Se tens verificado os registos do teu servidor ultimamente, há uma boa hipótese de teres visto um visitante chamado ClaudeBot. Não é um cliente. Não é um hacker. É o web crawler da Anthropic - e tem estado a ler discretamente o teu site para ajudar a treinar um dos modelos de IA mais avançados do planeta.
Se geres um produto SaaS, uma loja de comércio eletrónico, um site de media ou um projeto de blockchain, compreender o que o ClaudeBot faz (e não faz) já não é opcional. À medida que a pesquisa com IA remodela a forma como os utilizadores descobrem conteúdos, a forma como interages com estes rastreadores tem um impacto direto no facto de a tua marca aparecer nas respostas geradas pela IA - ou desaparecer completamente delas.
Este guia explica tudo o que precisas de saber: o que é o ClaudeBot, como se identifica, como controlar o seu acesso com precisão cirúrgica e porque é que as tuas decisões aqui podem moldar a visibilidade da IA da tua marca nos próximos anos.
ClaudeBot vs. ClawdBot: Não são a mesma coisa
O ClaudeBot é o web crawler oficial do Anthropic- um bot que recolhe conteúdos publicamente disponíveis para treinar e melhorar a família Claude de modelos de IA. O ClawdBot (agora renomeado como OpenClaw) foi um agente de IA de código aberto criado pelo programador austríaco Peter Steinberger. Não partilham nada para além de um nome vagamente semelhante.
A confusão é compreensível. Steinberger lançou originalmente o seu projeto como "Clawdbot" em novembro de 2025, um assistente pessoal de IA que poderia automatizar tarefas em plataformas de mensagens como o WhatsApp, Telegram e Discord. Mas a Anthropic apresentou queixas sobre a marca registada e, em dois meses, o projeto foi renomeado - primeiro para "Moltbot" e depois para "OpenClaw" no final de janeiro de 2026.
Aqui está a distinção fundamental:
- O ClaudeBot é um rastreador da Web. Lê as páginas do teu site para recolher dados de treino para os modelos de linguagem de grande dimensão do Anthropic. Aparece nos registos do teu servidor com uma sequência específica de agente de utilizador e respeita as diretivas robots.txt.
- O OpenClaw (anteriormente ClawdBot/MoltBot) é um agente de IA. Funciona no dispositivo de um utilizador e executa tarefas - enviar e-mails, gerir calendários, navegar na Web - em nome de um operador humano. Não rastreia sítios Web para obter dados de treino.
Se vires ClaudeBot nos teus registos de acesso, isso é Anthropic. Se alguém mencionar "ClawdBot" numa conversa sobre assistentes autónomos de IA, está a falar do OpenClaw. Não confundas os dois quando configurares o teu robots.txt - bloquear um não tem qualquer efeito sobre o outro.
O que é o ClaudeBot? Explica o rastreador de treino do Anthropic
O ClaudeBot é o principal rastreador da Web do Anthropic, concebido para recolher conteúdos publicamente disponíveis que podem ser utilizados para treinar e melhorar os modelos de IA generativa que alimentam o Claude. Percorre sistematicamente a Internet, seguindo ligações e mapas de sítios para descobrir e descarregar páginas Web.
Ao contrário dos rastreadores de motores de busca tradicionais, como o Googlebot, que indexam páginas para que possam aparecer nos resultados de pesquisa, o ClaudeBot recolhe conteúdos especificamente para fins de aprendizagem automática. Os dados que recolhe alimentam o pipeline de desenvolvimento de modelos do Anthropic, ajudando o Claude a compreender a linguagem, o contexto e os tópicos com nuances em todos os domínios.
