Wenn Sie in letzter Zeit Ihre Serverprotokolle überprüft haben, ist es gut möglich, dass Sie einen Besucher namens ClaudeBot entdeckt haben. Es ist kein Kunde. Er ist kein Hacker. Es ist der Web-Crawler von Anthropic - und er hat Ihre Website im Stillen gelesen, um eines der fortschrittlichsten KI-Modelle der Welt zu trainieren.
Ganz gleich, ob Sie ein SaaS-Produkt, einen E-Commerce-Shop, eine Medienseite oder ein Blockchain-Projekt betreiben - zu verstehen, was ClaudeBot tut (und was nicht), ist nicht mehr optional. Da die KI-gestützte Suche die Art und Weise verändert, wie Nutzer Inhalte entdecken, hat die Art und Weise, wie Sie mit diesen Crawlern interagieren, direkte Auswirkungen darauf, ob Ihre Marke in den von der KI generierten Antworten auftaucht - oder ganz daraus verschwindet.
In diesem Leitfaden erfahren Sie alles, was Sie wissen müssen: was ClaudeBot ist, wie er sich identifiziert, wie Sie seinen Zugriff mit chirurgischer Präzision kontrollieren können und warum Ihre Entscheidungen hier die KI-Präsenz Ihrer Marke auf Jahre hinaus prägen könnten.
ClaudeBot vs. ClawdBot: Sie sind nicht das Gleiche
ClaudeBot ist der offizielle Web-Crawler von Anthropic- ein Bot, der öffentlich verfügbare Inhalte sammelt, um die Claude-Familie von KI-Modellen zu trainieren und zu verbessern. ClawdBot (jetzt umbenannt in OpenClaw) war ein Open-Source-KI-Agent, der vom österreichischen Entwickler Peter Steinberger entwickelt wurde. Sie haben nichts weiter gemeinsam als einen vage ähnlichen Namen.
Die Verwirrung ist verständlich. Steinberger startete sein Projekt ursprünglich im November 2025 unter dem Namen "Clawdbot", ein persönlicher KI-Assistent, der Aufgaben über Messaging-Plattformen wie WhatsApp, Telegram und Discord automatisieren kann. Anthropic reichte jedoch Markenrechtsbeschwerden ein, und innerhalb von zwei Monaten wurde das Projekt umbenannt - zunächst in "Moltbot" und dann Ende Januar 2026 in "OpenClaw".
Hier ist der entscheidende Unterschied:
- ClaudeBot ist ein Web-Crawler. Er liest die Seiten Ihrer Website, um Trainingsdaten für die umfangreichen Sprachmodelle von Anthropic zu sammeln. Er taucht in Ihren Serverprotokollen mit einem bestimmten User-Agent-String auf und respektiert die robots.txt-Richtlinien.
- OpenClaw (ehemals ClawdBot/MoltBot) ist ein KI-Agent. Er läuft auf dem Gerät eines Benutzers und führt Aufgaben - Senden von E-Mails, Verwalten von Kalendern, Surfen im Internet - im Auftrag eines menschlichen Benutzers aus. Er durchforstet keine Websites für Trainingsdaten.
Wenn Sie ClaudeBot in Ihren Zugriffsprotokollen sehen, ist das Anthropic. Wenn jemand in einem Gespräch über autonome KI-Assistenten den Begriff "ClawdBot" erwähnt, ist damit OpenClaw gemeint. Verwechseln Sie die beiden nicht, wenn Sie Ihre robots.txt konfigurieren - das Blockieren des einen hat keinen Einfluss auf das andere.
Was ist ClaudeBot? Anthropic’s Training Crawler erklärt
ClaudeBot ist der primäre Web-Crawler von Anthropic, der öffentlich verfügbare Inhalte sammelt, die zum Trainieren und Verbessern der generativen KI-Modelle von Claude verwendet werden können. Er durchforstet systematisch das Internet, folgt Links und Sitemaps, um Webseiten zu entdecken und herunterzuladen.
