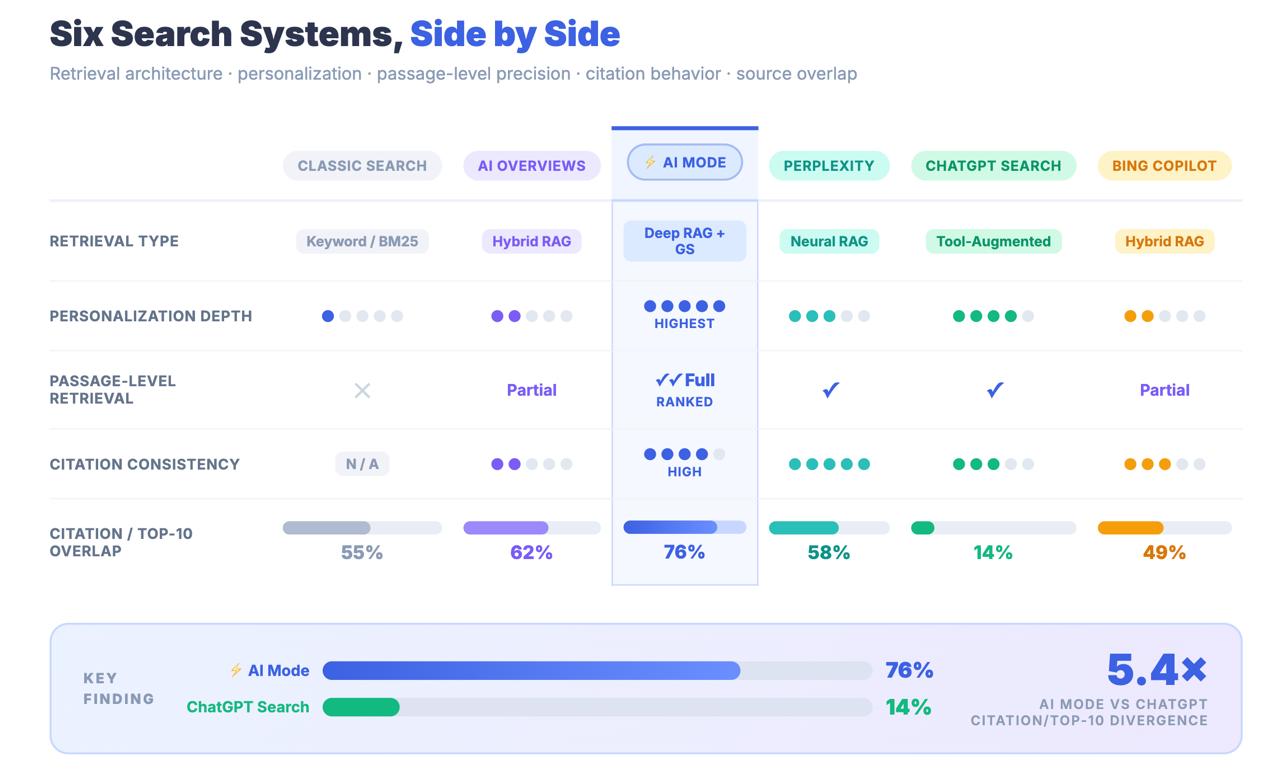
Генеративный слой, прикрепленный поверх Классического поиска. AIO берет существующие результаты поиска Google и синтезирует их в краткий параграф, почти полностью заимствуя их из страниц, уже занимающих первые места в рейтинге - 76,1% цитат из AI Overview приходятся на 10 лучших результатов. Это функция пользовательского интерфейса, а не новая система поиска. Думайте о нем как об умном сниппете, копию которого пишет языковая модель. Индекс под ним не изменился; сигналы ранжирования под ним не изменились. Классического SEO, применяемого правильно, в значительной степени достаточно для соответствия требованиям AIO.
SGE (Search Generative Experience)
Мертв. Эксперимент Labs, который длился до 2023-2024 годов. Перестаньте ссылаться на него как на живую систему.
Близнецы (отдельно)
Ассистент LLM. Нет постоянного соединения с живым поисковым индексом Google. Нет интеграции с Графом знаний. Нет Shopping Graph. Его ответы основаны на обучающих данных, а не на поиске в реальном времени. Совершенно иной конвейер выводов, чем все остальные в этом списке.
Perplexity и ChatGPT Search
Системы Retrieval-Augmented Generation (RAG), которые берут информацию из публичных веб-индексов и синтезируют ответы. Perplexity использует ползание в режиме реального времени; ChatGPT извлекает полный контент URL во время выполнения программы с помощью API Bing. Их поиск сравнительно прост - нет постоянной модели пользователя, нет многоуровневой инфраструктуры знаний, нет государственного контекста в сессиях.
Режим искусственного интеллекта
Ничего из вышеперечисленного.