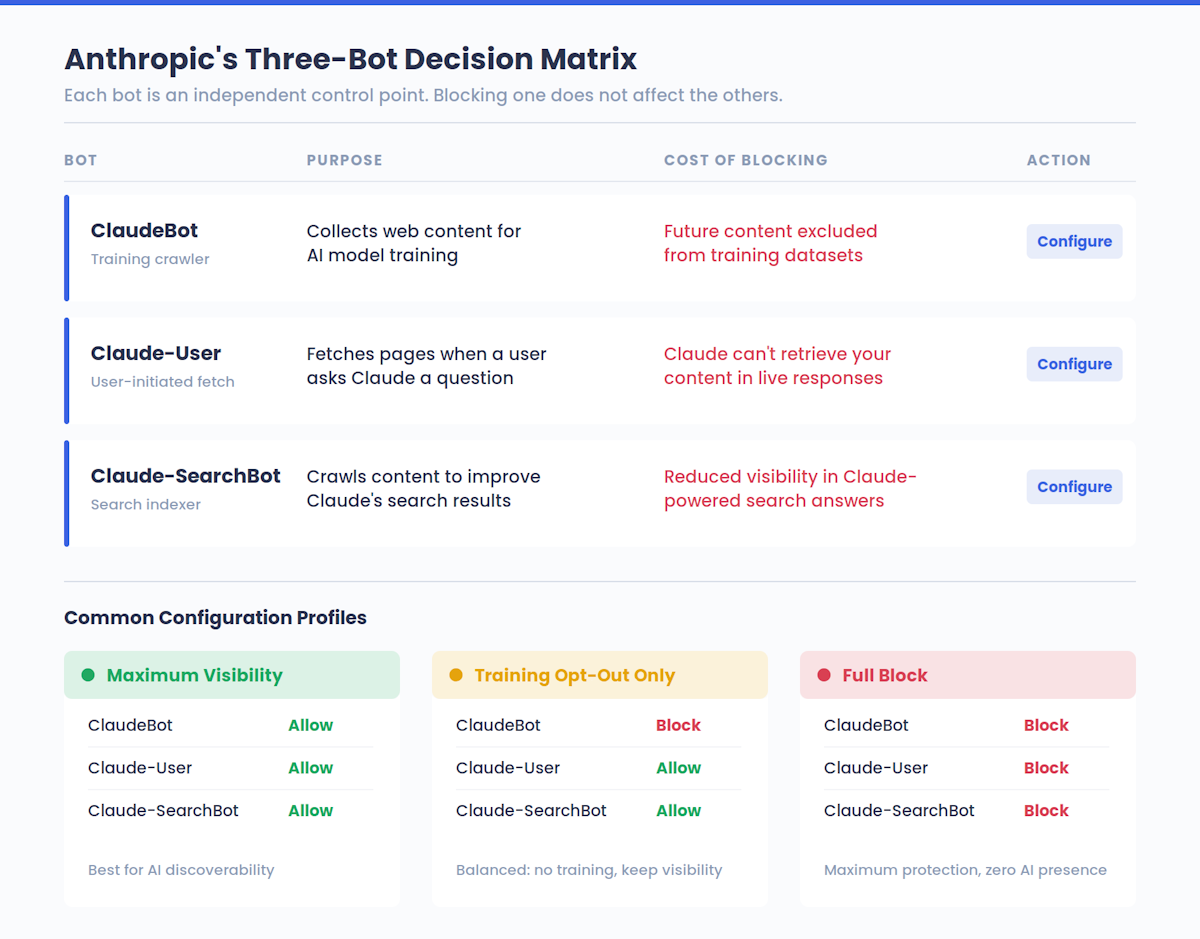
Na verdade, o Anthropic opera três bots distintos, cada um com uma função diferente:
| Nome do Bot | Objetivo | O que faz o bloqueio |
|---|---|---|
| ClaudeBot | Recolhe conteúdos da Web para o treino de modelos de IA | Exclui o teu conteúdo futuro dos conjuntos de dados de treino |
| Claude-Usuário | Procura páginas quando um utilizador do Claude faz uma pergunta | Impede que o Claude recupere o teu conteúdo em respostas em tempo real |
| Claude-SearchBot | Analisa os conteúdos para melhorar a qualidade dos resultados de pesquisa do Claude | Reduz a tua visibilidade nas respostas de pesquisa com o Claude |
Esta separação é importante. Bloquear o ClaudeBot de treinar no teu conteúdo não impede que os utilizadores do Claude vejam as tuas páginas em respostas em tempo real - isso é tratado pelo Claude-User. E o bloqueio do Claude-SearchBot não afeta o treinamento. Cada bot é um ponto de controle independente, dando aos proprietários de sites opções granulares sobre como o Anthropic interage com seu conteúdo.
