Si has revisado últimamente los registros de tu servidor, es muy probable que hayas visto a un visitante llamado ClaudeBot. No es un cliente. No es un hacker. Es el rastreador web de Anthropic, y ha estado leyendo silenciosamente tu sitio web para ayudar a entrenar uno de los modelos de IA más avanzados del planeta.
Tanto si diriges un producto SaaS, una tienda de comercio electrónico, un sitio web de medios de comunicación o un proyecto de blockchain, comprender lo que hace (y lo que no hace) ClaudeBot ya no es opcional. A medida que la búsqueda impulsada por la IA reconfigura la forma en que los usuarios descubren contenidos, la forma en que interactúas con estos rastreadores influye directamente en si tu marca aparece en las respuestas generadas por la IA, o desaparece por completo de ellas.
Esta guía desglosa todo lo que necesitas saber: qué es ClaudeBot, cómo se identifica, cómo controlar su acceso con precisión quirúrgica y por qué tus decisiones aquí podrían dar forma a la visibilidad de la IA de tu marca en los próximos años.
ClaudeBot vs. ClawdBot: No son lo mismo
ClaudeBot es el rastreador web oficial de Anthropic, un bot que recopila contenidos disponibles públicamente para entrenar y mejorar la familia Claude de modelos de IA. ClawdBot (ahora rebautizado como OpenClaw) era un agente de IA de código abierto creado por el desarrollador austriaco Peter Steinberger. No comparten nada más allá de un nombre vagamente similar.
La confusión es comprensible. Steinberger lanzó originalmente su proyecto como "Clawdbot" en noviembre de 2025, un asistente personal de IA que podría automatizar tareas en plataformas de mensajería como WhatsApp, Telegram y Discord. Pero Anthropic presentó una reclamación de marca y en dos meses el proyecto cambió de nombre, primero a "Moltbot" y luego a "OpenClaw" a finales de enero de 2026.
He aquí la distinción clave:
- ClaudeBot es un rastreador web. Lee las páginas de tu sitio web para recopilar datos de entrenamiento para los grandes modelos lingüísticos de Anthropic. Aparece en los registros de tu servidor con una cadena de agente de usuario específica y respeta las directivas robots.txt.
- OpenClaw (antes ClawdBot/MoltBot) es un agente de IA. Se ejecuta en el dispositivo de un usuario y realiza tareas -enviar correos electrónicos, gestionar calendarios, navegar por la web- en nombre de un operador humano. No rastrea sitios web para obtener datos de entrenamiento.
Si ves ClaudeBot en tus registros de acceso, eso es Anthropic. Si alguien menciona "ClawdBot" en una conversación sobre asistentes autónomos de IA, está hablando de OpenClaw. No confundas los dos cuando configures tu robots.txt: bloquear uno no tiene ningún efecto sobre el otro.
¿Qué es ClaudeBot? Explicación del rastreador de entrenamiento de Anthropic
ClaudeBot es el principal rastreador web de Anthropic, diseñado para recopilar contenidos disponibles públicamente que puedan utilizarse para entrenar y mejorar los modelos generativos de IA que impulsan a Claude. Recorre Internet sistemáticamente, siguiendo enlaces y mapas de sitios para descubrir y descargar páginas web.
A diferencia de los rastreadores tradicionales de los motores de búsqueda, como Googlebot, que indexan las páginas para que aparezcan en los resultados de las búsquedas, ClaudeBot recopila contenidos específicamente con fines de aprendizaje automático. Los datos que recoge alimentan el proceso de desarrollo de modelos de Anthropic, ayudando a Claude a comprender el lenguaje, el contexto y los matices de los temas en todos los dominios.