AI Mode - это многоступенчатый, государственный, персонализированный механизм поиска и синтеза на уровне отрывков, который выполняет несколько параллельных подзапросов к полной инфраструктуре знаний Google - поисковому индексу, Knowledge Graph, Shopping Graph (50B+ товаров) и Maps - собирает пользовательский корпус найденных отрывков, ранжирует их, используя парный LLM, и генерирует ответ с проверкой цитирования на уровне фрагментов.
Это не обертка вокруг Классического поиска. Это параллельная поисковая система, которая живет внутри одного и того же продукта. И номер, который должен остановить Вас:
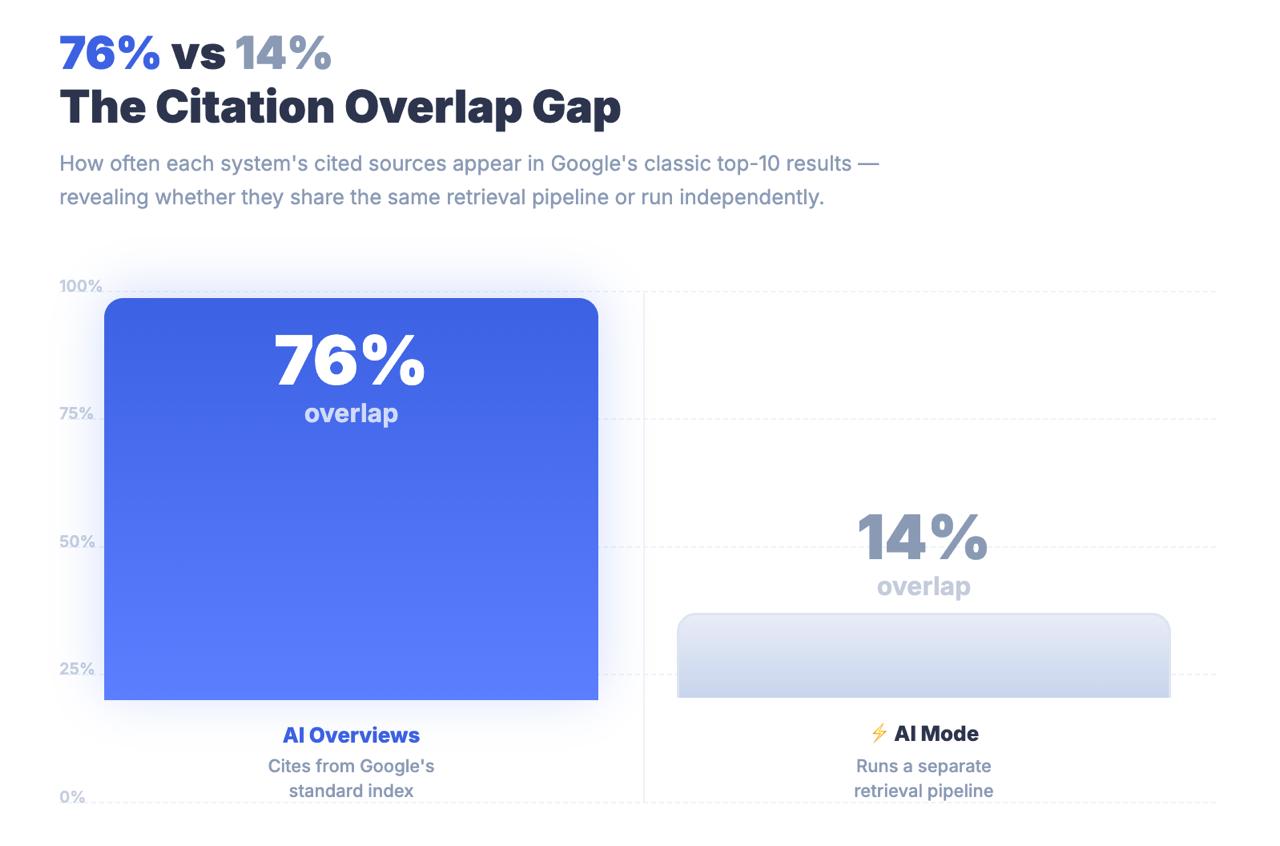
Только 14% URL-адресов, приведенных AI Mode, попадают в традиционный топ-10 Google.
Для обзоров ИИ это число составляет 76%. Разрыв между этими двумя цифрами - не ошибка округления. Это архитектурный вывод, который говорит Вам о том, что AI Mode не находит контент с помощью классических сигналов ранжирования. Он находит контент с помощью совершенно другого поискового конвейера - и стратегии оптимизации, благодаря которым Вы попали на первую страницу, могут быть в значительной степени не связаны с тем, будут ли Вас вообще цитировать.
Нахождение на первой странице Google необходимо для видимости AI Overview; для AI Mode это не имеет большого значения.
Эти системы связаны между собой так, как связаны библиотека и научный сотрудник. Оба имеют дело с книгами. Один передает Вам полку с книгами. Другой читает книги за Вас, обобщает ответ и решает, какие отрывки стоило процитировать. Ваша работа кардинально отличается в зависимости от того, для чего Вы оптимизируете - и прямо сейчас большинство команд оптимизируют для полки, когда исследовательский помощник - это то, чем пользуется их аудитория.