Essa terceira coluna tem consequências estratégicas reais - mais à frente neste guia, vamos analisar todas as compensações de visibilidade. Mas a versão resumida: a maioria dos proprietários de sítios Web não faz ideia de qual é a sua posição atual em relação às plataformas de IA. Se quiseres uma linha de base antes de mudares alguma coisa, verifica a tua pontuação de visibilidade de IA para ver como sua marca aparece no Claude e em outros sistemas de IA no momento.
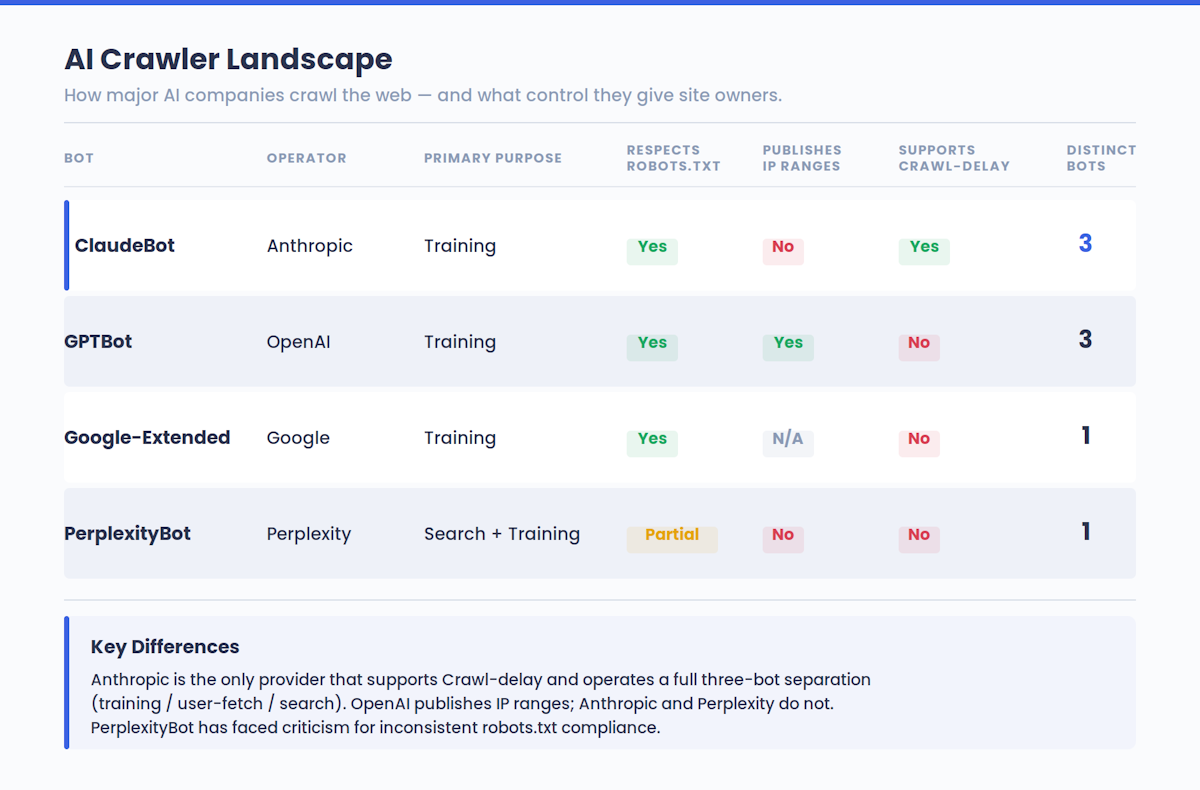
O Anthropic afirmou que o seu objetivo é ser transparente e não perturbador. Os bots respeitam as diretivas robots.txt, respeitam as tecnologias anti-circunvenção, como os CAPTCHAs, e suportam a extensão não-padrão Crawl-delay para limitação de taxas.