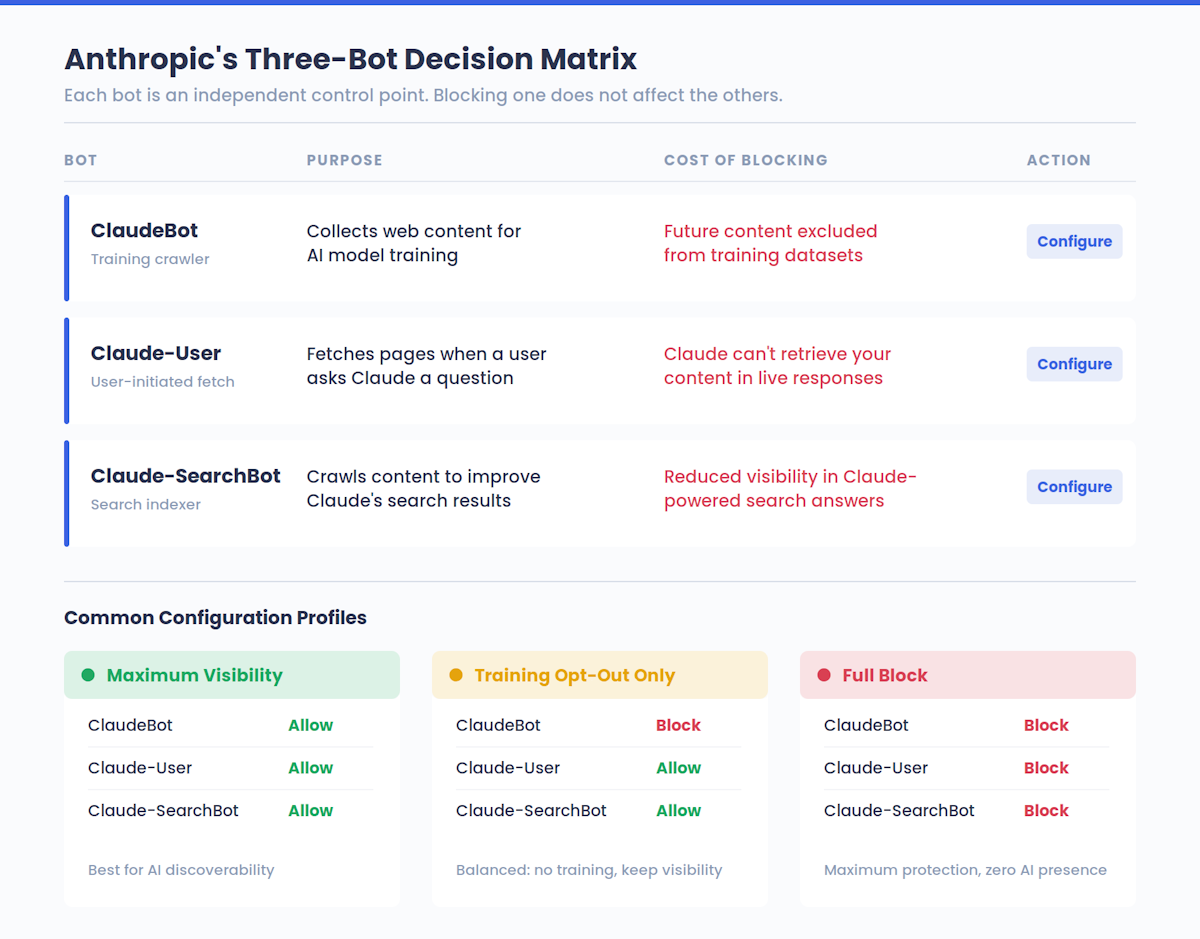
En realidad, Anthropic opera con tres robots distintos, cada uno con una función diferente:
| Nombre Bot | Propósito | Qué hace el bloqueo |
|---|---|---|
| ClaudeBot | Recoge contenidos web para el entrenamiento de modelos de IA | Excluye tus contenidos futuros de los conjuntos de datos de entrenamiento |
| Claude-Usuario | Obtiene páginas cuando un usuario Claude hace una pregunta | Evita que Claude recupere tu contenido en respuestas en tiempo real |
| Claude-BuscarBot | Rastrea el contenido para mejorar la calidad de los resultados de búsqueda de Claude | Reduce tu visibilidad en las respuestas de búsqueda potenciadas por Claude |
Esta separación es importante. Bloquear a ClaudeBot para que no se entrene en tu contenido no impide que los usuarios de Claude vean tus páginas en las respuestas en directo: de eso se encarga Claude-User. Y bloquear Claude-SearchBot no afecta al entrenamiento. Cada bot es un punto de control independiente, que ofrece a los propietarios de sitios web opciones detalladas sobre cómo interactúa Anthropic con su contenido.