Основные выводы: Режим AI Mode имеет общий бренд с Поиском Google и URL-адрес с Обзорами AI, но структурно он представляет собой отличную поисковую систему. Только 14% ссылок на AI Mode приходят из традиционных результатов топ-10 - по сравнению с 76% для AI Overviews. Отношение к AI Mode как к расширению AIO - это ошибка измерения с реальными стратегическими последствиями.
Архитектура: Как запрос становится ответом
Большинство объяснений режима искусственного интеллекта описывают его работу со стороны: "он лучше понимает Ваш запрос", "он синтезирует множество источников", "он дает ответы в разговорной форме". Эти описания не являются неправильными. Они бесполезны для оптимизации.
Далее следует полный трубопровод, названный компонент за компонентом, с патентами, регулирующими каждый этап. Вот что на самом деле означает оптимизация - потому что Вы не можете систематически улучшать систему, которой Вы не можете дать название.
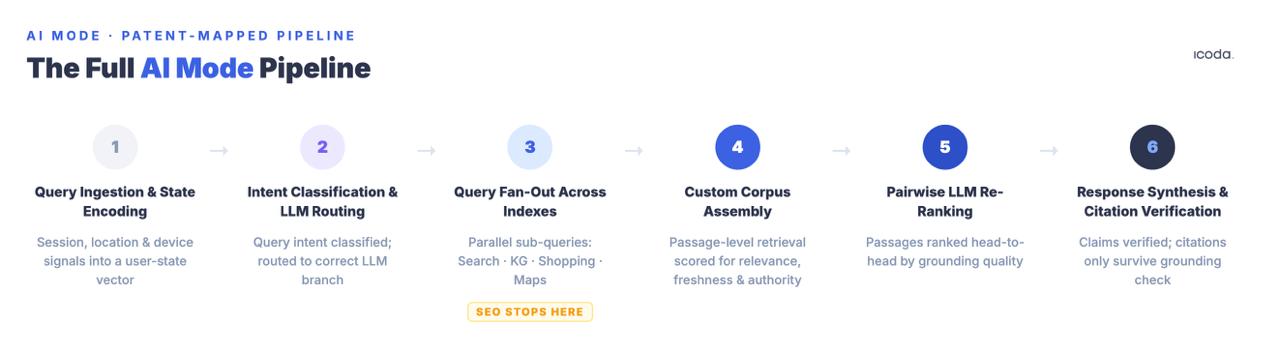
Шестиступенчатый конвейер - это то, для чего Вы на самом деле оптимизируете работу. Большинство современных практик рассматривают одну стадию.
Этап 1: Сбор запросов и кодирование состояния пользователя
Необработанный запрос не поступает в поисковую систему напрямую. Сначала он сопоставляется с вектором контекста пользователя - плотной вставкой, созданной на основе истории сессий, предыдущих запросов во всех сессиях, устройства, местоположения, времени суток и сигналов экосистемы Google (Поиск, Карты, Gmail, YouTube). Этот вектор персонализации изменяет то, что "этот запрос означает", еще до начала поиска.
Два пользователя, набирающие одинаковые запросы, фактически выдают разные инструкции по поиску. Последствия этого достаточно значительны, чтобы заслужить свой собственный раздел, который следует сразу после этого.
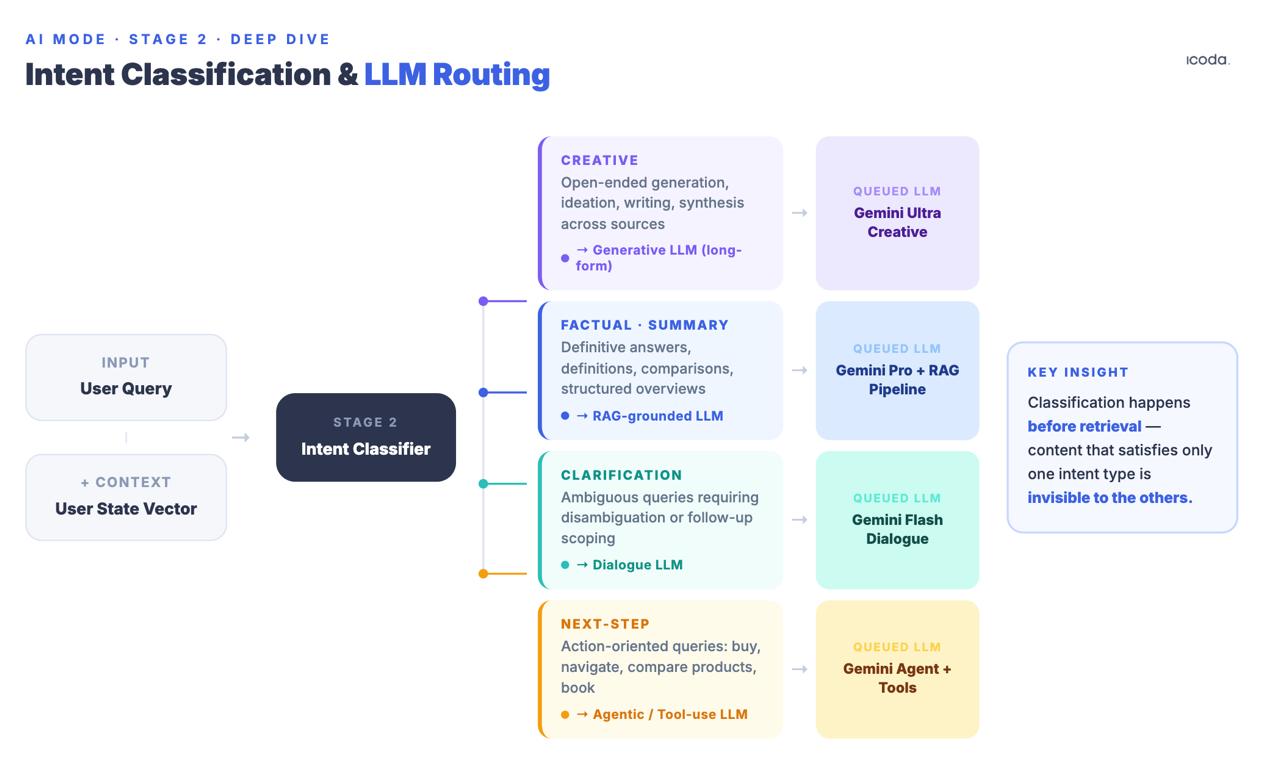
Этап 2: Классификация намерений запроса и LLM-маршрутизация
Перед поиском система классифицирует запрос на категории намерений: творческий, фактический/краткий, уточняющий или следующий шаг/задача. На основе этой классификации в очередь ставятся различные последующие языковые модели. В патенте на чат с состоянием (US20240289407A1) они названы в явном виде: Creative Text LLM, SRP Generative LLM, Clarification LLM, Next Step LLM.