Im Gegensatz zu herkömmlichen Suchmaschinen-Crawlern wie Googlebot - die Seiten indizieren, damit sie in den Suchergebnissen erscheinen - sammelt ClaudeBot Inhalte speziell für Zwecke des maschinellen Lernens. Die gesammelten Daten fließen in die Modellentwicklungspipeline von Anthropic ein und helfen Claude dabei, Sprache, Kontext und nuancierte Themen in allen Bereichen zu verstehen.
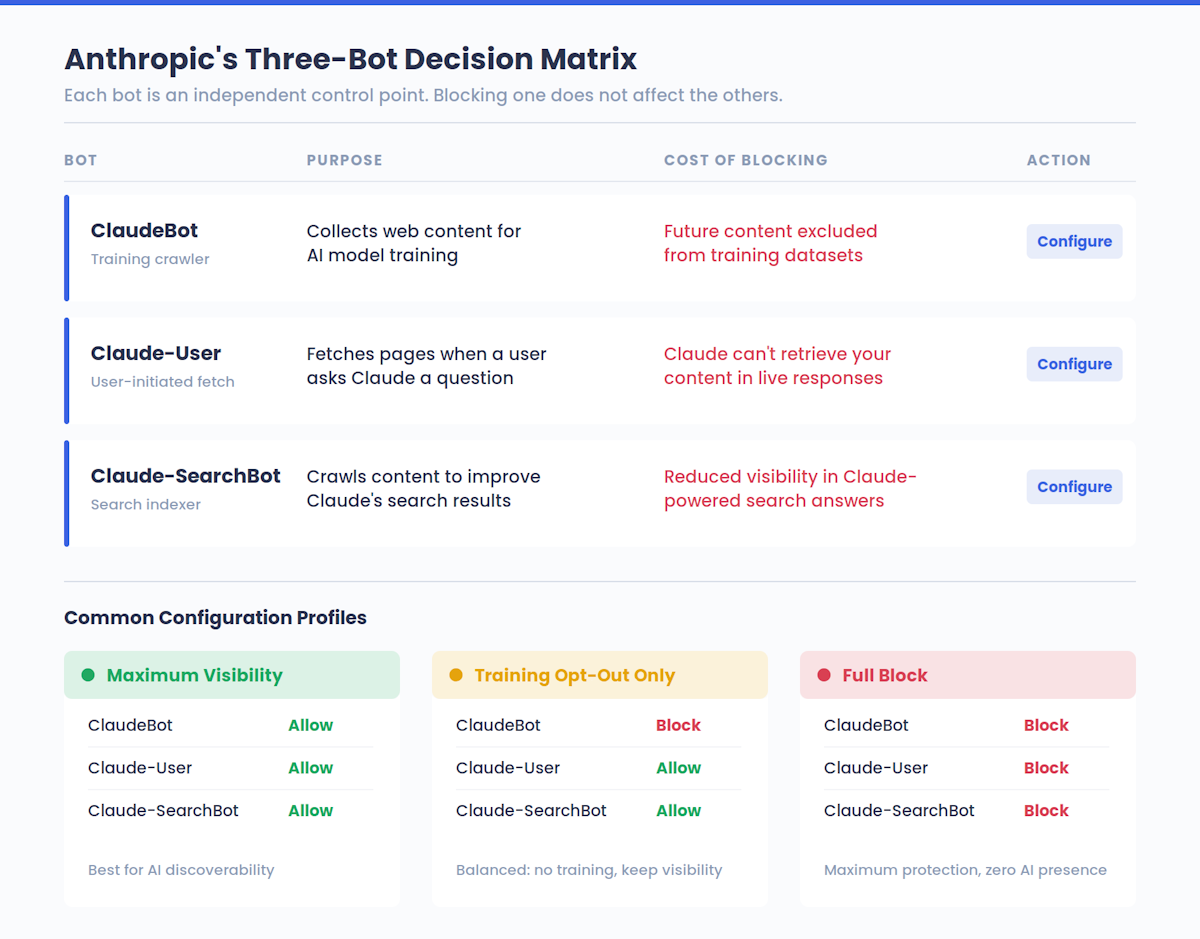
Anthropic betreibt drei verschiedene Bots, von denen jeder eine andere Aufgabe hat:
| Bot Name | Zweck | Was das Blockieren bewirkt |
|---|---|---|
| ClaudeBot | Sammelt Webinhalte für das Training von KI-Modellen | Schließt Ihre zukünftigen Inhalte von den Trainingsdatensätzen aus |
| Claude-Benutzer | Ruft Seiten ab, wenn ein Claude-Benutzer eine Frage stellt | Hindert Claude daran, Ihre Inhalte in Echtzeit abzurufen |
| Claude-SearchBot | Durchforstet Inhalte, um die Qualität der Suchergebnisse von Claude zu verbessern | Verringert Ihre Sichtbarkeit in von Claude gestützten Suchantworten |
Diese Trennung ist wichtig. Das Blockieren von ClaudeBot für das Training Ihrer Inhalte hindert Claude-Benutzer nicht daran, Ihre Seiten in Live-Antworten zu sehen - das wird von Claude-User erledigt. Und das Blockieren von Claude-SearchBot hat keine Auswirkungen auf das Training. Jeder Bot ist ein unabhängiger Kontrollpunkt, der Website-Besitzern die Möglichkeit gibt, genau zu bestimmen, wie Anthropic mit ihren Inhalten interagiert.
