O problema com tudo o que leste até agora
A maior parte da cobertura do Modo IA cai num de dois modos de falha. O primeiro é o jornalismo de produto sem fôlego que descreve as funcionalidades sem explicar a máquina subjacente. O segundo é a tranquilização de profissionais que absorveram os pontos de discussão do Google e os transmitiram - "SEO padrão é tudo o que precisas", "conteúdo de qualidade vence", "nada mudou fundamentalmente".
Ambas estão erradas de uma forma que vai custar dinheiro às marcas.
Este artigo vai para além do marketing. Baseia-se nos registos de patentes da Google, em estudos quantitativos verificados e em algumas descobertas que a comunidade em geral não levou a sério. O objetivo é simples: no final, deverás compreender exatamente como funciona o AI Mode, exatamente porque é que quebra a ortodoxia tradicional do SEO e exatamente o que fazer em relação a isso.
Vamos falar de muita coisa. Começa pela coisa mais importante, que quase toda a gente se enganou.
O que é realmente o modo IA (e o que não é)
Aqui está o equívoco mais caro no teu sector neste momento: que o modo IA é uma versão mais inteligente de algo que já conheces.
Na verdade, não é. E confundi-lo com sistemas familiares tem causado verdadeiros erros estratégicos - marcas que optimizam a visibilidade das AI Overviews e assumem que ela é transferida, equipas de SEO que citam o comportamento do ChatGPT como análogo, profissionais que tratam o AI Mode como um Featured Snippet mais sofisticado. Estes são erros de categoria. Conduzem a decisões de investimento erradas e a quadros de medição errados.
Por isso, vamos ser cirúrgicos quanto à taxonomia.
Pesquisa clássica
Um sistema de recuperação de documentos. Introduz uma consulta; devolve uma lista ordenada de URLs. O trabalho do Google termina no SERP. O que fazes com os links azuis é da tua conta. O jogo de otimização aqui tem sido estável há vinte anos: sinaliza a autoridade para o crawler, corresponde à intenção da palavra-chave, ganha sinais de envolvimento. Conheces este sistema.
Sínteses da IA (AIO)
Uma camada generativa sobreposta à Pesquisa clássica. A AIO pega nos resultados de pesquisa existentes do Google e sintetiza-os num parágrafo de resumo, retirando-os quase exclusivamente de páginas já classificadas no topo - 76,1% das citações da Visão geral da IA provêm dos 10 principais resultados. Trata-se de uma funcionalidade da IU, não de um novo sistema de pesquisa. Pensa nisto como um snippet inteligente com um modelo de linguagem a escrever o texto. O índice que lhe está subjacente mantém-se inalterado; os sinais de classificação que lhe estão subjacentes mantêm-se inalterados. O SEO clássico, bem aplicado, é largamente suficiente para a elegibilidade da AIO.
SGE (Search Generative Experience)
Morreu. A experiência dos laboratórios que decorreu até 2023-2024. Pára de o referir como um sistema vivo.
Gemini (autónomo)
Um assistente LLM. Não há conexão persistente com o índice de pesquisa em tempo real do Google. Não integra o Knowledge Graph. Não utiliza o Shopping Graph. As suas respostas são obtidas a partir de dados de treino, e não de pesquisa em tempo real. Um pipeline de inferência completamente diferente de tudo o que está nesta lista.
Perplexity e ChatGPT Procura
Sistemas de geração aumentada por recuperação (RAG) que extraem de índices públicos da Web e sintetizam respostas. O Perplexity utiliza um rastreio em tempo real; o ChatGPT vai buscar o conteúdo completo do URL em tempo de execução à API do Bing. A sua recuperação é comparativamente simples - sem modelo de utilizador persistente, sem infraestrutura de conhecimento de várias camadas, sem contexto de estado entre sessões.
Modo IA
Nenhuma das anteriores.
O AI Mode é um motor de recuperação e síntese em várias fases, com estado, personalizado e ao nível das passagens, que dispara várias subconsultas paralelas contra toda a infraestrutura de conhecimento do Google - índice de pesquisa, Knowledge Graph, Shopping Graph (mais de 50 mil produtos) e Maps -, reúne um corpus personalizado de passagens recuperadas, classifica-as novamente utilizando um LLM em pares e gera uma resposta com verificação de citações ao nível dos fragmentos.