Esa tercera columna tiene consecuencias estratégicas reales; más adelante en esta guía desmenuzaremos todas las compensaciones de visibilidad. Pero la versión resumida: la mayoría de los propietarios de sitios web no tienen ni idea de cuál es su situación actual con las plataformas de IA. Si quieres una línea de base antes de cambiar nada comprueba tu puntuación de visibilidad de la IA para ver cómo aparece tu marca en Claude y otros sistemas de IA en este momento.
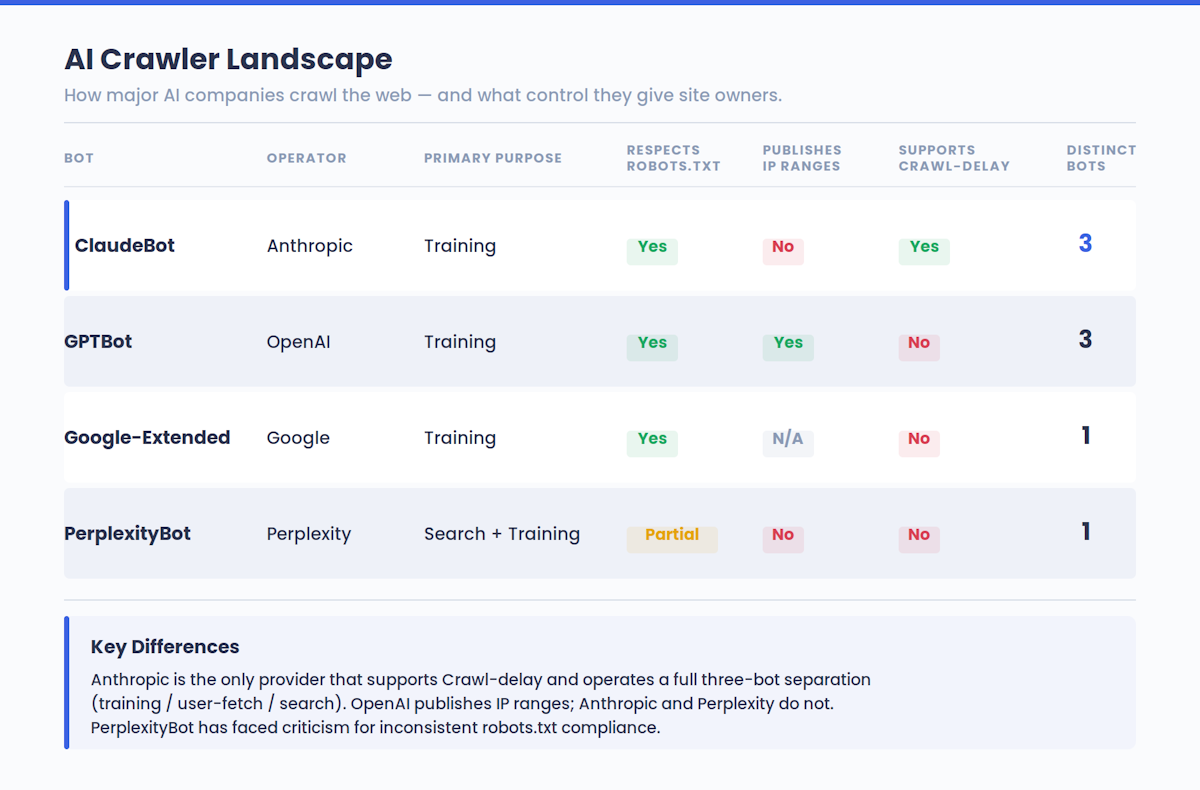
Anthropic ha declarado que su rastreo pretende ser transparente y no perturbador. Los robots cumplen las directivas de robots.txt, respetan las tecnologías antielusión, como los CAPTCHA, y admiten la extensión no estándar Crawl-delay para limitar la velocidad.
Cadena de Usuario-Agente de ClaudeBot: Cómo identificarla en tus logs
ClaudeBot se identifica con el token de agente de usuario ClaudeBot e incluye un correo electrónico de contacto en su cadena completa de agente de usuario. Ésta es la cadena completa que verás en los registros de acceso a tu servidor:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Algunos detalles técnicos dignos de mención:
- El token de agente de usuario a efectos de robots.txt es simplemente
ClaudeBot. Esa es la cadena a la que debes hacer referencia en tus directivas. - Anteriormente, Anthropic funcionaba con las cadenas de agente de usuario
Claude-WebyAnthropic-AI. Ambas están obsoletas. Si tu robots.txt todavía hace referencia a estas antiguas cadenas, tus directivas ya no son efectivas contra los actuales rastreadores de Anthropic. - Los otros dos robots utilizan sus propios tokens:
Claude-Userpara las consultas de páginas iniciadas por el usuario yClaude-SearchBotpara la indexación de búsquedas.