ClaudeBot User-Agent String: Como identificá-la nos teus registos
O ClaudeBot identifica-se com o token de agente de utilizador ClaudeBot e inclui um e-mail de contacto na sua cadeia completa de agente de utilizador. Aqui está a cadeia completa que verás nos registos de acesso ao teu servidor:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Alguns pormenores técnicos dignos de nota:
- O token de agente de utilizador para fins de robots.txt é simplesmente
ClaudeBot. É essa a cadeia de caracteres que referencias nas tuas diretivas. - O Anthropic funcionava anteriormente com as cadeias de caracteres de agente de utilizador
Claude-WebeAnthropic-AI. Ambas estão agora obsoletas. Se o teu robots.txt ainda faz referência a estas strings antigas, as tuas diretivas já não são eficazes contra os actuais crawlers do Anthropic. - Os outros dois bots utilizam os seus próprios tokens:
Claude-Userpara a pesquisa de páginas iniciada pelo utilizador eClaude-SearchBotpara a indexação da pesquisa.
Para verificar rapidamente se o ClaudeBot visitou o teu site, executa um grep nos teus registos de acesso:
grep "ClaudeBot" /var/log/nginx/access.log
Ou para o Apache:
grep "ClaudeBot" /var/log/apache2/access.log
Se estás a ver visitas de um agente de utilizador que afirma ser o ClaudeBot, vale a pena verificar a autenticidade (mais sobre a verificação de IP abaixo). As cadeias de caracteres de agente de utilizador podem ser falsificadas e, por vezes, os maus actores fazem-se passar por crawlers legítimos para recolher conteúdo sem restrições.
Como permitir ou bloquear o ClaudeBot em robots.txt
Controlas o acesso do ClaudeBot através das diretivas padrão robots.txt colocadas no diretório raiz do teu site. Este é o método recomendado pela Anthropic - e o único que eles garantem que funcionará de forma fiável.
Bloqueia o ClaudeBot de todo o teu site
User-agent: ClaudeBot
Disallow: /
Isto diz ao ClaudeBot que não pode aceder a nenhuma página do teu domínio. A Anthropic afirma que, quando um site bloqueia o ClaudeBot, sinaliza que o conteúdo futuro do site deve ser excluído dos conjuntos de dados de treino do modelo de IA.
Permite o acesso total ao ClaudeBot
User-agent: ClaudeBot
Allow: /
Ou simplesmente não incluas nenhuma diretiva ClaudeBot - o comportamento por defeito é permitir o rastreio.
Abranda a taxa de rastreio do ClaudeBot
User-agent: ClaudeBot
Crawl-delay: 10
Isto pede ao ClaudeBot para esperar 10 segundos entre pedidos, reduzindo a carga do servidor sem bloquear totalmente o acesso.
Bloqueia os três bots Anthropic de uma só vez
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-User
Disallow: /
User-agent: Claude-SearchBot
Disallow: /
Importante: Lembra-te de aplicar estas regras a todos os subdomínios que pretendes proteger. Um robots.txt em example.com não abrange docs.example.com ou blog.example.com.
Além disso, tira um momento para auditar o teu robots.txt existente para as strings obsoletas Claude-Web e Anthropic-AI. Se estas ainda estiverem no teu ficheiro, não estão a fazer nada contra os actuais crawlers do Anthropic. Substitui-as pelos três nomes de bots activos listados acima.
Acesso parcial: Permitir o teu blogue, bloquear o teu administrador
Não tens de tomar uma decisão do tipo "tudo ou nada" - o robots.txt suporta regras ao nível do caminho que te permitem abrir secções específicas e manter outras bloqueadas. Esta é a jogada inteligente para qualquer empresa que pretenda visibilidade de treino de IA para o seu conteúdo público, mas que precise de proteger áreas sensíveis.