Não se trata de um invólucro em torno da Pesquisa clássica. É um sistema de pesquisa paralelo que, por acaso, está integrado no mesmo produto. E o número que te deve fazer parar de pensar:
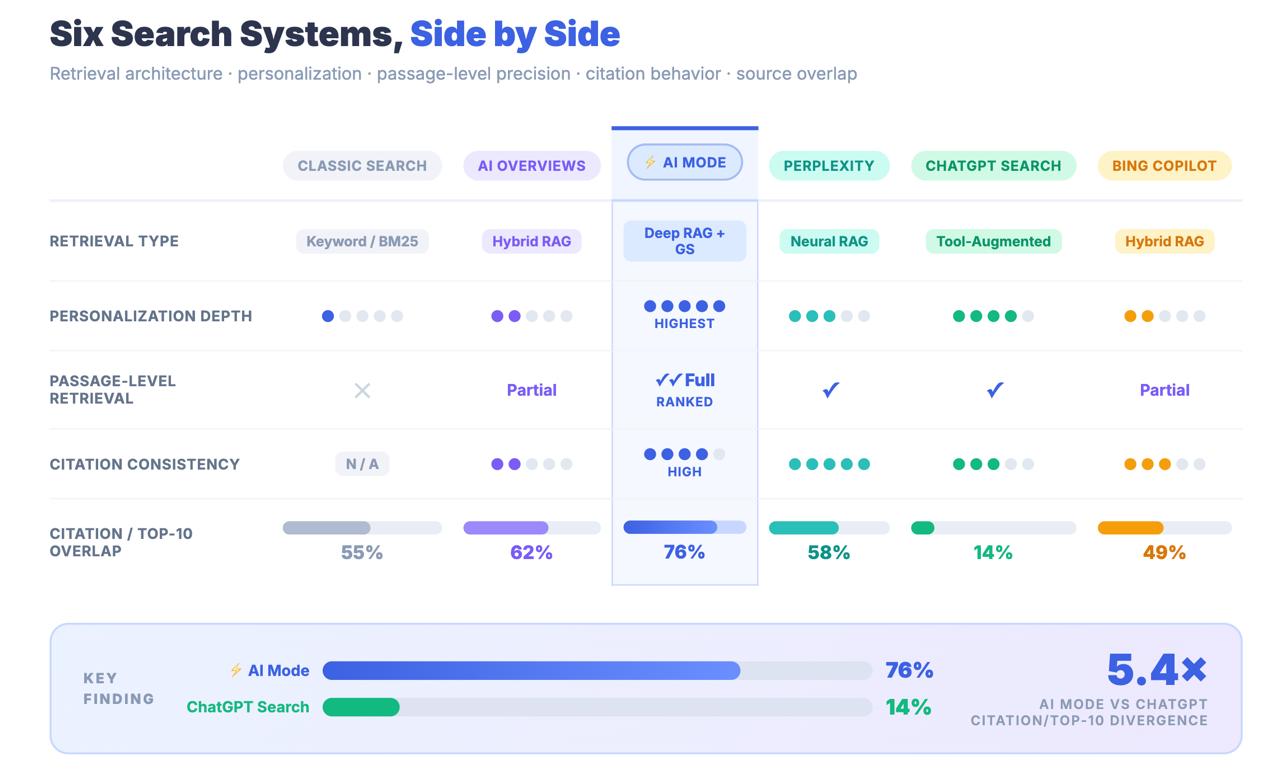
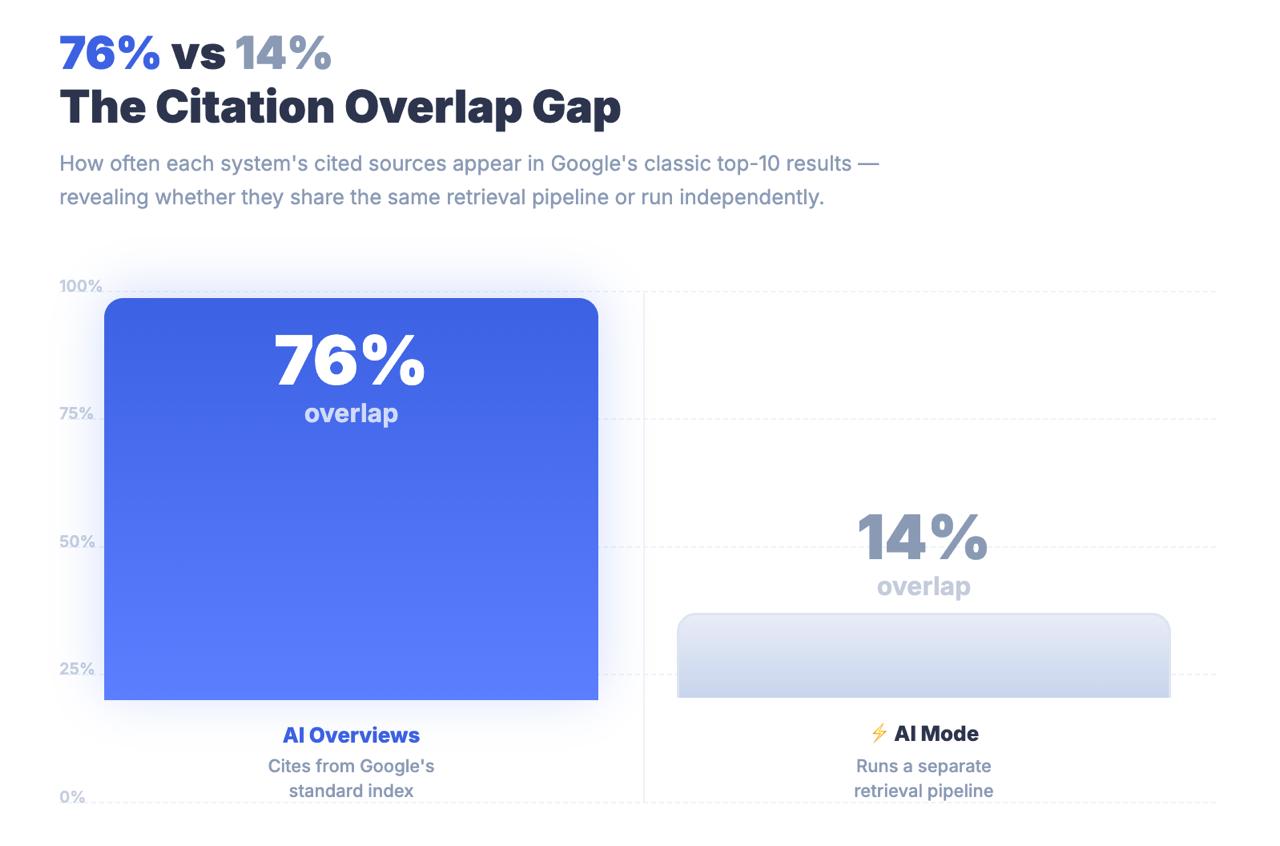
Apenas 14% dos URLs citados pelo Modo IA estão classificados no tradicional top 10 do Google.