Это происходит до извлечения информации. Классификация определяет не только то, какая модель синтезирует ответ, но и то, какие поисковые сигналы имеют наибольшее значение. Страница, которая хорошо ранжируется по информационным запросам, может вообще не попасть в пул кандидатов, если классификатор намерений направит эту сессию на следующий этап LLM, оптимизированный для выполнения задачи, а не для синтеза информации.
Этап 3: Веерная рассылка запросов
Именно здесь режим AI Mode наиболее резко отличается от всех систем, которые были до него.
Система генерирует множество синтетических подзапросов на основе оригинального, охватывая восемь документированных типов вариантов: эквивалентный, связанный, неявный, сравнительный, уточняющий, временной, географический и профессиональный контекст. Обратите внимание на дату подачи заявки. Google занимается созданием многозапросных вееров уже семь лет. AI Mode - это потребительский продукт длинной архитектурной взлетной полосы.
Особого внимания заслуживают "неявные" и "сравнительные" типы вариантов, поскольку они генерируют запросы, которые пользователь не задавал, но которые, скорее всего, ему нужны. Если кто-то ищет "лучшую CRM для стартапов", веерный поиск генерирует не только переформулировки, но и неявные запросы ("какая CRM масштабируется после серии А?"), сравнительные запросы ("Salesforce против HubSpot для компаний ранней стадии"), временные запросы ("изменение цен на CRM в 2025 году"), а также варианты с профессиональным контекстом, которые отличают основателя, изучающего вопрос, от менеджера RevOps, принимающего решение.
Все подзапросы выполняются одновременно в индексе Google Search, Knowledge Graph, Shopping Graph и Maps. Google подтвердил, что режим AI Mode может выполнять "сотни поисковых запросов" для одного сложного запроса. Патент на тематический поиск (US12158907B1) организует результаты в семантические кластеры; подтемы запускают дополнительные раунды поиска итеративно - это означает, что веерный поиск может повторяться, а не просто прорываться один раз.
