Si vous avez consulté les journaux de votre serveur dernièrement, il y a de fortes chances que vous ayez repéré un visiteur appelé ClaudeBot. Ce n’est pas un client. Ce n’est pas un hacker. C’est le robot d’Anthropic, et il lit discrètement votre site web pour aider à former l’un des modèles d’intelligence artificielle les plus avancés de la planète.
Que vous gériez un produit SaaS, une boutique de commerce électronique, un site de médias ou un projet de blockchain, comprendre ce que ClaudeBot fait (et ne fait pas) n’est plus facultatif. Alors que la recherche alimentée par l’IA remodèle la façon dont les utilisateurs découvrent le contenu, la façon dont vous interagissez avec ces robots a un impact direct sur le fait que votre marque apparaisse dans les réponses générées par l’IA - ou qu’elle en disparaisse complètement.
Ce guide explique tout ce que vous devez savoir : ce qu’est ClaudeBot, comment il s’identifie, comment contrôler son accès avec une précision chirurgicale, et pourquoi vos décisions ici pourraient façonner la visibilité de l’IA de votre marque pour les années à venir.
ClaudeBot vs. ClawdBot : ce n’est pas la même chose
ClaudeBot est le robot officiel d’Anthropic, qui collecte des contenus accessibles au public afin d’entraîner et d’améliorer les modèles d’IA de la famille Claude. ClawdBot (aujourd’hui rebaptisé OpenClaw) est un agent d’intelligence artificielle open-source créé par le développeur autrichien Peter Steinberger. Ils ne partagent rien d’autre qu’un nom vaguement similaire.
La confusion est compréhensible. Steinberger a initialement lancé son projet sous le nom de "Clawdbot" en novembre 2025, un assistant personnel d’IA qui pourrait automatiser des tâches sur des plateformes de messagerie comme WhatsApp, Telegram et Discord. Mais Anthropic a déposé des plaintes concernant la marque déposée et, en l’espace de deux mois, le projet a été renommé, d’abord en "Moltbot", puis en "OpenClaw" à la fin du mois de janvier 2026.
Voici la distinction essentielle :
- ClaudeBot est un robot d’exploration du web. Il lit les pages de votre site web afin de collecter des données d’entraînement pour les grands modèles de langage d’Anthropic. Il apparaît dans les logs de votre serveur avec une chaîne d’agent utilisateur spécifique et respecte les directives robots.txt.
- OpenClaw (anciennement ClawdBot/MoltBot) est un agent d’intelligence artificielle. Il s’exécute sur l’appareil d’un utilisateur et effectue des tâches - envoi de courriels, gestion de calendriers, navigation sur le web - pour le compte d’un opérateur humain. Il ne parcourt pas les sites web à la recherche de données d’entraînement.
Si vous voyez ClaudeBot dans vos journaux d’accès, c’est Anthropic. Si quelqu’un mentionne "ClawdBot" dans une conversation sur les assistants IA autonomes, il s’agit d’OpenClaw. Ne confondez pas les deux lors de la configuration de votre fichier robots.txt - le blocage de l’un n’a aucun effet sur l’autre.
Qu’est-ce que ClaudeBot ? Explication du crawler de formation d’Anthropic
ClaudeBot est le principal robot d’exploration du web d’Anthropic, conçu pour collecter des contenus accessibles au public qui peuvent être utilisés pour entraîner et améliorer les modèles génératifs d’IA qui alimentent Claude. Il parcourt systématiquement l’internet, en suivant les liens et les sitemaps pour découvrir et télécharger des pages web.
Contrairement aux moteurs de recherche traditionnels tels que Googlebot, qui indexent les pages pour qu’elles apparaissent dans les résultats de recherche, ClaudeBot recueille du contenu spécifiquement à des fins d’apprentissage automatique. Les données qu’il recueille alimentent le pipeline de développement de modèles d’Anthropic, aidant Claude à comprendre le langage, le contexte et les sujets nuancés dans tous les domaines.