Aqui está uma configuração prática que funciona para a maioria dos sites - quer estejas a gerir uma plataforma SaaS, uma loja online ou um projeto de criptografia:
User-agent: ClaudeBot
Disallow: /admin/
Disallow: /dashboard/
Disallow: /api/
Disallow: /members/
Disallow: /internal/
Allow: /blog/
Allow: /docs/
Allow: /about/
Allow: /
Nessa configuração, o ClaudeBot pode acessar suas postagens de blog, documentação e páginas públicas, tornando esse conteúdo disponível para treinamento de IA e aumentando a chance de o Claude fazer referência à sua marca nas respostas. Enquanto isso, os painéis de administração, os pontos de extremidade da API e as áreas somente para membros permanecem fora dos limites.
Alguns padrões comuns de acesso parcial:
- Lojas de comércio eletrónico: Permite páginas de produtos, páginas de categorias e guias de compra; bloqueia as áreas de carrinho, checkout e conta.
- Plataformas SaaS: Permite páginas de marketing, preços e documentos; bloqueia dashboards de aplicações, definições e rotas de API.
- Editores de conteúdos: Permitir artigos e páginas de categorias; bloquear páginas de resultados de pesquisa e secções de conteúdos gerados pelo utilizador para evitar que conteúdos pouco relevantes ou duplicados entrem no conjunto de treino.
- Projectos Crypto e Web3: Permite documentação, blogue e explicadores de protocolos; bloqueia painéis de administração, ferramentas internas e áreas de comunidade fechadas.
Lembra-te que as regras Allow e Disallow são avaliadas por especificidade - os caminhos mais específicos têm precedência. A diretiva Disallow: /admin/ bloqueará /admin/settings mesmo que exista uma Allow: / mais ampla.
Como verificar os endereços IP do ClaudeBot
A Anthropic não publica uma lista fixa de intervalos de IP para os seus rastreadores da Web e a empresa desaconselha o recurso ao bloqueio baseado em IP como a tua principal defesa. Os seus bots operam através de uma infraestrutura de nuvem pública, o que significa que os endereços IP podem mudar. O bloqueio de intervalos de IP também pode impedir o bot de ler o teu robots.txt, o que pode levar a um comportamento de rastreio não intencional.
Dito isto, o Anthropic fornece uma lista de referência para verificação do IP. Se um crawler afirma ser ClaudeBot e o seu IP de origem aparece na lista publicada pelo Anthropic, isso confirma que o crawler é genuinamente do Anthropic. Podes encontrar esta lista na documentação de suporte oficial do Anthropic.
Para verificar pedidos individuais, uma pesquisa DNS inversa é a tua melhor ferramenta:
# Step 1: Reverse DNS lookup on the crawler's IP
host 216.73.216.1
# Step 2: Forward DNS to confirm
host [result-from-step-1]
Se o DNS reverso resolver para um domínio associado ao Anthropic (ou à sua infraestrutura de nuvem), o pedido é provavelmente genuíno. Se resolver para um domínio não relacionado ou falhar completamente, podes estar a olhar para um agente de utilizador falsificado - alguém a fazer-se passar pelo ClaudeBot.
Para uma monitorização mais alargada, considera estas abordagens:
- Análise dos registos do servidor: Analisa regularmente os teus registos em busca de entradas
ClaudeBote cruza os IPs com a lista publicada pela Anthropic. - Plataformas de deteção de bots: Serviços como Known Agents (anteriormente Dark Visitors) e PlainSignal oferecem análises de agentes em tempo real que podem autenticar visitas de rastreadores e sinalizar tráfego falsificado.
- Regras de proxy reverso: Ferramentas como o Cloudflare e o Nginx permitem-te criar regras condicionais que verificam as declarações do agente do utilizador em relação a intervalos de IP conhecidos antes de concederem acesso.
Conclusão: utiliza o robots.txt como mecanismo de controlo principal e utiliza a verificação de IP como verificação de autenticidade suplementar, e não o contrário.
Como é que o ClaudeBot afecta a visibilidade da tua IA
Cada decisão que tomas sobre o acesso ao ClaudeBot tem um impacto direto no facto de a tua marca aparecer nas respostas geradas por IA - um canal que está a tornar-se rapidamente tão importante como a pesquisa tradicional. É aqui que a gestão técnica dos rastreadores se encontra com a estratégia de crescimento.