Diese dritte Spalte hat echte strategische Konsequenzen - wir werden später in diesem Leitfaden alle Kompromisse in Bezug auf die Sichtbarkeit auspacken. Aber die Kurzversion: Die meisten Website-Besitzer haben keine Ahnung, wo sie derzeit mit KI-Plattformen stehen. Wenn Sie eine Grundlage haben möchten, bevor Sie etwas ändern, überprüfen Sie Ihren AI Sichtbarkeits-Score um zu sehen, wie Ihre Marke derzeit bei Claude und anderen KI-Systemen erscheint.
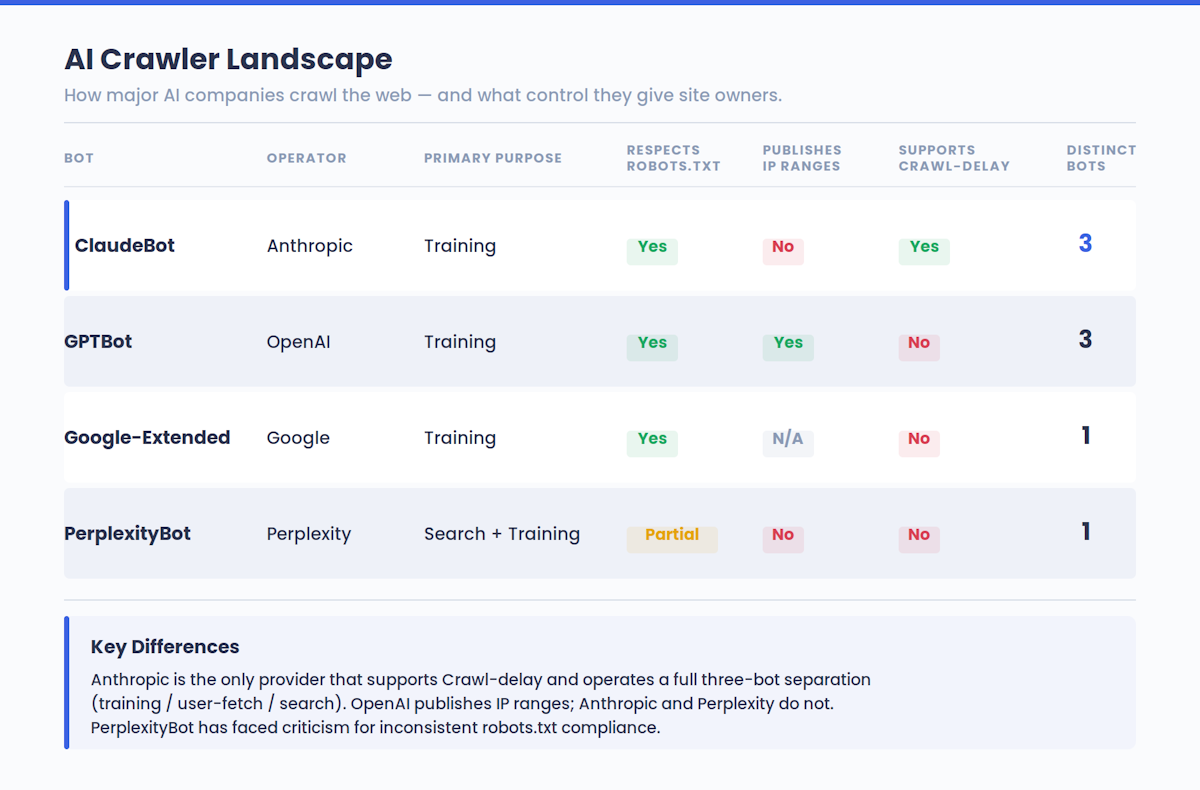
Anthropic hat erklärt, dass sein Crawling transparent und nicht störend sein soll. Die Bots halten sich an die robots.txt-Direktiven, respektieren Umgehungstechnologien wie CAPTCHAs und unterstützen die nicht standardisierte Erweiterung Crawl-delay zur Ratenbegrenzung.