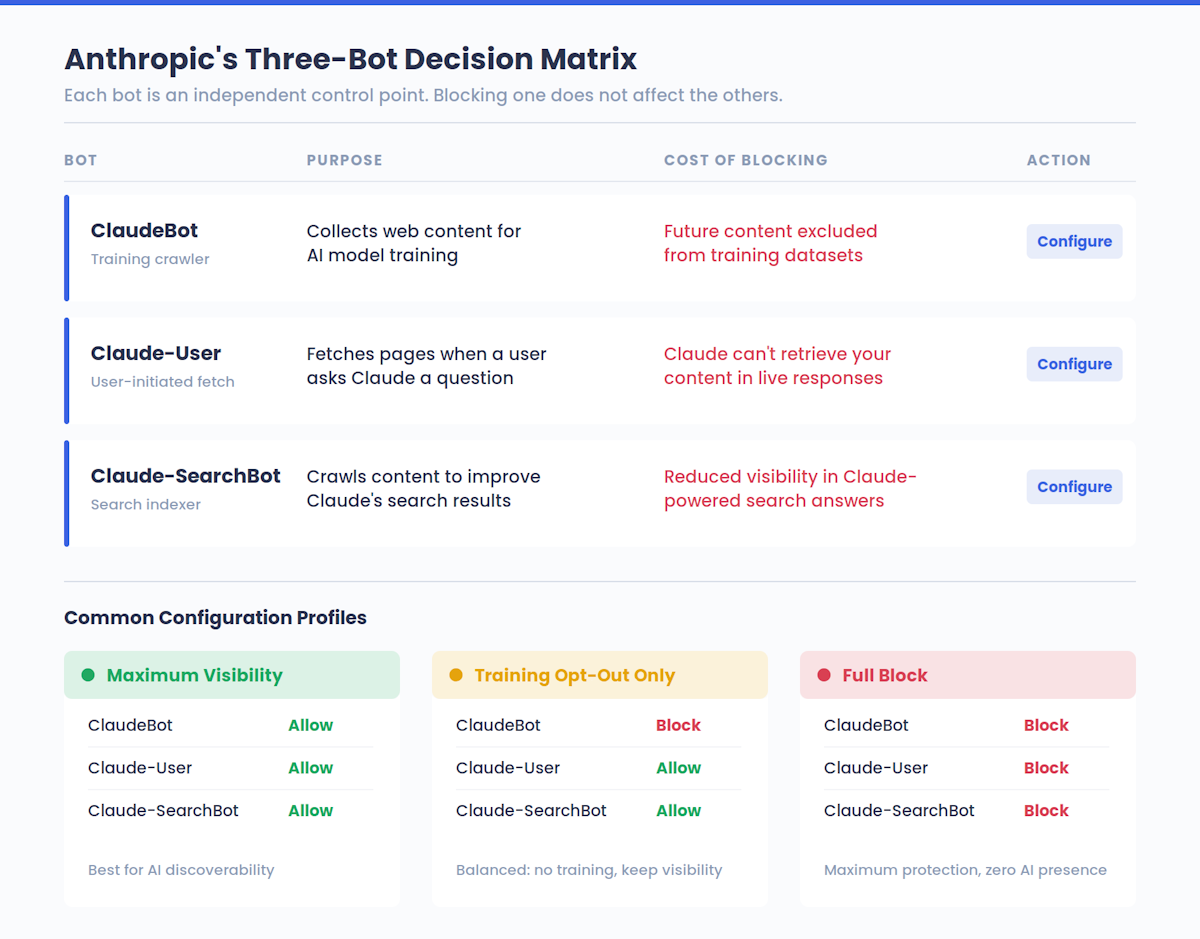
Anthropic exploite en fait trois robots distincts, chacun ayant un rôle différent :
| Nom du bot | Objectif | Ce que fait le blocage |
|---|---|---|
| ClaudeBot | Collecte de contenu web pour l’entraînement des modèles d’IA | Exclut votre futur contenu des ensembles de données de formation |
| Claude-Utilisateur | Recherche de pages lorsqu’un utilisateur de Claude pose une question | Empêche Claude de récupérer votre contenu dans les réponses en temps réel |
| Claude-SearchBot | L’exploration du contenu permet d’améliorer la qualité des résultats de recherche de Claude. | Réduit votre visibilité dans les réponses des moteurs de recherche alimentés par Claude |
Cette séparation est importante. Le fait d’empêcher ClaudeBot de s’entraîner sur votre contenu n’empêche pas les utilisateurs de Claude de voir vos pages dans les réponses en direct - c’est Claude-User qui s’en charge. Et bloquer Claude-SearchBot n’affecte pas la formation. Chaque robot est un point de contrôle indépendant, qui permet aux propriétaires de sites web de choisir de manière granulaire comment Anthropic interagit avec leur contenu.