Para comprobar rápidamente si ClaudeBot ha visitado tu sitio, ejecuta un grep contra tus registros de acceso:
grep "ClaudeBot" /var/log/nginx/access.log
O para Apache:
grep "ClaudeBot" /var/log/apache2/access.log
Si recibes visitas de un agente de usuario que dice ser ClaudeBot, merece la pena verificar su autenticidad (más adelante encontrarás más información sobre la verificación de la IP). Las cadenas de agente de usuario pueden ser falsificadas, y los malos actores a veces se hacen pasar por rastreadores legítimos para raspar contenidos sin restricciones.
Cómo permitir o bloquear ClaudeBot en robots.txt
Controlas el acceso de ClaudeBot mediante directivas robots.txt estándar colocadas en el directorio raíz de tu sitio. Este es el método recomendado por Anthropic, y el único que garantizan que funcionará de forma fiable.
Bloquear ClaudeBot de todo tu sitio
User-agent: ClaudeBot
Disallow: /
Esto indica a ClaudeBot que no puede acceder a ninguna página de tu dominio. Anthropic afirma que cuando un sitio bloquea a ClaudeBot, indica que el contenido futuro del sitio debe excluirse de los conjuntos de datos de entrenamiento del modelo de IA.
Permitir acceso total a ClaudeBot
User-agent: ClaudeBot
Allow: /
O simplemente no incluyas ninguna directiva ClaudeBot - el comportamiento por defecto es permitir el rastreo.
Reducir la velocidad de rastreo de ClaudeBot
User-agent: ClaudeBot
Crawl-delay: 10
Esto pide a ClaudeBot que espere 10 segundos entre peticiones, reduciendo la carga del servidor sin bloquear el acceso por completo.
Bloquea los tres robots antrópicos a la vez
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-User
Disallow: /
User-agent: Claude-SearchBot
Disallow: /
Importante: Recuerda aplicar estas reglas en cada subdominio que quieras proteger. Un robots.txt en example.com no cubre docs.example.com ni blog.example.com.
Además, tómate un momento para comprobar si tu robots.txt actual contiene las cadenas obsoletas Claude-Web y Anthropic-AI. Si todavía están en tu archivo, no hacen nada contra los rastreadores antrópicos actuales. Sustitúyelas por los tres nombres de robots activos indicados anteriormente.
Acceso Parcial: Permitir tu Blog, Bloquear tu Admin
No tienes que tomar una decisión de todo o nada: robots.txt admite reglas a nivel de ruta que te permiten abrir secciones específicas mientras mantienes otras bloqueadas. Esta es la jugada inteligente para cualquier empresa que desee visibilidad de formación en IA para su contenido público pero necesite proteger las áreas sensibles.
Aquí tienes una configuración práctica que funciona para la mayoría de los sitios, tanto si gestionas una plataforma SaaS, una tienda online o un proyecto criptográfico:
User-agent: ClaudeBot
Disallow: /admin/
Disallow: /dashboard/
Disallow: /api/
Disallow: /members/
Disallow: /internal/
Allow: /blog/
Allow: /docs/
Allow: /about/
Allow: /
En esta configuración, ClaudeBot puede acceder a las entradas de tu blog, a la documentación y a las páginas públicas, haciendo que ese contenido esté disponible para el entrenamiento de la IA y aumentando las posibilidades de que Claude haga referencia a tu marca en sus respuestas. Mientras tanto, los paneles de administración, los puntos finales de la API y las áreas exclusivas para miembros permanecen fuera de los límites.
Algunos modelos comunes de acceso parcial:
- Tiendas de comercio electrónico: Permitir páginas de productos, páginas de categorías y guías de compra; bloquear las áreas de carrito, pago y cuenta.
- Plataformas SaaS: Permitir páginas de marketing, precios y documentación; bloquear paneles de control, ajustes y rutas API de las aplicaciones.