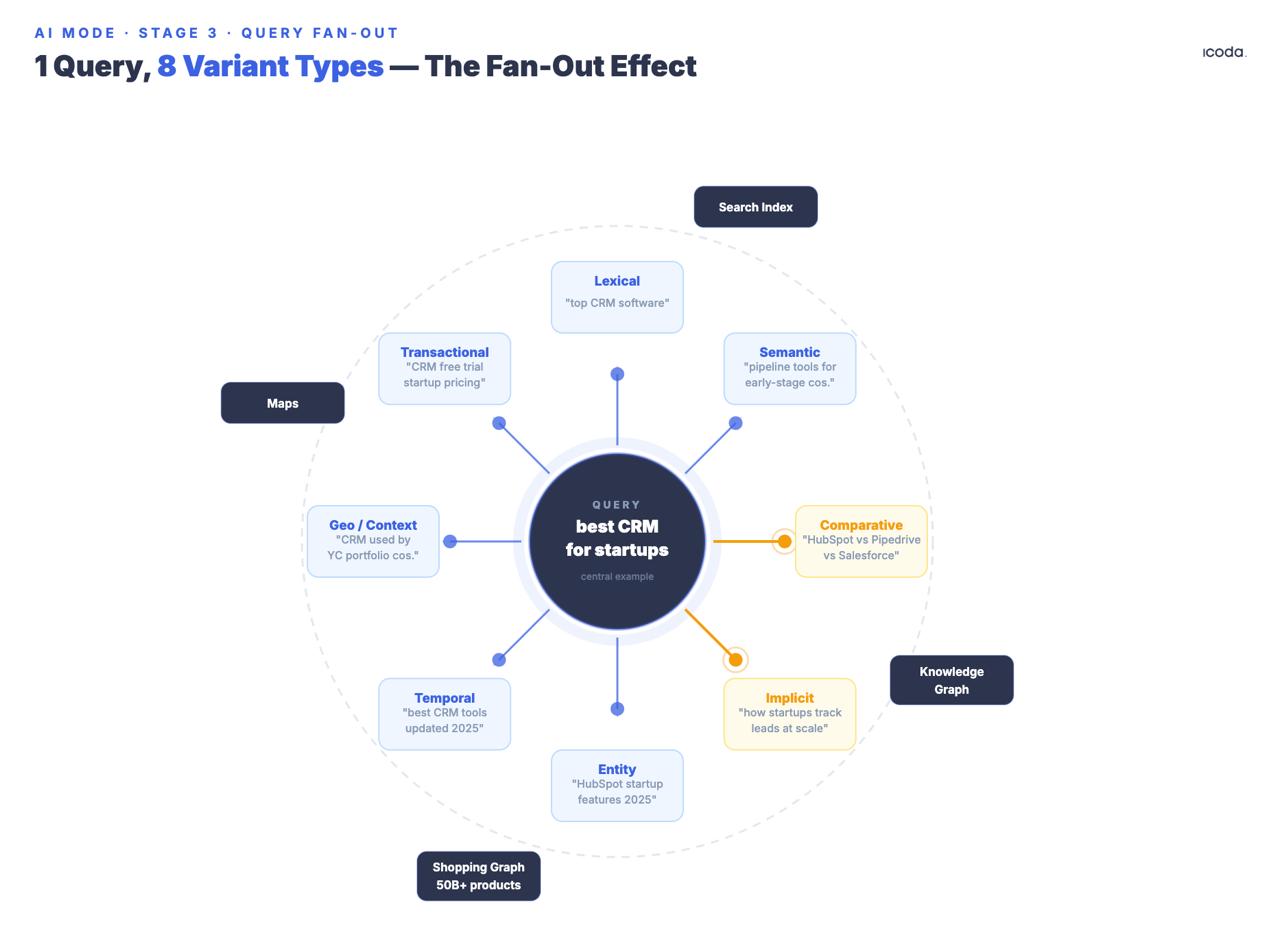
Google подал основополагающий патент на веерный выход в 2018 году - режим AI Mode является потребительским продуктом семилетней работы по созданию архитектуры.
Бренд, у которого есть авторитетный контент на тему "лучшие CRM", но нет ничего сравнительного, ничего временного и ничего, нацеленного на варианты профессионального контекста, отсутствует в нескольких типах запросов, которые срабатывают в каждой соответствующей сессии. Веерный вывод не заботится об авторитетности Вашего домена - его волнует, появляется ли в каждом вариантном подзапросе отрывок, который выигрывает в парном сравнении.
Этап 4: Сборка корпуса на заказ
Извлеченные отрывки - не документы, а отрывки - собираются в пользовательский корпус. В патенте WO2024064249A1 описано, как система может извлекать до пяти соседних фрагментов вокруг соответствующего отрывка, чтобы сохранить контекстуальную связность. Это означает, что поток прозы в разделе документа имеет значение. Хорошо структурированный аргумент, получивший результат поиска, потянет за собой в корпус и соседние абзацы.
Корпус является индивидуальным. Каждый пользователь, каждая сессия, каждый запрос создают свой корпус. Не существует универсального пула документов, в котором конкурирует Ваш контент, - есть миллионы пулов, созданных по запросу конкретного пользователя.
Этап 5: Попарное повторное ранжирование LLM
Передачи из всех подзапросов с веерным выходом соревнуются друг с другом. Механизм ранжирования - это не BM25. Это не TF-IDF. LLM сравнивает отрывки попарно - какой отрывок лучше удовлетворяет заданному подзапросу? - в течение нескольких раундов сравнения. Победители продвигаются вперед; проигравшие выбывают.
Именно на этом этапе большинство инвестиций в SEO в настоящее время не приносят результата. Плотные, прямые, фактологические отрывки, отвечающие на конкретные подвопросы в первом предложении, выигрывают в парных сравнениях. Повествовательный, дискурсивный, перегруженный мнениями контент - тот, который хорошо работает в длинных редакционных SEO - как правило, проигрывает, потому что заставляет LLM прилагать больше усилий для извлечения релевантного утверждения. Тема Reddit, открывающаяся прямым ответом на нишевый вопрос, может превзойти авторитетное руководство объемом 3 000 слов, в котором ответ записан в восьмом абзаце. Парный механизм вознаграждает немедленную отдачу, а не накопленный авторитет.