ClaudeBot Benutzer-Agent Zeichenfolge: Wie Sie ihn in Ihren Protokollen identifizieren können
ClaudeBot identifiziert sich mit dem User-Agent-Token ClaudeBot und enthält eine Kontakt-E-Mail in seinem vollständigen User-Agent-String. Hier ist die vollständige Zeichenkette, die Sie in Ihren Serverzugriffsprotokollen sehen werden:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Ein paar technische Details sind erwähnenswert:
- Das User-Agent-Token für robots.txt-Zwecke ist einfach
ClaudeBot. Das ist die Zeichenfolge, auf die Sie in Ihren Direktiven verweisen. - Anthropic arbeitete früher mit den User-Agent-Zeichenfolgen
Claude-WebundAnthropic-AI. Beide sind jetzt veraltet. Wenn Ihre robots.txt noch auf diese alten Zeichenketten verweist, sind Ihre Direktiven nicht mehr wirksam gegen die aktuellen Crawler von Anthropic. - Die beiden anderen Bots verwenden ihre eigenen Token:
Claude-Userfür benutzerinitiierte Seitenabrufe undClaude-SearchBotfür die Suchindexierung.
Um schnell zu überprüfen, ob ClaudeBot Ihre Website besucht hat, führen Sie einen grep-Abgleich mit Ihren Zugriffsprotokollen durch:
grep "ClaudeBot" /var/log/nginx/access.log
Oder für Apache:
grep "ClaudeBot" /var/log/apache2/access.log
Wenn Sie Treffer von einem User-Agenten erhalten, der behauptet, ClaudeBot zu sein, sollten Sie die Authentizität überprüfen (mehr zur IP-Überprüfung weiter unten). User-Agent-Zeichenfolgen können gefälscht werden, und böse Akteure geben sich manchmal als legitime Crawler aus, um Inhalte ohne Einschränkung zu scrapen.
Wie Sie ClaudeBot in der robots.txt zulassen oder blockieren
Sie kontrollieren den Zugriff von ClaudeBot über standardmäßige robots.txt-Direktiven, die Sie im Stammverzeichnis Ihrer Website platzieren. Dies ist die von Anthropic empfohlene Methode - und die einzige, für die sie garantieren, dass sie zuverlässig funktioniert.
Blockieren Sie ClaudeBot von Ihrer gesamten Website
User-agent: ClaudeBot
Disallow: /
Dadurch wird ClaudeBot mitgeteilt, dass er auf keine Seite Ihrer Domain zugreifen kann. Anthropic erklärt, dass eine Website, die ClaudeBot blockiert, signalisiert, dass der zukünftige Inhalt der Website von den Trainingsdaten des KI-Modells ausgeschlossen werden sollte.
Erlauben Sie ClaudeBot vollen Zugriff
User-agent: ClaudeBot
Allow: /
Oder fügen Sie einfach keine ClaudeBot-Direktive ein - standardmäßig wird das Crawlen zugelassen.