Cette troisième colonne a de réelles conséquences stratégiques - nous aborderons les compromis en matière de visibilité plus loin dans ce guide. Mais pour résumer, la plupart des propriétaires de sites n’ont aucune idée de leur position actuelle par rapport aux plateformes d’IA. Si vous souhaitez disposer d’une base de référence avant de changer quoi que ce soit, vérifiez votre score de visibilité AI pour voir comment votre marque apparaît actuellement sur Claude et d’autres systèmes d’IA.
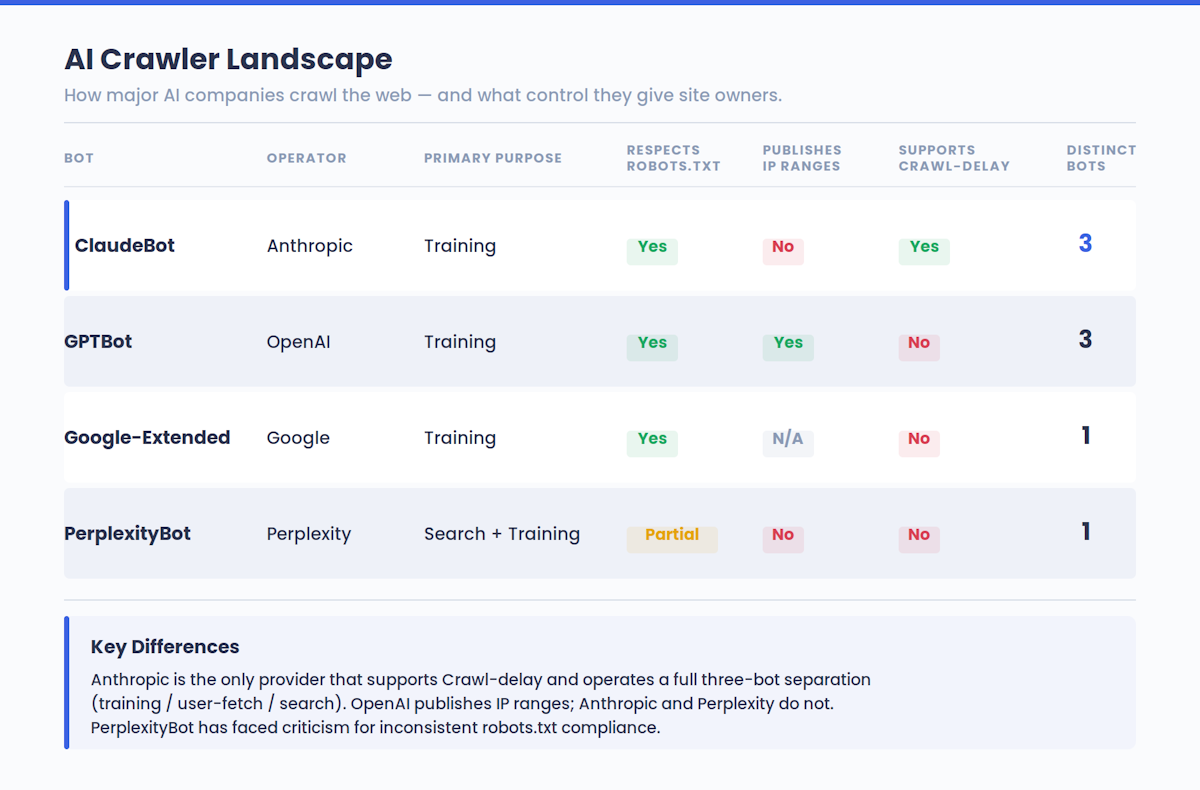
Anthropic a déclaré que son exploration visait à être transparente et non perturbatrice. Les robots respectent les directives robots.txt, les technologies anti-contournement telles que les CAPTCHA et l’extension non standard Crawl-delay pour la limitation du débit.