Para as sínteses de IA, esse número é de 76%. A diferença entre esses dois números não é um erro de arredondamento. É uma descoberta arquitetónica que te diz que o Modo IA não está a encontrar conteúdo através de sinais de classificação clássicos. Está a encontrar conteúdo através de uma conduta de recuperação completamente diferente - e as estratégias de otimização que te levaram à primeira página podem ser largamente irrelevantes para o facto de seres ou não citado.
Estar na primeira página do Google é necessário para a visibilidade da visão geral da IA; para o modo de IA, é em grande parte irrelevante.
Os sistemas estão relacionados da mesma forma que uma biblioteca e um assistente de investigação estão relacionados. Ambos lidam com livros. Um entrega-te uma prateleira classificada. O outro lê os livros por ti, sintetiza a resposta e decide quais as passagens que vale a pena citar. O teu trabalho é fundamentalmente diferente dependendo de qual deles estás a otimizar - e, neste momento, a maioria das equipas está a otimizar para a prateleira quando o assistente de pesquisa é o que o seu público está a utilizar.
Conclusão principal: O Modo de IA partilha uma marca com a Pesquisa Google e um URL com as Sínteses de IA, mas é um sistema de recuperação estruturalmente distinto. Apenas 14% das citações do Modo de IA provêm dos resultados tradicionais do top 10, em comparação com 76% das sínteses de IA. Tratar o Modo AI como uma extensão AIO é um erro de medição com consequências estratégicas reais.
A Arquitetura: Como uma consulta se torna uma resposta
A maioria das explicações do Modo IA descreve o que faz a partir do exterior: "compreende melhor a tua consulta", "sintetiza várias fontes", "fornece respostas conversacionais". Estas descrições não estão erradas. Mas são inúteis para a otimização.
O que se segue é o pipeline completo, nomeado componente a componente, com as patentes que regem cada fase. Isto é o que a otimização realmente significa para o alvo - porque não podes melhorar sistematicamente um sistema que não consegues nomear.
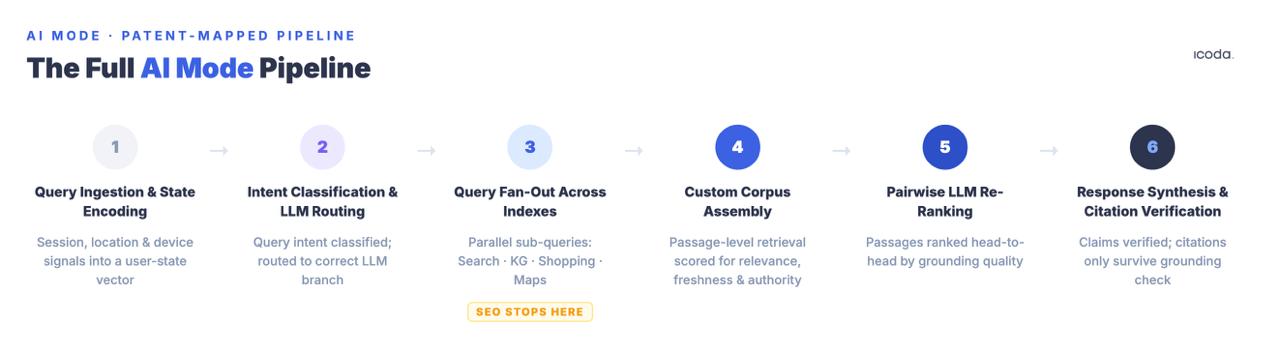
O pipeline de seis fases é o que realmente estás a otimizar. A maioria das práticas actuais aborda uma fase.
Fase 1: Ingestão de consultas e codificação do estado do utilizador
A consulta em bruto não entra diretamente na recuperação. Primeiro, é emparelhada com o vetor de contexto do utilizador - uma incorporação densa criada a partir do histórico de sessões, consultas anteriores em todas as sessões, dispositivo, localização, hora do dia e sinais do ecossistema Google (Pesquisa, Mapas, Gmail, YouTube). Este vetor de personalização modifica o que "esta consulta significa" antes de iniciar qualquer recuperação.
Dois utilizadores que digitem consultas idênticas estão efetivamente a emitir instruções de recuperação diferentes. As implicações deste facto são suficientemente significativas para merecerem uma secção própria - que vem imediatamente a seguir a esta.