- Editores de contenidos: Permite artículos y páginas de categorías; bloquea las páginas de resultados de búsqueda y las secciones de contenido generado por el usuario para evitar que entren en el conjunto de entrenamiento contenidos poco consistentes o duplicados.
- Proyectos Crypto y Web3: Permitir documentación, blog y explicaciones de protocolos; bloquear paneles de administración, herramientas internas y áreas de comunidad cerradas.
Recuerda que las reglas Allow y Disallow se evalúan por especificidad: las rutas más específicas tienen prioridad. La directiva Disallow: /admin/ bloqueará /admin/settings aunque exista una más amplia Allow: /.
Cómo verificar las direcciones IP de ClaudeBot
Anthropic no publica una lista fija de rangos de IP para sus rastreadores web, y la empresa desaconseja confiar en el bloqueo basado en IP como defensa principal. Sus bots operan a través de una infraestructura de nube pública, lo que significa que las direcciones IP pueden cambiar. Bloquear rangos de IP también puede impedir que el robot lea tu robots.txt, lo que podría provocar un comportamiento de rastreo no intencionado.
Dicho esto, Anthropic proporciona una lista de referencia para verificar la IP. Si un rastreador dice ser ClaudeBot y su IP de origen aparece en la lista publicada por Anthropic, eso confirma que el rastreador es realmente de Anthropic. Puedes encontrar esta lista en la documentación de soporte oficial de Anthropic.
Para verificar solicitudes individuales, la mejor herramienta es una búsqueda DNS inversa:
# Step 1: Reverse DNS lookup on the crawler's IP
host 216.73.216.1
# Step 2: Forward DNS to confirm
host [result-from-step-1]
Si el DNS inverso resuelve a un dominio asociado con Anthropic (o su infraestructura en la nube), es probable que la solicitud sea auténtica. Si se resuelve en un dominio no relacionado o falla por completo, es posible que estés ante un agente de usuario falsificado, alguien que se hace pasar por ClaudeBot.
Para un seguimiento más amplio, considera estos enfoques:
- Análisis del registro del servidor: Analiza regularmente tus registros en busca de entradas en
ClaudeBoty compara las IPs con la lista publicada por Anthropic. - Plataformas de detección de bots: Servicios como Known Agents (antes Dark Visitors) y PlainSignal ofrecen análisis de agentes en tiempo real que pueden autenticar las visitas de rastreadores y señalar el tráfico falsificado.
- Reglas de proxy inverso: Herramientas como Cloudflare y Nginx te permiten crear reglas condicionales que verifican las demandas de agente de usuario con rangos de IP conocidos antes de conceder el acceso.
En resumen: utiliza robots.txt como mecanismo de control principal, y utiliza la verificación de IP como comprobación de autenticidad complementaria, y no al revés.
Cómo afecta ClaudeBot a la visibilidad de tu IA
Cada decisión que tomes sobre el acceso a ClaudeBot afecta directamente a si tu marca aparece en las respuestas generadas por IA, un canal que se está convirtiendo rápidamente en tan importante como la búsqueda tradicional. Aquí es donde la gestión técnica del rastreador se encuentra con la estrategia de crecimiento.

He aquí la compensación en términos sencillos:
- Permitir ClaudeBot → Tu contenido entra en el canal de formación de Anthropic. Es más probable que Claude haga referencia a tu marca, explique tu producto o recomiende tus servicios cuando los usuarios hagan preguntas relevantes.
- Bloquear ClaudeBot → Tu contenido futuro queda excluido del entrenamiento. El conocimiento de Claude sobre tu marca se estanca en lo que se recopiló antes del bloqueo. Con el tiempo, los competidores que permiten el rastreo obtienen una ventaja creciente en las recomendaciones generadas por la IA.
Esta dinámica se está produciendo en todo el panorama de la IA, no sólo con Claude. El GPTBot de OpenAI, los rastreadores de IA de Google y el bot de Perplexity funcionan con una lógica similar. Los sitios que participan en el entrenamiento de la IA son los que se citan en las respuestas de la IA.
Lo que está en juego es concreto en todos los sectores:
- Fundadores de SaaS: Cuando un cliente potencial pregunta a Claude "¿Cuál es la mejor herramienta de gestión de proyectos para equipos remotos?", la respuesta se basa en lo que Claude ha aprendido. Si tus documentos, páginas comparativas y desgloses de funciones formaron parte de ese aprendizaje, estás en la recomendación. Si no lo fueron, lo está tu competidor.