Chaîne User-Agent de ClaudeBot : Comment l’identifier dans vos logs
ClaudeBot s’identifie avec le user-agent token ClaudeBot et inclut un email de contact dans sa chaîne de user-agent complète. Voici la chaîne complète que vous verrez dans les journaux d’accès à votre serveur :
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Quelques détails techniques méritent d’être signalés :
- Le user-agent token pour les besoins de robots.txt est simplement
ClaudeBot. C’est la chaîne à laquelle vous faites référence dans vos directives. - Anthropic fonctionnait auparavant avec les chaînes de caractères
Claude-WebetAnthropic-AI. Ces deux chaînes sont désormais obsolètes. Si votre fichier robots.txt fait encore référence à ces anciennes chaînes, vos directives ne sont plus efficaces contre les robots d’Anthropic actuels. - Les deux autres robots utilisent leurs propres jetons :
Claude-Userpour la recherche de pages à l’initiative de l’utilisateur etClaude-SearchBotpour l’indexation des recherches.
Pour vérifier rapidement si ClaudeBot a visité votre site, exécutez un grep sur vos journaux d’accès :
grep "ClaudeBot" /var/log/nginx/access.log
Ou pour Apache :
grep "ClaudeBot" /var/log/apache2/access.log
Si vous recevez des hits d’un user-agent prétendant être ClaudeBot, il vaut la peine de vérifier l’authenticité (plus d’informations sur la vérification de l’IP ci-dessous). Les chaînes d’agents utilisateurs peuvent être usurpées, et de mauvais acteurs se font parfois passer pour des robots d’exploration légitimes afin de récupérer du contenu sans restriction.
Comment autoriser ou bloquer ClaudeBot dans le fichier robots.txt
Vous contrôlez l’accès de ClaudeBot au moyen de directives robots.txt standard placées dans le répertoire racine de votre site. C’est la méthode recommandée par Anthropic - et la seule dont ils garantissent le bon fonctionnement.
Bloquer ClaudeBot sur l’ensemble de votre site
User-agent: ClaudeBot
Disallow: /
Cela indique à ClaudeBot qu’il ne peut accéder à aucune page de votre domaine. Selon Anthropic, lorsqu’un site bloque ClaudeBot, cela signifie que le contenu futur du site doit être exclu des ensembles de données d’entraînement des modèles d’IA.
Permettre à ClaudeBot un accès complet
User-agent: ClaudeBot
Allow: /
Ou n’incluez simplement aucune directive ClaudeBot - le comportement par défaut est d’autoriser le crawling.
Ralentir la vitesse d’exploration de ClaudeBot
User-agent: ClaudeBot
Crawl-delay: 10
Cela demande à ClaudeBot d’attendre 10 secondes entre les requêtes, réduisant ainsi la charge du serveur sans bloquer complètement l’accès.
Bloquer les trois bots Anthropic en même temps
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-User
Disallow: /
User-agent: Claude-SearchBot
Disallow: /
Important: N’oubliez pas d’appliquer ces règles à tous les sous-domaines que vous souhaitez protéger. Un fichier robots.txt sur example.com ne couvre pas docs.example.com ou blog.example.com.
Prenez également le temps de vérifier votre fichier robots.txt existant pour y trouver les chaînes de caractères obsolètes Claude-Web et Anthropic-AI. Si elles figurent toujours dans votre fichier, elles ne sont d’aucune utilité pour les robots d’exploration actuels d’Anthropic. Remplacez-les par les trois noms de robots actifs listés ci-dessus.
Accès partiel : Autoriser votre blog, bloquer votre administrateur
Vous n’avez pas à prendre une décision de type "tout ou rien" : robots.txt prend en charge les règles au niveau du chemin d’accès qui vous permettent d’ouvrir des sections spécifiques tout en gardant d’autres sections verrouillées. Il s’agit d’une solution intelligente pour toute entreprise qui souhaite que son contenu public soit visible grâce à l’entraînement à l’IA, mais qui doit protéger les zones sensibles.