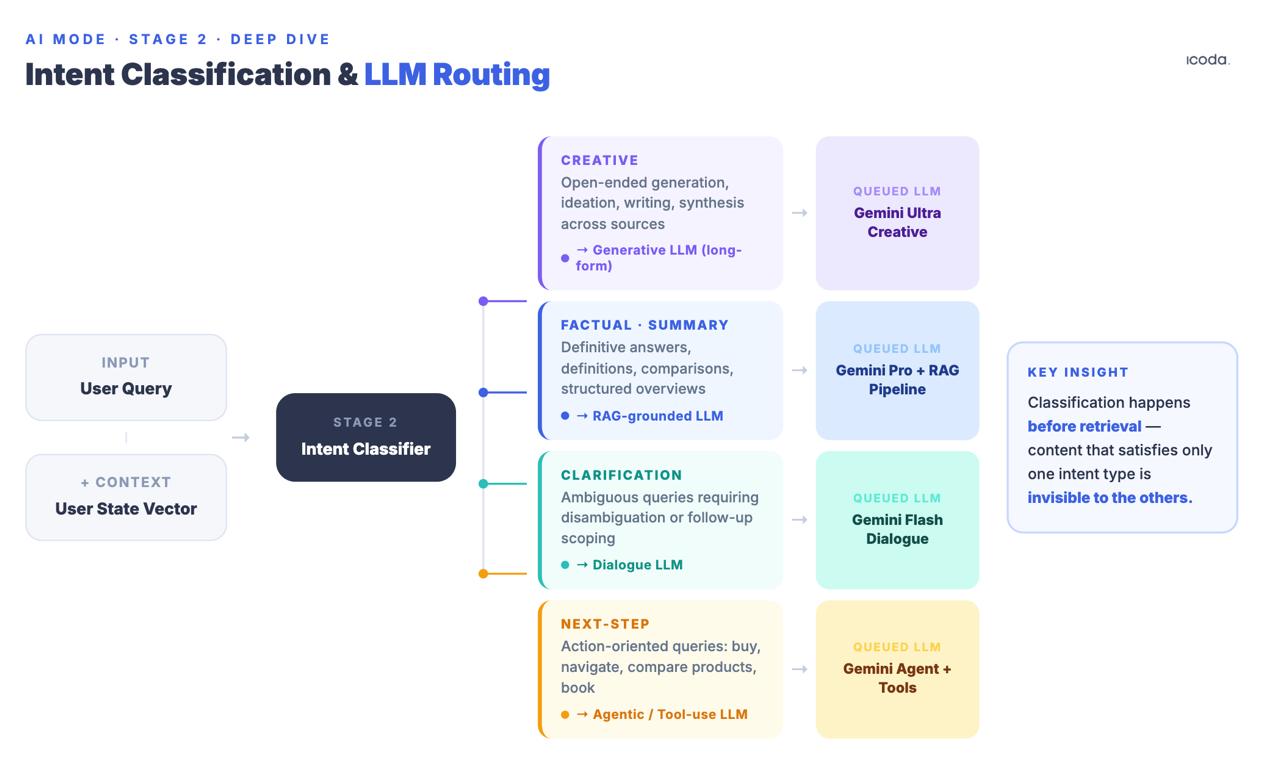
Etapa 2: Classificação da intenção de consulta e roteamento LLM
Antes da recuperação, o sistema classifica a consulta em categorias de intenção: criativa, factual/resumo, esclarecimento ou passo seguinte/tarefa. Com base nesta classificação, são colocados em fila de espera diferentes modelos linguísticos a jusante. A patente Stateful Chat (US20240289407A1) nomeia-os explicitamente: LLM de Texto Criativo, LLM Gerador de SRP, LLM de Esclarecimento, LLM de Próximo Passo.
Isto acontece antes da recuperação. A classificação determina não só qual o modelo que sintetiza a resposta, mas também quais os sinais de recuperação mais importantes. Uma página com uma boa classificação para consultas informativas pode não entrar no conjunto de candidatos se o classificador de intenções encaminhar esta sessão para um LLM de etapa seguinte que optimize a conclusão da tarefa em vez da síntese de informações.
Etapa 3: Consulta Fan-Out
É aqui que o Modo AI diverge mais acentuadamente de todos os sistemas que o precederam.
O sistema gera várias subconsultas sintéticas a partir da original, abrangendo oito tipos de variantes documentadas: equivalentes, relacionadas, implícitas, comparativas, de clarificação, temporais, geográficas e de contexto profissional. Repara na data do registo. Há sete anos que a Google tem vindo a criar fan-out de múltiplas consultas. O AI Mode é o produto final de uma longa trajetória arquitetónica.
Os tipos de variantes "implícitas" e "comparativas" merecem uma atenção especial porque geram consultas que o utilizador não fez, mas que provavelmente necessitará. Se alguém pesquisar "o melhor CRM para startups", o fan-out gera não só reformulações, mas também consultas implícitas ("que CRM é escalável para além da Série A?"), consultas comparativas ("Salesforce vs. HubSpot para empresas em fase inicial"), consultas temporais ("o preço do CRM muda em 2025″) e variantes de contexto profissional que distinguem um fundador a pesquisar de um gestor de RevOps a decidir.
Todas as subconsultas são executadas em simultâneo no índice da Pesquisa Google, no Knowledge Graph, no Shopping Graph e no Maps. A Google confirmou que o Modo IA pode efetuar "centenas de pesquisas" para uma única consulta complexa. A patente da Pesquisa Temática (US12158907B1) organiza os resultados em grupos semânticos; os subtemas desencadeiam rondas de recuperação adicionais de forma iterativa - o que significa que o fan-out pode recursar, e não apenas rebentar uma vez.