Этап 6: Обобщение ответов и проверка цитирования
Сохранившиеся отрывки передаются в Gemini. Gemini генерирует ответ на естественном языке. Затем механизм связывания ответов выполняет проверку на уровне фрагментов: он сопоставляет каждый фрагмент сгенерированного ответа с определенными отрывками из корпуса и вставляет цитаты в строку.
Это не атрибуция на уровне страницы. Предложение в ответе, которое совпадает с отрывком из Вашего блога, заслуживает ссылки. На остальную часть Вашей страницы можно вообще не ссылаться. Фактологически плотная статья в 400 слов может превзойти по цитированию авторитетное руководство в 3 000 слов - потому что она производит больше поддающихся проверке фрагментов на единицу текста. Этот механизм структурно поощряет плотность утверждений, а не всесторонний охват. Это прямая инверсия того, для чего оптимизируется традиционный длинноформатный SEO.
Ключевые выводы: Режим AI - это шестиступенчатый конвейер. Традиционный SEO в основном решает задачу 3-го этапа (пригодность к поиску). Цитирование выигрывается или проигрывается на этапах 4-6 - плотность на уровне отрывка, парная конкуренция LLM и фактологическая обоснованность на уровне фрагмента - ни один из них не учитывается стандартной практикой оптимизации.
Слой персонализации: Почему отслеживание рангов - это фикция
В архитектуре режима AI SEO заложен один факт, с которым SEO-индустрия еще не до конца разобралась. Давайте сформулируем его прямо:
Один и тот же запрос, заданный двумя разными пользователями, дает разные поисковые наборы. Не разные рейтинги одних и тех же документов. А совершенно разные документы.
Патент User Embedding Models описывает, как Google кодирует поведенческие сигналы - запросы, клики, время пребывания, историю местоположения, активность на Картах, историю просмотра YouTube, содержимое Gmail - в плотные векторы, которые сопоставляются с каждым входящим запросом. Вектор персонализации изменяет результаты поиска до того, как будет применен какой-либо традиционный сигнал ранжирования.
Вы не участвуете в гонке с конкурентами за универсальную позицию в рейтинге. Вы участвуете в гонке за релевантность в конкретных контекстах запросов пользователей-персон, которые Вы не можете непосредственно наблюдать, не можете непосредственно измерить и не можете воспроизвести с помощью инструмента отслеживания рангов.
Что питает пользователя Встраивание
В патенте на чат с состоянием (US20240289407A1) и в патенте на модели встраивания пользователей описывается стек персонализации, основанный на:
- Полная история запросов во всех сессиях Google Search (для вошедших в систему пользователей)
- Модели кликов, наведения и пребывания в совокупном поведенческом масштабе
- Тип устройства и сигналы о местоположении
- Данные экосистемы Google: Отметки в Картах, время просмотра YouTube по темам, содержание Gmail
На последней категории стоит остановиться подробнее. Функция "Личный контекст" - представленная на Google I/O 2025 и частично внедренная в начале 2026 года - будет явно включать данные Gmail, Календаря и аккаунта Google непосредственно в поиск. Когда эта система заработает в полную силу, пользователь, написавший на прошлой неделе письмо о поездке на лыжах, получит другие ответы AI Mode на запрос "outdoor winter gear", чем тот, кто недавно купил кроссовки в Google Shopping. Концепция канонического результата поиска для любого запроса будет функционально мертва. Каждый результат будет являться продуктом поведенческой истории пользователя во всей экосистеме Google, а не только его поисковых запросов.