Verlangsamen Sie die Crawl-Rate von ClaudeBot
User-agent: ClaudeBot
Crawl-delay: 10
Dadurch wird ClaudeBot aufgefordert, 10 Sekunden zwischen den Anfragen zu warten, um die Serverlast zu verringern, ohne den Zugriff vollständig zu blockieren.
Blockieren Sie alle drei Anthropic-Bots auf einmal
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-User
Disallow: /
User-agent: Claude-SearchBot
Disallow: /
Wichtig! Denken Sie daran, diese Regeln auf jede Subdomain anzuwenden, die Sie schützen möchten. Eine robots.txt auf example.com gilt nicht für docs.example.com oder blog.example.com.
Nehmen Sie sich außerdem einen Moment Zeit, um Ihre bestehende robots.txt auf die veralteten Zeichenketten Claude-Web und Anthropic-AIzu überprüfen. Wenn diese noch in Ihrer Datei enthalten sind, haben sie keine Wirkung auf die aktuellen Anthropic-Crawler. Ersetzen Sie sie durch die drei oben aufgeführten aktiven Bot-Namen.
Teilweiser Zugriff: Ihr Blog zulassen, Ihren Admin sperren
Sie müssen keine Alles-oder-Nichts-Entscheidung treffen - robots.txt unterstützt Regeln auf Pfadebene, die es Ihnen ermöglichen, bestimmte Bereiche zu öffnen und andere zu sperren. Dies ist eine clevere Lösung für jedes Unternehmen, das die Sichtbarkeit seiner öffentlichen Inhalte durch KI-Training verbessern, aber sensible Bereiche schützen möchte.
Hier finden Sie eine praktische Konfiguration, die für die meisten Websites funktioniert - egal, ob Sie eine SaaS-Plattform, einen Online-Shop oder ein Krypto-Projekt betreiben:
User-agent: ClaudeBot
Disallow: /admin/
Disallow: /dashboard/
Disallow: /api/
Disallow: /members/
Disallow: /internal/
Allow: /blog/
Allow: /docs/
Allow: /about/
Allow: /
In dieser Konfiguration kann ClaudeBot auf Ihre Blogbeiträge, Dokumentationen und öffentlichen Seiten zugreifen. Dadurch werden diese Inhalte für das KI-Training verfügbar und die Wahrscheinlichkeit, dass Claude in seinen Antworten auf Ihre Marke verweist, steigt. Verwaltungsbereiche, API-Endpunkte und Bereiche, die nur für Mitglieder zugänglich sind, bleiben hingegen tabu.
Einige gängige Teilzugriffsmuster:
- E-Commerce-Geschäfte: Erlauben Sie Produktseiten, Kategorieseiten und Kaufanleitungen; blockieren Sie die Bereiche Warenkorb, Kasse und Konto.
- SaaS-Plattformen: Erlauben Sie Marketingseiten, Preise und Dokumente; blockieren Sie App-Dashboards, Einstellungen und API-Routen.
- Herausgeber von Inhalten: Erlauben Sie Artikel und Kategorieseiten; blockieren Sie Suchergebnisseiten und Abschnitte mit nutzergenerierten Inhalten, um zu verhindern, dass dünne oder doppelte Inhalte in das Trainingsset gelangen.
- Krypto- und Web3-Projekte: Erlauben Sie Dokumentation, Blog und Protokollerklärungen; blockieren Sie Admin-Panels, interne Tools und geschützte Community-Bereiche.
Denken Sie daran, dass die Regeln Allow und Disallow nach ihrer Spezifität bewertet werden - spezifischere Pfade haben Vorrang. Die Direktive Disallow: /admin/ blockiert /admin/settings auch dann, wenn eine umfassendere Allow: / existiert.
Wie Sie die IP-Adressen von ClaudeBot überprüfen
Anthropic veröffentlicht keine feste Liste von IP-Bereichen für seine Web-Crawler und das Unternehmen rät davon ab, sich auf die IP-basierte Blockierung als Ihre primäre Verteidigung zu verlassen. Die Bots arbeiten über eine öffentliche Cloud-Infrastruktur, was bedeutet, dass sich IP-Adressen ändern können. Das Blockieren von IP-Bereichen könnte auch verhindern, dass der Bot Ihre robots.txt liest, was zu unbeabsichtigtem Crawling-Verhalten führen könnte.