Voici une configuration pratique qui convient à la plupart des sites, qu’il s’agisse d’une plateforme SaaS, d’une boutique en ligne ou d’un projet cryptographique :
User-agent: ClaudeBot
Disallow: /admin/
Disallow: /dashboard/
Disallow: /api/
Disallow: /members/
Disallow: /internal/
Allow: /blog/
Allow: /docs/
Allow: /about/
Allow: /
Dans cette configuration, ClaudeBot peut accéder à vos articles de blog, à votre documentation et à vos pages publiques - rendant ce contenu disponible pour l’entraînement de l’IA et augmentant les chances que Claude fasse référence à votre marque dans ses réponses. En revanche, les panneaux d’administration, les points d’extrémité de l’API et les zones réservées aux membres restent interdits.
Quelques modèles courants d’accès partiel :
- Magasins de commerce électronique: Autorisez les pages de produits, les pages de catégories et les guides d’achat ; bloquez les zones de panier, de paiement et de compte.
- Plateformes SaaS: Autorisez les pages marketing, la tarification et les documents ; bloquez les tableaux de bord, les paramètres et les routes API des applications.
- Éditeurs de contenu: Autorisez les articles et les pages de catégorie ; bloquez les pages de résultats de recherche et les sections de contenu généré par l’utilisateur afin d’éviter que du contenu superficiel ou dupliqué n’entre dans l’ensemble de formation.
- Projets Crypto et Web3: Autoriser la documentation, les blogs et les explications sur les protocoles ; bloquer les panneaux d’administration, les outils internes et les zones communautaires fermées.
N’oubliez pas que les règles Allow et Disallow sont évaluées en fonction de leur spécificité - les chemins les plus spécifiques sont prioritaires. La directive Disallow: /admin/ bloquera /admin/settings même s’il existe un chemin plus large, Allow: /.
Comment vérifier les adresses IP de ClaudeBot
Anthropic ne publie pas de liste fixe de plages d’adresses IP pour ses robots d’exploration, et l’entreprise conseille de ne pas se fier au blocage basé sur l’adresse IP comme principal moyen de défense. Les robots d’Anthropic fonctionnent dans une infrastructure publique en nuage, ce qui signifie que les adresses IP peuvent changer. Le blocage des plages d’adresses IP peut également empêcher le robot de lire votre fichier robots.txt, ce qui peut entraîner un comportement d’exploration involontaire.
Cela dit, Anthropic fournit une liste de référence pour la vérification des adresses IP. Si un crawler prétend être ClaudeBot et que son IP source apparaît dans la liste publiée par Anthropic, cela confirme que le crawler provient bien d’Anthropic. Vous trouverez cette liste dans la documentation officielle d’Anthropic.
Pour vérifier les demandes individuelles, une recherche DNS inversée est votre meilleur outil :
# Step 1: Reverse DNS lookup on the crawler's IP
host 216.73.216.1
# Step 2: Forward DNS to confirm
host [result-from-step-1]
Si le reverse DNS aboutit à un domaine associé à Anthropic (ou à son infrastructure en nuage), la requête est probablement authentique. Si elle est résolue vers un domaine sans rapport avec Anthropic ou si elle échoue complètement, il se peut que vous soyez en présence d’un agent utilisateur usurpé - quelqu’un qui se fait passer pour ClaudeBot.
Pour un suivi plus large, envisagez les approches suivantes :
- Analyse des logs du serveur: Analysez régulièrement vos journaux pour y trouver des entrées
ClaudeBotet comparez les adresses IP à la liste publiée par Anthropic. - Plateformes de détection des robots: Des services tels que Known Agents (anciennement Dark Visitors) et PlainSignal offrent une analyse en temps réel des agents qui peuvent authentifier les visites des robots d’indexation et signaler le trafic frauduleux.
- Règles de proxy inverse: Des outils tels que Cloudflare et Nginx vous permettent de créer des règles conditionnelles qui vérifient les revendications des agents utilisateurs par rapport à des plages d’adresses IP connues avant d’accorder l’accès.
En résumé, utilisez le fichier robots.txt comme principal mécanisme de contrôle et la vérification de l’adresse IP comme contrôle d’authenticité supplémentaire, et non l’inverse.
Comment ClaudeBot affecte la visibilité de votre IA
Chaque décision que vous prenez concernant l’accès à ClaudeBot a un impact direct sur l’apparition de votre marque dans les réponses générées par l’IA - un canal qui devient rapidement aussi important que la recherche traditionnelle. C’est ici que la gestion des robots techniques rencontre la stratégie de croissance.