Eis a troca em termos simples:
- Permite o ClaudeBot → O teu conteúdo entra no pipeline de formação do Anthropic. É mais provável que o Claude faça referência à tua marca, explique o teu produto ou recomende os teus serviços quando os utilizadores fazem perguntas relevantes.
- Bloqueia o ClaudeBot → O teu conteúdo futuro é excluído da formação. O conhecimento que o Claude tem da tua marca fica estagnado no que foi recolhido antes do bloqueio. Com o tempo, os concorrentes que permitem o rastreio ganham uma vantagem crescente nas recomendações geradas por IA.
Esta dinâmica está a ser aplicada em todo o panorama da IA, e não apenas no Claude. O GPTBot da OpenAI, os crawlers de IA da Google e o bot da Perplexity funcionam sob uma lógica semelhante. Os sítios que participam no treino da IA são os que são citados nas respostas da IA.
O que está em jogo é concreto em todos os sectores:
- Fundadores de SaaS: Quando um potencial cliente pergunta ao Claude "Qual é a melhor ferramenta de gestão de projectos para equipas remotas?", a resposta baseia-se no que o Claude aprendeu. Se os teus documentos, as tuas páginas de comparação e a análise das caraterísticas fizeram parte dessa aprendizagem, estás na recomendação. Se não fizeram, o teu concorrente está.
- Operadores de comércio eletrónico: Um comprador que pergunte "Qual é o melhor sapato de corrida para pés chatos?" obtém uma resposta moldada por páginas de produtos e guias de compra que a Claude ingeriu. As marcas que bloquearam o crawler não aparecem nessa resposta.
- Editores e sites de media: Quando os utilizadores pedem ao Claude para explicar um tópico de tendência, este sintetiza a partir de fontes que conhece. Se a tua reportagem e análise estavam nos dados de treino, o Claude cita o teu enquadramento. Caso contrário, a narrativa de outra pessoa domina.
- Projectos Crypto e Web3: Quando um investidor pergunta "Quais são as melhores soluções de Camada 2?" ou "Como funciona [o teu protocolo]?", a resposta reflecte o que Claude aprendeu com a documentação do protocolo e com as publicações no blogue. Se a tua foi excluída, és invisível para esse público.
Em todos os casos, o padrão é idêntico: o conteúdo a que Claude pode aceder torna-se o conteúdo que Claude recomenda.
O conceito de visibilidade da IA - a forma como a tua marca aparece de forma proeminente e precisa nas plataformas alimentadas por IA - está a emergir como uma disciplina distinta a par do SEO tradicional. Requer a sua própria auditoria, a sua própria estratégia e a sua própria monitorização. E ao contrário do SEO tradicional, onde podes acompanhar as classificações na Consola de Pesquisa do Google, a visibilidade da IA tem sido uma caixa negra para a maioria das equipas - até agora.
Mede antes de decidir
A pior coisa que podes fazer é alterar cegamente a configuração do ClaudeBot. Antes de permitir ou bloquear qualquer um dos três crawlers do Anthropic, precisas de uma linha de base: Quantas vezes é que o Claude menciona a tua marca hoje? Descreve o teu produto com precisão? Recomenda os concorrentes?
A ferramenta de visibilidade de IA da ICODA responde a estas perguntas em minutos. Analisa a forma como a sua marca aparece nas principais plataformas de IA - Claude, ChatGPT, Perplexity, Gemini - e dá-lhe uma imagem clara da sua posição atual. Com esses dados, podes tomar decisões informadas sobre quais os bots que deves permitir, quais os que deves bloquear e quais as secções do teu site a que deves dar prioridade para a capacidade de descoberta da IA.
Verifica a tua pontuação de visibilidade da IA agora →
Principais conclusões
Gerir o ClaudeBot já não é uma tarefa de administração de sistemas de nicho - é uma decisão estratégica que afecta a capacidade de descoberta da tua marca na era da IA. Aqui está o que deves lembrar:
- O ClaudeBot é o rastreador de treino do Anthropic, separado do agente OpenClaw (anteriormente ClawdBot/MoltBot) e do Claude-User e Claude-SearchBot.