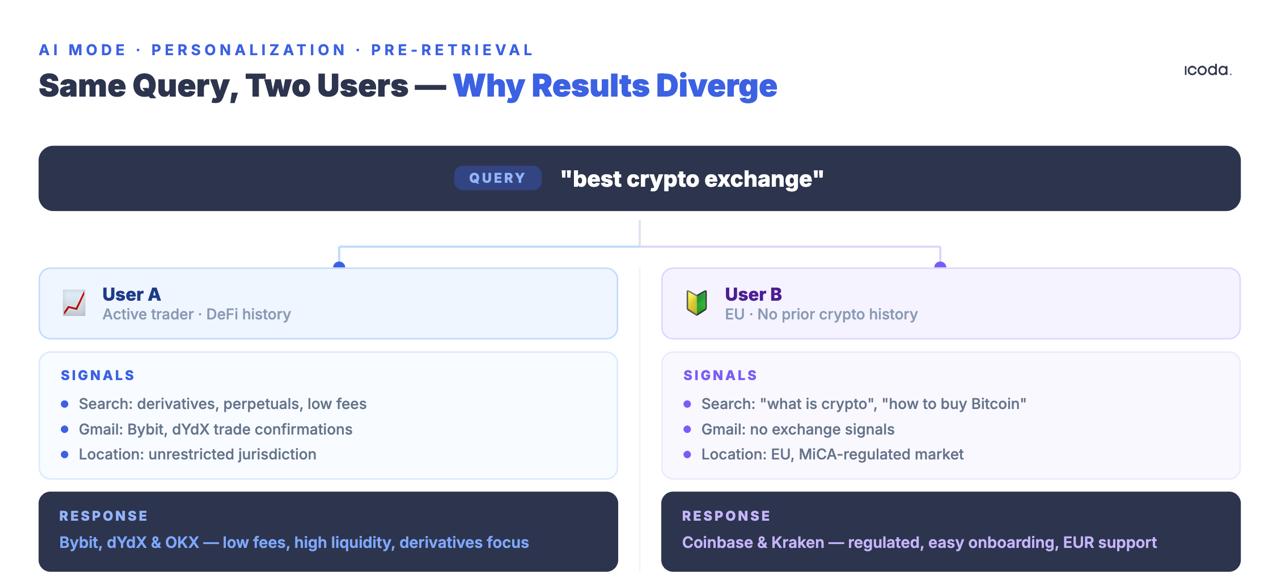
Последствия измерений
Инструменты для отслеживания рангов делают запросы в чистых комнатах, без контекста. Реальные пользователи глубоко контекстуализированы. Инструмент измеряет гипотетическую позицию, которую не видит ни один реальный пользователь.
Это не жалоба на точность. Это жалоба на валидность. Измерение не является неточным - оно измеряет совершенно не то, что нужно. Число позиций, полученное с помощью трекера рангов, работающего в режиме AI Mode, представляет собой опыт пользователя без истории поиска, без сигнала о местоположении, без данных об экосистеме и без контекста сессии. Такой пользователь не существует в каком-либо значимом объеме.
Постановление антимонопольного органа иронично подчеркивает этот момент. Постановление от декабря 2025 года требует, чтобы Google дважды в течение пяти лет делился с конкурентами своим поисковым индексом. Но он не может поделиться моделями встраивания пользователей. Индексные данные - которые теперь становятся товаром - это не то, что движет персонализацией в режиме AI. Это маховик обучения: 14 миллиардов ежедневных запросов, непрерывно поставляющих обновленные модели встраивания пользователей, которые никто из конкурентов не может воспроизвести. Конкуренты получают снимок полки. Google сохраняет библиотекаря, который читает лицо каждого посетителя.
Что на самом деле работает при измерении
Бренды, которые лучше всего справятся с этой задачей, - это не те, кто имеет самую точную систему отслеживания рангов. Это те, кто признал, что персонализированный поиск ИИ требует другой парадигмы измерения, и построил ее в соответствии с этим. Четыре косвенных показателя, которые имеют реальный сигнал:
Доля голосов бренда в ответах AI, отслеживаемая с помощью сторонних инструментов (Profound, ZipTie, Ahrefs Brand Radar). Это приблизительные данные, основанные на выборке, не полный охват - но они измеряют присутствие ссылок, что является правильной выходной переменной. Отслеживайте этот показатель в сравнении с конкурентами, а не в абсолютном значении.
Разделение впечатлений и кликов GSC на уровне сегмента запросов. Информационные запросы, показывающие рост показов при снижении CTR, - это основной видимый признак каннибализации в режиме AI. Сегментируйте запросы по типу намерения; наблюдайте, как со временем расхождения становятся все более резкими.
Ручной аудит цитирования в режиме AI для 20 Ваших самых коммерчески важных запросов. Обратите внимание на то, какие страницы цитируются, какие отрывки встречаются в ответе, и появляется ли Ваш бренд в подзапросах, ориентированных на конкурентов - ведь иногда это происходит. Режим AI в среднем генерирует 3,3 упоминания о сущностях на один ответ по сравнению с 1,3 для обзоров AI. Ваш бренд может присутствовать в сессиях, в которых на Ваш домен никогда не нажимали.
Объем брендированного поиска как сигнал для последующего использования. Если режим искусственного интеллекта генерирует осведомленность о бренде, не приводя к прямым кликам, что, как показывает архитектура, происходит все чаще, объем брендированного поиска должен двигаться как запаздывающий индикатор в течение 60-90 дней.