Voici le compromis en termes simples :
- Autoriser ClaudeBot → Votre contenu entre dans le pipeline de formation d’Anthropic. Claude est plus susceptible de faire référence à votre marque, d’expliquer votre produit ou de recommander vos services lorsque les utilisateurs posent des questions pertinentes.
- Bloquer ClaudeBot → Votre futur contenu est exclu de la formation. Les connaissances de Claude sur votre marque stagnent à ce qui a été collecté avant le blocage. Au fil du temps, les concurrents qui autorisent l’exploration gagnent un avantage croissant en matière de recommandations générées par l’IA.
Cette dynamique se retrouve dans l’ensemble du paysage de l’IA, et pas seulement chez Claude. Le GPTBot d’OpenAI, les robots d’indexation de Google et le bot de Perplexity fonctionnent tous selon une logique similaire. Les sites qui participent à l’entraînement de l’IA sont ceux qui sont cités dans les réponses de l’IA.
Les enjeux sont concrets dans tous les secteurs d’activité :
- Les fondateurs de SaaS: Lorsqu’un prospect demande à Claude "Quel est le meilleur outil de gestion de projet pour les équipes à distance ?", la réponse se base sur ce que Claude a appris. Si vos documents, vos pages de comparaison et vos descriptions de fonctionnalités ont fait partie de cet apprentissage, vous êtes dans la recommandation. Si ce n’est pas le cas, c’est votre concurrent qui l’est.
- Opérateurs de commerce électronique: Un acheteur qui demande "Quelle est la meilleure chaussure de course pour les pieds plats ?" obtient une réponse façonnée par les pages de produits et les guides d’achat que Claude a ingérés. Les marques qui ont bloqué le robot n’apparaissent pas dans cette réponse.
- les éditeurs et les sites de médias: Lorsque les utilisateurs demandent à Claude d’expliquer un sujet d’actualité, il fait une synthèse à partir des sources qu’il connaît. Si votre rapport et votre analyse figuraient dans les données de formation, Claude cite votre cadrage. Dans le cas contraire, c’est le récit de quelqu’un d’autre qui domine.
- Crypto et Web3: Lorsqu’un investisseur demande "Quelles sont les meilleures solutions de couche 2 ?" ou "Comment fonctionne [votre protocole] ?", la réponse reflète ce que Claude a appris de la documentation sur le protocole et des articles de blog. Si le vôtre a été exclu, vous êtes invisible pour ce public.
Dans chaque cas, le schéma est identique : le contenu auquel Claude peut accéder devient le contenu que Claude recommande.
Le concept de visibilité AI - la façon dont votre marque apparaît de manière proéminente et précise sur les plateformes alimentées par l’IA - émerge comme une discipline distincte aux côtés du SEO traditionnel. Il nécessite son propre audit, sa propre stratégie et son propre suivi. Et contrairement au SEO traditionnel, où vous pouvez suivre les classements dans Google Search Console, la visibilité de l’AI est restée une boîte noire pour la plupart des équipes - jusqu’à présent.
Mesurez avant de décider
La pire chose à faire est de modifier la configuration de ClaudeBot à l’aveuglette. Avant d’autoriser ou de bloquer l’un des trois crawlers d’Anthropic, vous avez besoin d’une base de référence : Combien de fois Claude mentionne-t-il votre marque aujourd’hui ? Décrit-il votre produit avec précision ? Recommande-t-il plutôt des concurrents ?
L’outil de visibilité de l’IA d’ICODA répond à ces questions en quelques minutes. Il analyse la façon dont votre marque apparaît sur les principales plateformes d’IA - Claude, ChatGPT, Perplexity, Gemini - et vous donne une image claire de votre position actuelle. Armé de ces données, vous pouvez prendre des décisions éclairées sur les bots à autoriser, ceux à bloquer et les sections de votre site à privilégier pour la découvrabilité de l’IA.
Vérifiez votre score de visibilité de l’IA maintenant →
Principaux enseignements
La gestion de ClaudeBot n’est plus une tâche d’administrateur système de niche - c’est une décision stratégique qui affecte la découvrabilité de votre marque à l’ère de l’IA. Voici ce qu’il faut retenir :
- ClaudeBot est le crawler de formation d’Anthropic, distinct de l’agent OpenClaw (anciennement ClawdBot/MoltBot) et de Claude-User et Claude-SearchBot.