Allerdings stellt Anthropic eine Referenzliste zur Überprüfung der IP zur Verfügung. Wenn ein Crawler behauptet, ClaudeBot zu sein, und seine Quell-IP auf der von Anthropic veröffentlichten Liste erscheint, bestätigt dies, dass der Crawler tatsächlich von Anthropic stammt. Sie finden diese Liste in der offiziellen Support-Dokumentation von Anthropic.
Um einzelne Anfragen zu überprüfen, ist ein Reverse-DNS-Lookup das beste Werkzeug:
# Step 1: Reverse DNS lookup on the crawler's IP
host 216.73.216.1
# Step 2: Forward DNS to confirm
host [result-from-step-1]
Wenn der Reverse-DNS zu einer mit Anthropic (oder seiner Cloud-Infrastruktur) verbundenen Domain auflöst, ist die Anfrage wahrscheinlich echt. Wird die Anfrage zu einer anderen Domäne aufgelöst oder schlägt sie ganz fehl, handelt es sich möglicherweise um einen gefälschten Benutzer-Agenten - jemand, der sich als ClaudeBot ausgibt.
Für eine umfassendere Überwachung sollten Sie diese Ansätze in Betracht ziehen:
- Server-Protokollanalyse: Analysieren Sie Ihre Protokolle regelmäßig auf
ClaudeBotEinträge und vergleichen Sie die IPs mit der von Anthropic veröffentlichten Liste. - Plattformen zur Bot-Erkennung: Dienste wie Known Agents (früher Dark Visitors) und PlainSignal bieten Echtzeit-Analysen von Agenten, die Crawler-Besuche authentifizieren und gefälschten Datenverkehr erkennen können.
- Reverse-Proxy-Regeln: Tools wie Cloudflare und Nginx ermöglichen es Ihnen, bedingte Regeln zu erstellen, die die Ansprüche der Benutzer-Agenten mit bekannten IP-Bereichen abgleichen, bevor Sie den Zugriff gewähren.
Fazit: Verwenden Sie robots.txt als primären Kontrollmechanismus und nutzen Sie die IP-Verifizierung als zusätzliche Authentizitätsprüfung - nicht andersherum.
Wie ClaudeBot Ihre KI-Sichtbarkeit beeinflusst
Jede Entscheidung, die Sie in Bezug auf den ClaudeBot-Zugang treffen, wirkt sich direkt darauf aus, ob Ihre Marke in den KI-generierten Antworten erscheint - ein Kanal, der schnell genauso wichtig wird wie die traditionelle Suche. Hier trifft technisches Crawler-Management auf Wachstumsstrategie.

Hier ist der Kompromiss im Klartext:
- Erlauben Sie ClaudeBot → Ihre Inhalte gelangen in Anthropics Trainings-Pipeline. Claude wird eher auf Ihre Marke verweisen, Ihr Produkt erklären oder Ihre Dienstleistungen empfehlen, wenn Nutzer relevante Fragen stellen.
- Blockieren Sie ClaudeBot → Ihre zukünftigen Inhalte sind vom Training ausgeschlossen. Claudes Wissen über Ihre Marke stagniert bei dem, was vor der Sperrung gesammelt wurde. Mit der Zeit gewinnen Konkurrenten, die Crawling zulassen, einen wachsenden Vorteil bei den von der KI generierten Empfehlungen.
Diese Dynamik spielt sich in der gesamten KI-Landschaft ab, nicht nur bei Claude. Der GPTBot von OpenAI, die KI-Crawler von Google und der Bot von Perplexity arbeiten alle nach einer ähnlichen Logik. Die Websites, die am KI-Training teilnehmen, sind diejenigen, die in den KI-Antworten zitiert werden.
In jeder Branche steht viel auf dem Spiel:
- SaaS-Gründer: Wenn ein Interessent Claude fragt: "Welches ist das beste Projektmanagement-Tool für Remote-Teams?", dann basiert die Antwort auf dem, was Claude gelernt hat. Wenn Ihre Dokumente, Vergleichsseiten und Funktionsübersichten Teil dieses Lernprozesses waren, sind Sie in der Empfehlung enthalten. Wenn nicht, dann ist es Ihr Konkurrent.