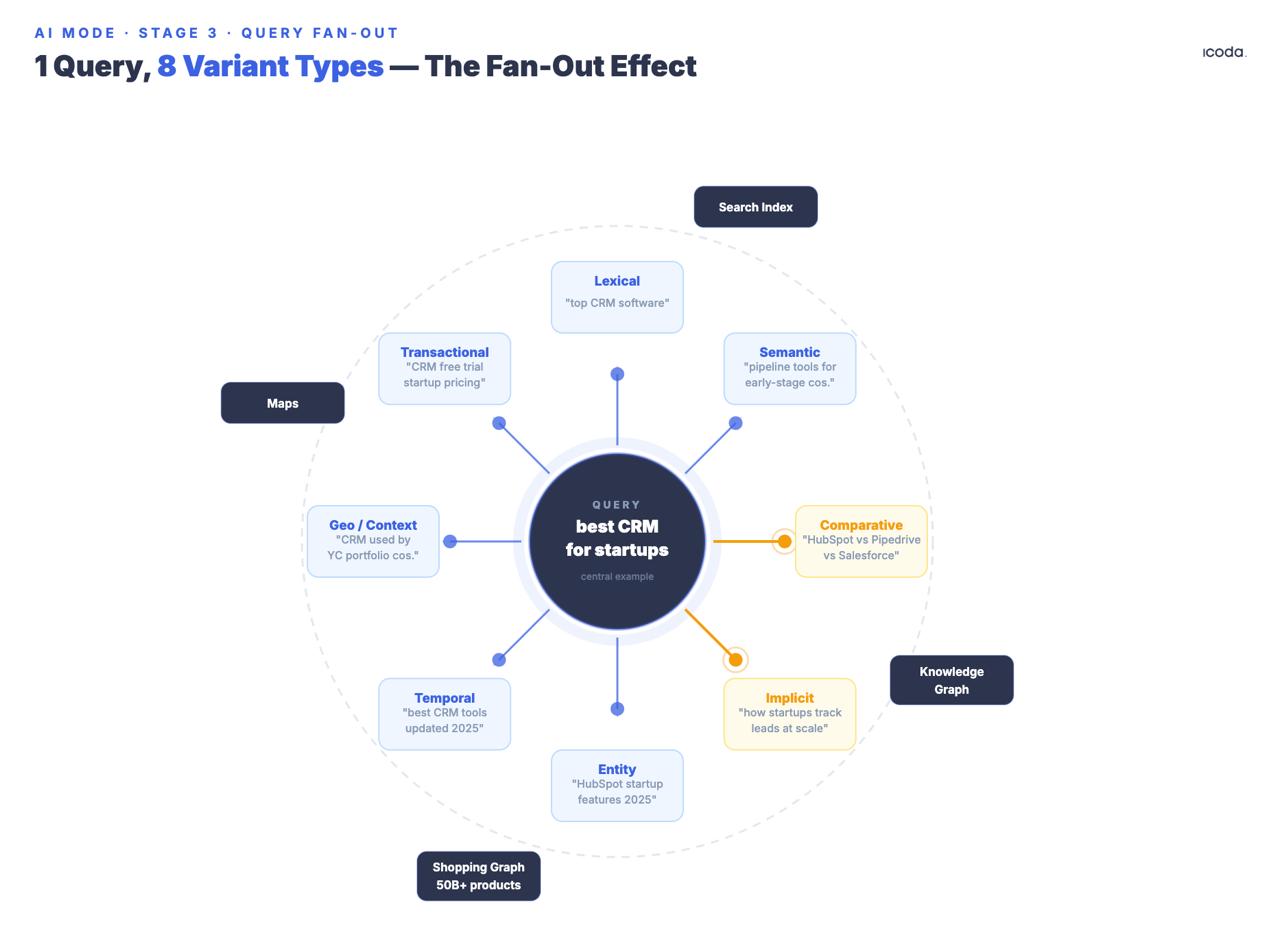
A Google registou a patente fundamental do fan-out em 2018 - o Modo AI é o produto final de uma arquitetura construída ao longo de sete anos.
Uma marca que tenha conteúdo de autoridade sobre o "melhor CRM", mas que não tenha nada de comparativo, nada de temporal e nada que vise variantes de contexto profissional, está ausente de vários tipos de consulta que disparam em todas as sessões relevantes. O fan-out não se preocupa com a autoridade do teu domínio - preocupa-se em saber se cada subconsulta de variantes apresenta uma passagem que ganha a comparação entre pares.
Fase 4: Montagem do corpus personalizado
As passagens recuperadas - não os documentos, mas as passagens - são reunidas num corpus personalizado. A patente WO2024064249A1 descreve como o sistema pode recuperar até cinco partes adjacentes em torno de uma passagem relevante para preservar a coerência contextual. Isto significa que o fluxo da prosa numa secção de um documento é importante. Um argumento bem estruturado que obtenha um resultado de recuperação puxa consigo os parágrafos circundantes para o corpus.
O corpus é personalizado. Cada utilizador, cada sessão, cada consulta produz um corpus diferente. Não existe um conjunto universal de documentos em que o teu conteúdo esteja a competir - existem milhões de conjuntos específicos de utilizadores reunidos a pedido.