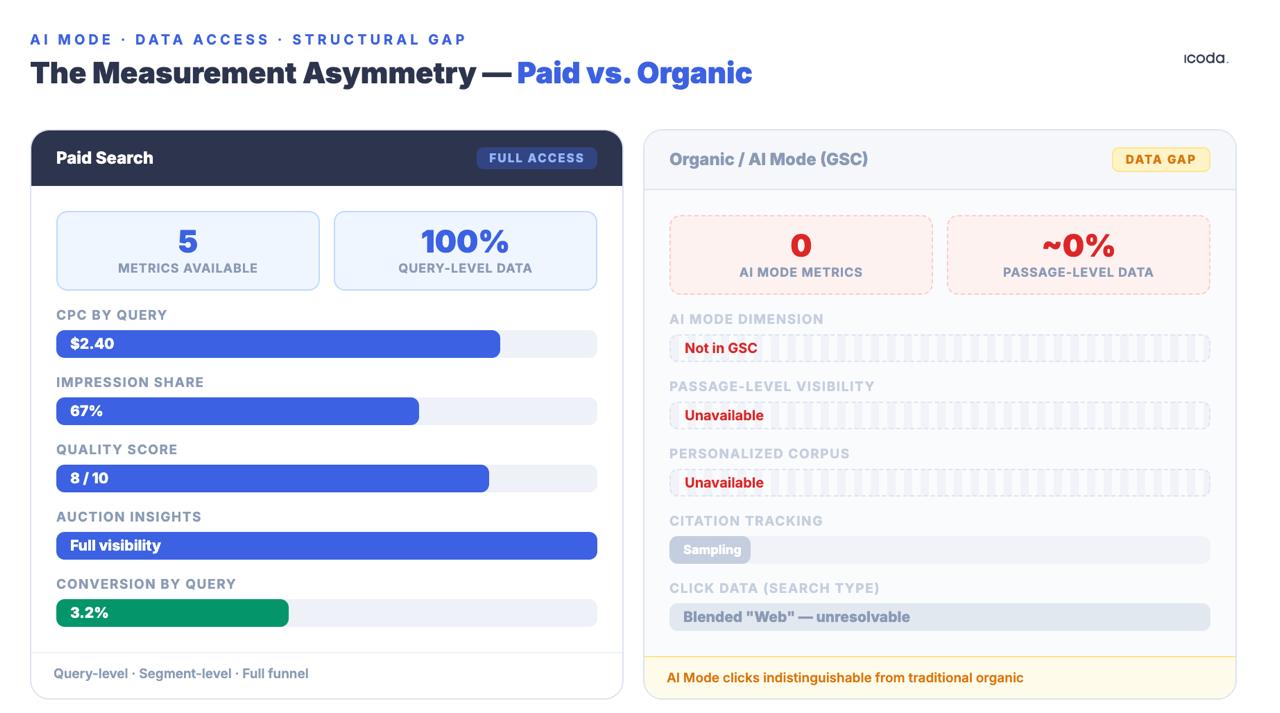
Разрыв в измерениях между платным и органическим поиском существует уже много лет. Режим искусственного интеллекта расширил его до структурной пропасти.
Ни один из этих методов не является идеальным. Асимметрия с командами платного поиска является структурной и значительной: команды платного поиска имеют данные CPC, долю впечатлений, показатели качества и информацию об аукционе на уровне запросов. Команды органического поиска получают данные GSC, которые намеренно агрегируются, отбираются и анонимизируются - а клики AI Mode смешиваются с общим типом поиска "Web", неотличимым от традиционного органического трафика. Этот пробел - не временная проблема с инструментарием. Это преднамеренное решение архитектуры продукта, и оно расширяется по мере того, как AI Mode делает органический поиск более непрозрачным, а не менее.
Честный ответ заключается в том, что в настоящее время Вы не можете точно измерить видимость Вашего режима AI. Вы можете измерить прокси. Вы можете отслеживать присутствие бренда. Вы можете наблюдать за ухудшением соотношения впечатлений и кликов в режиме реального времени и использовать это для определения приоритетов. Но не стоит путать измерение прокси с "правдой земли" - и Вам следует перестать притворяться, что ранговый трекер, направленный на неконтекстуализированный запрос, скажет Вам что-то значимое о том, как реальный, залогиненный, контекстуализированный пользователь воспринимает Ваш контент в режиме AI Mode.
Основные выводы: Векторы встраивания пользователей изменяют поиск в режиме ИИ еще до применения классических сигналов ранжирования, в результате чего отслеживание рангов - как это практикуется в настоящее время - является измерением несуществующего пользователя. Сместите первичное измерение с позиции на долю голоса бренда в ответах AI, дополнив их сигналами развязки GSC и ручным аудитом цитирования.
Заключение
Режим AI - это не более умный Классический поиск. Это отдельная система поиска - шесть этапов, уровень отрывка, персонализация до применения любого сигнала ранжирования - и она уже решает, какие бренды существуют в ответах, которые читает Ваша аудитория.
14%-ное совпадение цитирования с традиционными результатами Топ-10 говорит Вам обо всем: рейтинг и цитирование теперь являются независимыми переменными. Вы можете владеть первой страницей и быть невидимым в режиме AI Mode. Вы можете занять 47-ю позицию и зарабатывать постоянное цитирование, если Ваш контент содержит отрывки, которые побеждают в парных LLM-сравнениях для правильных вариантов подзапросов.
Архитектура задокументирована. Патенты опубликованы. Время на адаптацию до того, как режим искусственного интеллекта станет стандартным способом поиска, измеряется кварталами, а не годами.
Что произойдет дальше - это выбор.
Поделиться


Оцените статью