- E-Commerce-Betreiber: Ein Kunde, der die Frage "Welcher ist der beste Laufschuh für Plattfüße?" stellt, erhält eine Antwort, die aus Produktseiten und Kaufanleitungen besteht, die Claude aufgenommen hat. Marken, die den Crawler blockiert haben, tauchen in dieser Antwort nicht auf.
- Verlage und Medienseiten: Wenn Benutzer Claude bitten, ein aktuelles Thema zu erklären, stellt es eine Synthese aus den ihm bekannten Quellen her. Wenn Ihre Berichte und Analysen in den Trainingsdaten enthalten waren, zitiert Claude Ihr Framing. Wenn nicht, dominiert die Darstellung eines anderen Anbieters.
- Krypto und Web3 Projekte: Wenn ein Investor fragt: "Was sind die besten Layer-2-Lösungen?" oder "Wie funktioniert [Ihr Protokoll]?", spiegelt die Antwort wider, was Claude aus der Protokolldokumentation und den Blogbeiträgen gelernt hat. Wenn Ihre nicht berücksichtigt wurden, sind Sie für dieses Publikum unsichtbar.
In jedem Fall ist das Muster identisch: Die Inhalte, auf die Claude zugreifen kann, werden zu den Inhalten, die Claude empfiehlt.
Das Konzept der KI-Sichtbarkeit - wie prominent und genau Ihre Marke auf KI-gesteuerten Plattformen erscheint - entwickelt sich zu einer eigenen Disziplin neben der traditionellen SEO. Sie erfordert ein eigenes Audit, eine eigene Strategie und eine eigene Überwachung. Und im Gegensatz zur traditionellen SEO, bei der Sie die Rankings in der Google Search Console verfolgen können, war die KI-Sichtbarkeit für die meisten Teams eine Blackbox - bis jetzt.
Messen Sie, bevor Sie sich entscheiden
Das Schlimmste, was Sie tun können, ist, Ihre ClaudeBot-Konfiguration blindlings zu ändern. Bevor Sie einen der drei Crawler von Anthropic zulassen oder blockieren, benötigen Sie eine Grundeinstellung: Wie oft erwähnt Claude heute Ihre Marke? Beschreibt er Ihr Produkt genau? Empfiehlt er stattdessen Konkurrenten?
Das AI Visibility Tool von ICODA beantwortet diese Fragen in wenigen Minuten. Es scannt, wie Ihre Marke auf den wichtigsten KI-Plattformen - Claude, ChatGPT, Perplexity, Gemini - erscheint, und gibt Ihnen ein klares Bild von Ihrer aktuellen Position. Anhand dieser Daten können Sie fundierte Entscheidungen darüber treffen, welche Bots Sie zulassen, welche Sie blockieren und welche Bereiche Ihrer Website Sie für die KI-Auffindbarkeit priorisieren sollten.
Prüfen Sie jetzt Ihren KI-Sichtbarkeitswert →.
Wichtigste Erkenntnisse
Die Verwaltung von ClaudeBot ist nicht länger eine Nischenaufgabe des Systemadministrators - es ist eine strategische Entscheidung, die die Auffindbarkeit Ihrer Marke im Zeitalter der KI beeinflusst. Hier ist, was Sie beachten sollten:
- ClaudeBot ist der Trainings-Crawler von Anthropic, getrennt vom OpenClaw-Agenten (früher ClawdBot/MoltBot) und von Claude-User und Claude-SearchBot.
- Verwenden Sie die robots.txt als Ihren primären Kontrollmechanismus. Die Bots von Anthropic respektieren diese Richtlinien zuverlässig.
- Überprüfen Sie Ihre robots.txt auf veraltete Zeichenfolgen (
Claude-Web,Anthropic-AI) und ersetzen Sie sie durchClaudeBot,Claude-UserundClaude-SearchBot. - Verwenden Sie partielle Zugriffsregeln, um Ihre öffentlichen Inhalte zu teilen und gleichzeitig sensible Bereiche zu schützen.