Etapa 5: Reclassificação LLM por pares
As passagens de todas as subconsultas de fan-out competem entre si. O mecanismo de classificação não é o BM25. Não é TF-IDF. Um LLM compara as passagens em pares - qual a passagem que melhor satisfaz uma dada subconsulta? - em várias rondas de comparação. Os vencedores avançam; os perdedores saem.
É nesta fase que a maior parte do investimento em SEO não consegue estabelecer contacto. Passagens densas, diretas e factuais que respondem a sub-perguntas específicas na primeira frase ganham claramente as comparações entre pares. O conteúdo narrativo, discursivo e com muitas opiniões - o tipo que tem um bom desempenho em SEO editorial longo - tende a perder, porque faz com que um LLM trabalhe mais para extrair a afirmação relevante. Um tópico do Reddit que começa com uma resposta direta a uma pergunta de nicho pode superar um guia autorizado de 3.000 palavras que enterra a resposta no oitavo parágrafo. O mecanismo de pares recompensa o retorno imediato, não a credibilidade acumulada.
Etapa 6: Síntese de respostas e verificação de citações
As passagens sobreviventes são enviadas para o Gemini. O Gemini gera uma resposta em linguagem natural. Em seguida, o Response Linkifying Engine efectua a verificação ao nível dos fragmentos: faz corresponder cada fragmento da resposta gerada a passagens específicas do corpus e incorpora as citações em linha.
Isto não é uma atribuição ao nível da página. Uma frase na resposta que corresponda a uma passagem no teu blogue ganha uma citação. O resto da tua página pode não ser referenciado de todo. Um artigo factualmente denso de 400 palavras pode citar mais do que um guia autorizado de 3.000 palavras - porque produz mais fragmentos verificáveis por unidade de texto. O mecanismo recompensa estruturalmente a densidade da afirmação em detrimento de uma cobertura abrangente. Isto é uma inversão direta daquilo para que o SEO tradicional de formato longo optimiza.
Principais conclusões: O Modo IA é um pipeline de seis fases. O SEO tradicional aborda principalmente a Fase 3 (elegibilidade de recuperação). A citação é ganha ou perdida nas Fases 4-6 - densidade ao nível da passagem, competição LLM aos pares e fundamentação factual ao nível do fragmento - nenhuma das quais é abordada pela prática de otimização padrão.
A camada de personalização: Porque é que o Rank Tracking está a medir uma ficção
Há um facto incorporado na arquitetura do Modo AI que a indústria de SEO ainda não considerou totalmente. Vamos dizê-lo claramente:
A mesma consulta emitida por dois utilizadores diferentes produz conjuntos de recuperação diferentes. Não são classificações diferentes dos mesmos documentos. Documentos completamente diferentes.
A patente User Embedding Models descreve a forma como a Google codifica sinais comportamentais - consultas, cliques, tempo de permanência, histórico de localização, atividade do Maps, histórico de visualização do YouTube, conteúdo do Gmail - em vectores densos que são emparelhados com cada consulta recebida. O vetor de personalização modifica a recuperação antes de ser aplicado qualquer sinal de classificação tradicional.
Não estás numa corrida contra a concorrência por uma posição universal no ranking. Estás numa corrida pela relevância em contextos de consulta específicos de utilizadores-persona que não podes observar diretamente, não podes medir diretamente e não podes replicar numa ferramenta de seguimento de classificações.
O que alimenta o utilizador Incorporação
A patente Stateful Chat (US20240289407A1) e a patente User Embedding Models descrevem em conjunto uma pilha de personalização a partir de:
- Histórico completo de consultas em todas as sessões da Pesquisa Google (para utilizadores com sessão iniciada)
- Padrões de cliques, de passagem do rato e de permanência à escala comportamental agregada
- Tipo de dispositivo e sinais de localização
- Dados do ecossistema Google: Check-ins no Google Maps, tempo de visualização do YouTube por tópico, conteúdo do Gmail
Vale a pena insistir nesta última categoria. A funcionalidade "Contexto pessoal" - apresentada no Google I/O 2025 e parcialmente implementada no início de 2026 - irá incorporar explicitamente os dados do Gmail, do Calendário e da conta Google diretamente na pesquisa. Quando for totalmente lançada, um utilizador que tenha enviado um e-mail sobre viagens de esqui na semana passada obterá respostas diferentes no Modo de IA para "equipamento de inverno para exteriores" do que alguém que tenha comprado recentemente ténis de corrida no Google Shopping. O conceito de um resultado de pesquisa canónico para qualquer consulta estará funcionalmente morto. Cada resultado será um produto do histórico comportamental do utilizador em todo o ecossistema Google, e não apenas das suas pesquisas.