- Utilisez le fichier robots.txt comme principal mécanisme de contrôle. Les robots d’Anthropic respectent ces directives de manière fiable.
- Vérifiez que votre fichier robots.txt ne contient pas de chaînes de caractères obsolètes (
Claude-Web,Anthropic-AI) et remplacez-les parClaudeBot,Claude-User, etClaude-SearchBot. - Utilisez des règles d’accès partiel pour partager votre contenu public tout en protégeant les zones sensibles.
- Ne vous fiez pas uniquement au blocage d’IP - Anthropic utilise une infrastructure en nuage avec des IP changeantes et ne publie pas de plages de crawlers fixes.
- Mesurez d’abord votre visibilité en matière d’IA - utilisez l’outil de visibilité de l’IA d’ICODA pour établir une base de référence avant de modifier l’accès des robots d’indexation.
- Pensez stratégiquement: le blocage des robots d’indexation de l’IA protège votre contenu mais réduit la visibilité de l’IA. La meilleure approche consiste à trouver un équilibre entre ces deux préoccupations en se basant sur des données réelles.
Les entreprises qui comprennent cet équilibre - en mesurant leur empreinte sur l’IA, en partageant de manière sélective leur meilleur contenu avec les robots d’indexation et en protégeant ce qui doit l’être - sont celles qui domineront à la fois la recherche traditionnelle et les boîtes de réponse générées par l’IA de demain.
Foire aux questions (FAQ)
L’exploration des pages publiques ne nécessite aucun consentement - la même règle s’applique à Googlebot. Ajoutez Disallow: / sous User-agent: ClaudeBot dans le fichier robots.txt et il s’arrêtera immédiatement. Si la bande passante est plus importante que le principe, Crawl-delay: 10 réduit la fréquence sans bloquer l’accès.
Le blocage de ClaudeBot n’a aucun effet sur le classement dans Google - il s’agit du crawler d’Anthropic, entièrement séparé de l’infrastructure de Google. Le véritable compromis est la visibilité de l’IA : le contenu exclu de l’index de ClaudeBot n’apparaîtra pas dans les réponses de Claude. C’est un problème différent du SEO, mais de plus en plus important.
ClaudeBot authentique s’identifie comme ClaudeBot/1.0 avec claudebot@anthropic.com dans la chaîne de l’agent utilisateur. Vérifiez en lançant une recherche DNS inversée sur l’IP source - elle devrait se résoudre à l’infrastructure associée à Anthropic. Anthropic publie également une liste d’adresses IP de référence dans sa documentation officielle.
Chaque bot a une fonction distincte : ClaudeBot recueille les données de formation, Claude-User récupère les pages pour les réponses en direct, Claude-SearchBot alimente la fonction de recherche. Bloquer uniquement ClaudeBot arrête la formation mais laisse les deux autres actifs. Pour bloquer entièrement Anthropic, les trois doivent être soumis à des règles explicites Disallow.
Un blocage général vous exclut totalement des recommandations générées par l’IA. Lorsque les utilisateurs demandent à Claude ou à ChatGPT "quel est le meilleur outil pour X", les réponses s’inspirent de ce que les modèles ont appris - les sites qui ont bloqué les crawlers n’apparaissent pas. Le blocage sélectif par chemin est généralement plus intelligent qu’une décision "tout ou rien".
Les règles robots.txt au niveau du chemin d’accès traitent exactement ce problème. Utilisez Disallow: /dashboard/ et Disallow: /api/ avec Allow: /blog/ - les chemins plus spécifiques sont prioritaires. Remarque : un fichier robots.txt sur example.com ne couvre pas app.example.com; les sous-domaines ont besoin de leur propre fichier.
Cela mérite cinq minutes d’attention. Les réponses générées par l’IA constituent un canal de découverte réel et croissant - votre position dans le fichier robots.txt détermine si votre contenu y apparaît. L’erreur n’est pas de choisir de bloquer ou d’autoriser, mais de ne pas prendre de position délibérée.
Partager


Notez l'article