- Usa o robots.txt como o teu principal mecanismo de controlo. Os bots do Anthropic respeitam estas diretivas de forma fiável.
- Audita o teu robots.txt para ver se existem cadeias de caracteres obsoletas (
Claude-Web,Anthropic-AI) e substitui-as porClaudeBot,Claude-User, eClaude-SearchBot. - Utiliza regras de acesso parcial para partilhar o teu conteúdo público, protegendo as áreas sensíveis.
- Não confies apenas no bloqueio de IP - o Anthropic utiliza uma infraestrutura de nuvem com IPs variáveis e não publica intervalos fixos de rastreadores.
- Mede primeiro a tua visibilidade da IA - utiliza a Ferramenta de Visibilidade da IA da ICODA para estabelecer uma linha de base antes de fazeres quaisquer alterações no acesso aos rastreadores.
- Pensa estrategicamente: o bloqueio dos rastreadores de IA protege o teu conteúdo, mas reduz a visibilidade da IA. A melhor abordagem equilibra ambas as preocupações com base em dados reais.
As empresas que compreendem este equilíbrio - medindo a sua pegada de IA, partilhando seletivamente os seus melhores conteúdos com os crawlers e protegendo o que precisa de ser protegido - são as que vão dominar tanto a pesquisa tradicional como as caixas de respostas geradas por IA de amanhã.
Perguntas frequentes (FAQ)
O rastreio de páginas públicas não requer consentimento - a mesma regra aplica-se ao Googlebot. Adiciona Disallow: / sob User-agent: ClaudeBot em robots.txt e ele pára imediatamente. Se o problema for a largura de banda e não o princípio, Crawl-delay: 10 limita a frequência sem bloquear o acesso.
Bloquear o ClaudeBot não tem qualquer efeito nas classificações do Google - é o rastreador do Anthropic, totalmente separado da infraestrutura do Google. A verdadeira contrapartida é a visibilidade da IA: o conteúdo excluído do índice do ClaudeBot não aparecerá nas respostas do Claude. Trata-se de um problema diferente do SEO, mas cada vez mais importante.
O ClaudeBot autêntico identifica-se como ClaudeBot/1.0 com claudebot@anthropic.com na cadeia do agente de utilizador. Verifica executando uma pesquisa DNS inversa no IP de origem - deve resolver para a infraestrutura associada ao Anthropic. O Anthropic também publica uma lista de IPs de referência em seus documentos oficiais.
Cada bot serve um propósito distinto: ClaudeBot recolhe dados de treino, Claude-User vai buscar páginas para respostas em tempo real, Claude-SearchBot alimenta a sua funcionalidade de pesquisa. Bloquear apenas o ClaudeBot pára o treino mas deixa os outros dois activos. Para cortar o Anthropic completamente, os três precisam de regras explícitas em Disallow.
Um bloqueio geral exclui-te completamente das recomendações geradas pela IA. Quando os utilizadores perguntam ao Claude ou ao ChatGPT "qual é a melhor ferramenta para X", as respostas baseiam-se no que os modelos aprenderam - os sites que bloquearam os rastreadores não aparecem. O bloqueio seletivo por caminho é normalmente mais inteligente do que uma decisão do tipo "tudo ou nada".
As regras robots.txt ao nível do caminho tratam exatamente disto. Utiliza Disallow: /dashboard/ e Disallow: /api/ juntamente com Allow: /blog/ - os caminhos mais específicos têm precedência. Nota: um robots.txt em example.com não abrange app.example.com; os subdomínios precisam do seu próprio ficheiro.
Vale a pena dedicar-lhe cinco minutos de atenção. As respostas geradas por IA são um canal de descoberta real e crescente - a tua posição no robots.txt determina se o teu conteúdo aparece nelas. O erro não é optar por bloquear ou permitir; é não ter uma posição deliberada.
Partilhar


Avaliar o artigo