- Verlassen Sie sich nicht nur auf die IP-Sperrung - Anthropic verwendet eine Cloud-Infrastruktur mit wechselnden IPs und veröffentlicht keine festen Crawler-Bereiche.
- Messen Sie zunächst Ihre AI-Sichtbarkeit - verwenden Sie das AI Visibility Tool von ICODA, um eine Basislinie zu erstellen, bevor Sie Änderungen am Crawler-Zugriff vornehmen.
- Denken Sie strategisch: Das Blockieren von KI-Crawlern schützt Ihre Inhalte, verringert aber Ihre KI-Sichtbarkeit. Der beste Ansatz, um beide Probleme auszugleichen, basiert auf tatsächlichen Daten.
Die Unternehmen, die dieses Gleichgewicht verstehen - die ihren KI-Fußabdruck messen, ihre besten Inhalte selektiv mit Crawlern teilen und schützen, was geschützt werden muss - werden sowohl die traditionelle Suche als auch die KI-generierten Antwortboxen von morgen dominieren.
Häufig gestellte Fragen (FAQ)
Für das Crawlen öffentlicher Seiten ist keine Zustimmung erforderlich - die gleiche Regel gilt für den Googlebot. Fügen Sie Disallow: / unter User-agent: ClaudeBot in der robots.txt hinzu und es wird sofort gestoppt. Wenn es nicht um das Prinzip, sondern um die Bandbreite geht, drosselt Crawl-delay: 10 die Frequenz, ohne den Zugriff zu blockieren.
Die Blockierung von ClaudeBot hat keine Auswirkungen auf die Google-Rankings - es handelt sich um den Crawler von Anthropic, der völlig unabhängig von der Google-Infrastruktur ist. Der wirkliche Kompromiss ist die KI-Sichtbarkeit: Inhalte, die aus dem Index von ClaudeBot ausgeschlossen werden, erscheinen auch nicht in den Antworten von Claude. Das ist ein anderes Problem als SEO, aber ein zunehmend wichtiges.
Der authentische ClaudeBot identifiziert sich als ClaudeBot/1.0 mit claudebot@anthropic.com im User-Agent-String. Überprüfen Sie dies, indem Sie einen Reverse-DNS-Lookup für die Quell-IP durchführen - sie sollte zu einer mit Anthropic assoziierten Infrastruktur aufgelöst werden. Anthropic veröffentlicht auch eine Referenz-IP-Liste in seinen offiziellen Dokumenten.
Jeder Bot dient einem bestimmten Zweck: ClaudeBot sammelt Trainingsdaten, Claude-User ruft Seiten für Live-Antworten ab, Claude-SearchBot betreibt die Suchfunktion. Wenn Sie nur ClaudeBot blockieren, wird das Training gestoppt, aber die beiden anderen bleiben aktiv. Um Anthropic ganz auszuschalten, benötigen alle drei explizite Disallow Regeln.
Eine pauschale Sperrung schließt Sie von den KI-generierten Empfehlungen komplett aus. Wenn Benutzer Claude oder ChatGPT fragen "Was ist das beste Tool für X", dann basieren die Antworten auf dem, was die Modelle gelernt haben - Websites, die Crawler blockiert haben, werden nicht angezeigt. Selektives Blockieren nach Pfad ist in der Regel klüger als eine Alles-oder-Nichts-Entscheidung.
Die robots.txt-Regeln auf Pfadebene regeln dies genau. Verwenden Sie Disallow: /dashboard/ und Disallow: /api/ neben Allow: /blog/ - spezifischere Pfade haben Vorrang. Hinweis: Eine robots.txt unter example.com deckt app.example.com nicht ab; Subdomains benötigen ihre eigene Datei.
Das ist fünf Minuten Aufmerksamkeit wert. KI-generierte Antworten sind ein echter und wachsender Entdeckungskanal - Ihre robots.txt-Einstellung bestimmt, ob Ihre Inhalte darin erscheinen. Der Fehler liegt nicht darin, zu blockieren oder zuzulassen, sondern darin, überhaupt keine bewusste Haltung einzunehmen.
Teilen Sie


Den Artikel bewerten