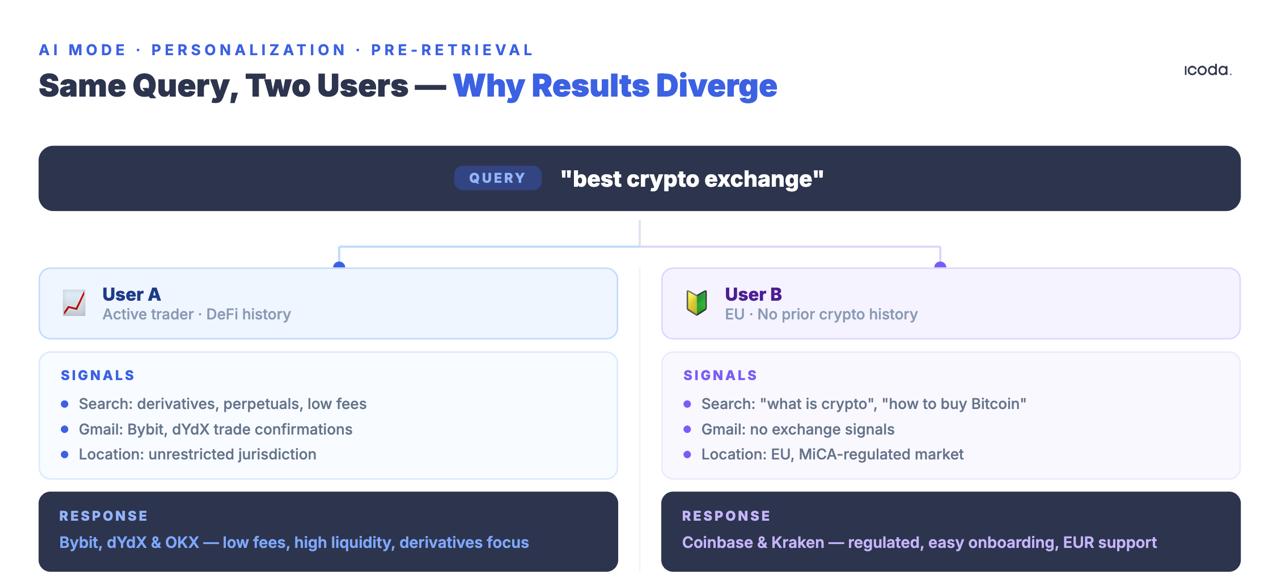
A consequência da medição
As ferramentas de rastreio de classificação consultam a partir de ambientes limpos e descontextualizados. Os utilizadores reais são profundamente contextualizados. A ferramenta mede uma posição hipotética que nenhum utilizador real vê.
Não se trata de uma reclamação de precisão. É uma reclamação de validade. A medição não é imprecisa - está a medir a coisa totalmente errada. Um número de rastreamento de posição de um rastreador de classificação executado contra o Modo AI representa a experiência de um usuário sem histórico de pesquisa, sem sinal de localização, sem dados de ecossistema e sem contexto de sessão. Esse utilizador não existe em qualquer volume significativo.
A decisão antitrust reforça este ponto de uma forma irónica. A solução de dezembro de 2025 exige que a Google partilhe o seu índice de pesquisa com os concorrentes duas vezes ao longo de cinco anos. Mas não pode partilhar os modelos de incorporação do utilizador. Os dados do índice - que agora se estão a tornar um bem de consumo - não são o que impulsiona a personalização do modo IA. O que impulsiona é o volante de aprendizagem: 14 mil milhões de consultas diárias, que alimentam continuamente modelos de incorporação de utilizadores actualizados que nenhum concorrente consegue replicar. Os concorrentes obtêm uma imagem instantânea da prateleira. A Google fica com o bibliotecário que leu o rosto de cada utilizador.
O que realmente funciona para a medição
As marcas mais bem posicionadas para navegar nesta situação não são as que têm o rastreio de classificação de maior fidelidade. São as que aceitaram que a recuperação personalizada de IA requer um paradigma de medição diferente e construíram-no para isso. Os quatro proxies que têm um sinal real:
Partilha da voz da marca nas respostas da IA, monitorizada através de ferramentas de terceiros (Profound, ZipTie, Ahrefs Brand Radar). Aproximações baseadas em amostragem, não cobertura completa - mas medem a presença de citações, que é a variável de saída correta. Acompanha isto em relação aos concorrentes, não em relação a uma pontuação absoluta.
Dissociação entre impressão/clique no GSC ao nível do segmento de consulta. As consultas informativas que mostram impressões crescentes com CTR em declínio são a principal assinatura visível da canibalização do Modo IA. Segmenta por tipo de intenção; vê a divergência acentuar-se ao longo do tempo.
Auditorias manuais de citações no modo IA para as tuas 20 consultas mais importantes do ponto de vista comercial. Observa que páginas são citadas, que passagens aparecem na resposta e se a tua marca aparece em subconsultas de fan-out focadas na concorrência - porque por vezes aparece. O Modo de IA gera, em média, 3,3 menções de entidades por resposta, em comparação com 1,3 para as Visões gerais de IA. A tua marca pode estar presente em sessões em que o teu domínio nunca é clicado.
Volume de pesquisa de marca como um sinal a jusante. Se o modo de IA estiver a gerar conhecimento da marca sem gerar cliques diretos - o que a arquitetura sugere que acontece cada vez mais - o volume de pesquisa de marca deve mover-se como um indicador de atraso ao longo de um período de 60-90 dias.