- Operadores de comercio electrónico: Un comprador que pregunta "¿Cuál es la mejor zapatilla de correr para pies planos?" obtiene una respuesta formada por páginas de productos y guías de compra que Claude ingirió. Las marcas que bloquearon el rastreador no aparecen en esa respuesta.
- Editores y sitios de medios de comunicación: Cuando los usuarios piden a Claude que explique un tema de tendencia, sintetiza a partir de las fuentes que conoce. Si tu información y análisis estaban en los datos de entrenamiento, Claude cita tu encuadre. Si no, domina la narrativa de otra persona.
- proyectos Crypto y Web3: Cuando un inversor pregunta "¿Cuáles son las mejores soluciones de Capa 2?" o "¿Cómo funciona [tu protocolo]?", la respuesta refleja lo que Claude ha aprendido de la documentación del protocolo y de las entradas del blog. Si el tuyo ha sido excluido, eres invisible para ese público.
En cada caso, el patrón es idéntico: el contenido al que Claude puede acceder se convierte en el contenido que Claude recomienda.
El concepto de visibilidad de la IA -la prominencia y precisión con que aparece tu marca en las plataformas impulsadas por la IA- está surgiendo como una disciplina distinta junto al SEO tradicional. Requiere su propia auditoría, su propia estrategia y su propio seguimiento. Y a diferencia del SEO tradicional, en el que puedes seguir las clasificaciones en Google Search Console, la visibilidad de la IA ha sido una caja negra para la mayoría de los equipos, hasta ahora.
Mide antes de decidir
Lo peor que puedes hacer es cambiar la configuración de ClaudeBot a ciegas. Antes de permitir o bloquear cualquiera de los tres rastreadores de Anthropic, necesitas una línea de base: ¿Con qué frecuencia menciona Claude tu marca hoy? ¿Describe tu producto con precisión? ¿Recomienda en cambio a la competencia?
La Herramienta de Visibilidad de la IA de ICODA responde a estas preguntas en cuestión de minutos. Analiza cómo aparece tu marca en las principales plataformas de IA -Claude, ChatGPT, Perplexity, Gemini- y te da una imagen clara de tu situación actual. Armado con esos datos, puedes tomar decisiones informadas sobre qué bots permitir, cuáles bloquear y qué secciones de tu sitio priorizar para la descubribilidad de la IA.
Comprueba ahora tu puntuación de visibilidad de la IA →
Puntos clave
Gestionar ClaudeBot ya no es una tarea de administrador de sistemas de nicho: es una decisión estratégica que afecta a la capacidad de descubrimiento de tu marca en la era de la IA. Esto es lo que debes recordar:
- ClaudeBot es el rastreador de entrenamiento de Anthropic, independiente del agente OpenClaw (antes ClawdBot/MoltBot) y de Claude-User y Claude-SearchBot.
- Utiliza robots.txt como mecanismo principal de control. Los robots de Anthropic respetan estas directivas de forma fiable.
- Audita tu robots.txt en busca de cadenas obsoletas (
Claude-Web,Anthropic-AI) y sustitúyelas porClaudeBot,Claude-User, yClaude-SearchBot. - Utiliza reglas de acceso parciales para compartir tus contenidos públicos, protegiendo al mismo tiempo las áreas sensibles.
- No confíes únicamente en el bloqueo de IP: Anthropic utiliza una infraestructura en la nube con IP cambiantes y no publica rangos de rastreo fijos.
- Mide primero tu visibilidad de la IA: utiliza la Herramienta de Visibilidad de la IA de ICODA para establecer una línea de base antes de realizar cambios en el acceso a los rastreadores.
- Piensa estratégicamente: bloquear los rastreadores de IA protege tu contenido pero reduce tu visibilidad de IA. El mejor enfoque equilibra ambas preocupaciones basándose en datos reales.
Las empresas que entienden este equilibrio -midiendo su huella de IA, compartiendo selectivamente sus mejores contenidos con los rastreadores y protegiendo lo que necesita protección- son las que dominarán tanto la búsqueda tradicional como los cuadros de respuestas generados por IA del mañana.
Preguntas más frecuentes (FAQ)
Compartir


Valora el artículo