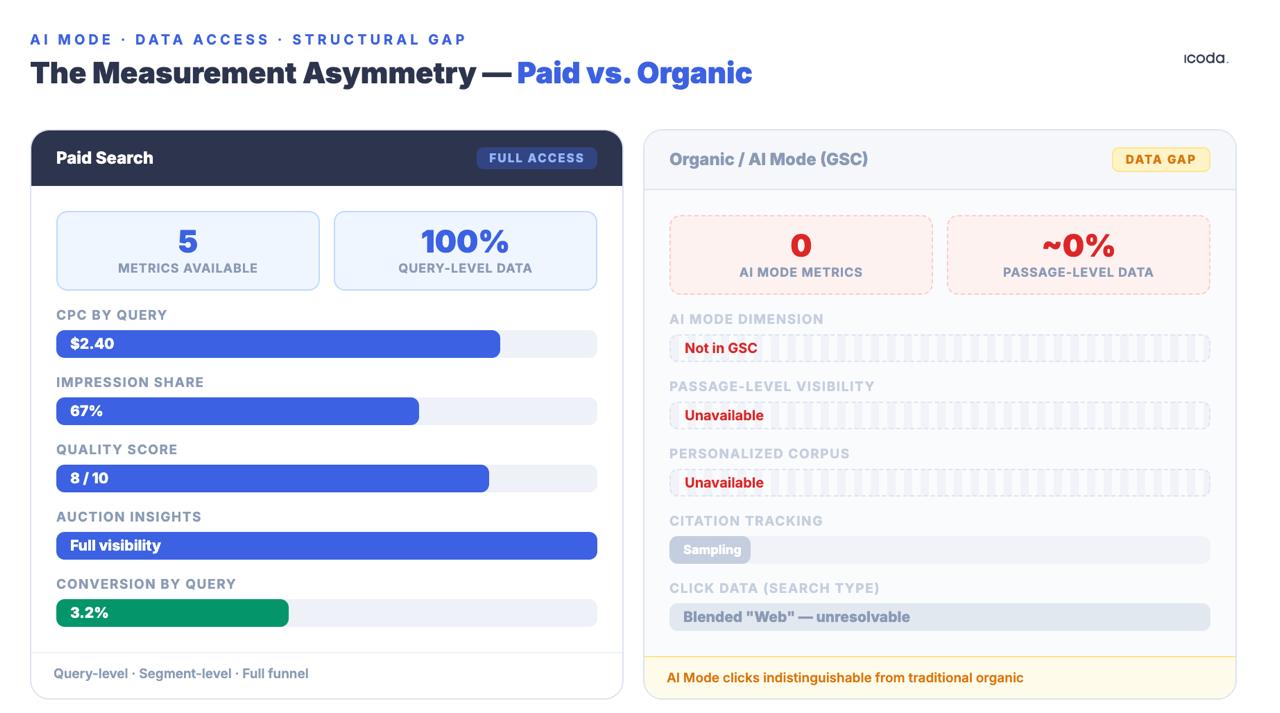
A diferença de medição entre a pesquisa paga e a pesquisa orgânica existe há anos. O modo IA aumentou-o para um abismo estrutural.
Nenhum deles é perfeito. A assimetria com as equipas de pesquisa paga é estrutural e significativa: as equipas pagas têm dados de CPC, quota de impressões, índices de qualidade e informações sobre leilões ao nível da consulta. As equipas orgânicas obtêm dados de GSC que são deliberadamente agregados, amostrados e anonimizados - e os cliques no Modo IA são misturados no tipo de pesquisa genérico "Web", indistinguível do tráfego orgânico tradicional. Esta lacuna não é um problema temporário de ferramentas. É uma decisão deliberada da arquitetura do produto e está a aumentar à medida que o Modo AI torna a pesquisa orgânica mais opaca, e não menos.
A resposta honesta é que atualmente não podes medir com precisão a visibilidade do teu Modo IA. Podes medir os proxies. Podes controlar a presença da marca. Podes observar a deterioração da relação impressão/clique em tempo real e utilizá-la para definir prioridades. Mas não deves confundir a medição de proxies com a verdade em terra - e deves parar de fingir que um rastreador de classificação apontado para uma consulta não contextualizada te diz algo significativo sobre como um utilizador real, com sessão iniciada e contextualizado experimenta o teu conteúdo no Modo AI.
Conclusão principal: Os vectores de incorporação do utilizador modificam a recuperação do Modo IA antes de se aplicarem os sinais de classificação clássicos, tornando o seguimento da classificação - tal como é praticado atualmente - uma medição de um utilizador que não existe. Muda a medição primária da posição para a quota de voz da marca nas respostas da IA, complementada por sinais de dissociação do GSC e auditorias manuais de citações.
Conclusão
O Modo de IA não é uma Pesquisa Clássica mais inteligente. É um sistema de recuperação separado - seis fases, ao nível da passagem, personalizado antes de se aplicar qualquer sinal de classificação - e já está a decidir que marcas existem nas respostas que o teu público está a ler.
A sobreposição de 14% de citações com os resultados tradicionais do top 10 diz-te tudo: a classificação e as citações são agora variáveis independentes. Podes ocupar a primeira página e ser invisível no modo IA. Podes ficar na posição 47 e ganhar citações consistentes se o teu conteúdo produzir passagens que ganham comparações LLM em pares para as variantes de subconsulta certas.
A arquitetura está documentada. As patentes são públicas. A janela de adaptação antes que o Modo IA se torne a experiência de pesquisa padrão é medida em trimestres, não em anos.
O que acontece a seguir é uma escolha.
Partilhar


Avaliar o artigo












