Se ultimamente hai controllato i log del tuo server, è molto probabile che tu abbia notato un visitatore chiamato ClaudeBot. Non è un cliente. Non è un hacker. È il web crawler di Anthropic e sta leggendo silenziosamente il tuo sito web per contribuire all’addestramento di uno dei modelli di intelligenza artificiale più avanzati del pianeta.
Se gestisci un prodotto SaaS, un negozio di e-commerce, un sito di media o un progetto blockchain, capire cosa fa (e non fa) ClaudeBot non è più facoltativo. Poiché la ricerca alimentata dall’intelligenza artificiale rimodella il modo in cui gli utenti scoprono i contenuti, il modo in cui interagisci con questi crawler influisce direttamente sul fatto che il tuo marchio compaia nelle risposte generate dall’intelligenza artificiale o che scompaia del tutto.
Questa guida ti spiega tutto quello che devi sapere: cos’è ClaudeBot, come si identifica, come controllare il suo accesso con precisione chirurgica e perché le tue decisioni in questo caso potrebbero influenzare la visibilità dell’intelligenza artificiale del tuo marchio per gli anni a venire.
ClaudeBot vs. ClawdBot: non sono la stessa cosa
ClaudeBot è il web crawler ufficiale di Anthropic, un bot che raccoglie contenuti disponibili pubblicamente per addestrare e migliorare la famiglia di modelli AI Claude. ClawdBot (ora ribattezzato OpenClaw) è un agente di intelligenza artificiale open-source realizzato dallo sviluppatore austriaco Peter Steinberger. Non condividono nulla oltre a un nome vagamente simile.
La confusione è comprensibile. Steinberger ha originariamente lanciato il suo progetto con il nome di "Clawdbot" nel novembre 2025, un assistente personale di intelligenza artificiale in grado di automatizzare le attività sulle piattaforme di messaggistica come WhatsApp, Telegram e Discord. Ma Anthropic ha presentato un reclamo per il marchio e nel giro di due mesi il progetto è stato rinominato prima in "Moltbot" e poi in "OpenClaw" alla fine di gennaio 2026.
Ecco la distinzione chiave:
- ClaudeBot è un web crawler. Legge le pagine del tuo sito web per raccogliere dati di addestramento per i modelli linguistici di Anthropic. Compare nei log del tuo server con una specifica stringa di user-agent e rispetta le direttive robots.txt.
- OpenClaw (ex ClawdBot/MoltBot) è un agente AI. Viene eseguito sul dispositivo di un utente ed esegue attività (invio di e-mail, gestione di calendari, navigazione sul web) per conto di un operatore umano. Non effettua il crawling di siti web per ottenere dati di addestramento.
Se vedi ClaudeBot nei tuoi log di accesso, si tratta di Anthropic. Se qualcuno menziona "ClawdBot" in una conversazione sugli assistenti AI autonomi, sta parlando di OpenClaw. Non confondere le due cose quando configuri il tuo robots.txt: il blocco di una non ha alcun effetto sull’altra.
Cos’è ClaudeBot? Spiegazione del crawler di formazione di Anthropic
ClaudeBot è il principale web crawler di Anthropic, progettato per raccogliere contenuti disponibili pubblicamente che possono essere utilizzati per addestrare e migliorare i modelli di intelligenza artificiale generativa che alimentano Claude. Attraversa sistematicamente Internet, seguendo link e sitemap per scoprire e scaricare pagine web.
A differenza dei tradizionali crawler dei motori di ricerca come Googlebot - che indicizzano le pagine per farle apparire nei risultati di ricerca - ClaudeBot raccoglie contenuti specificamente per scopi di apprendimento automatico. I dati raccolti confluiscono nella pipeline di sviluppo dei modelli di Anthropic, aiutando Claude a comprendere il linguaggio, il contesto e le sfumature di ogni dominio.
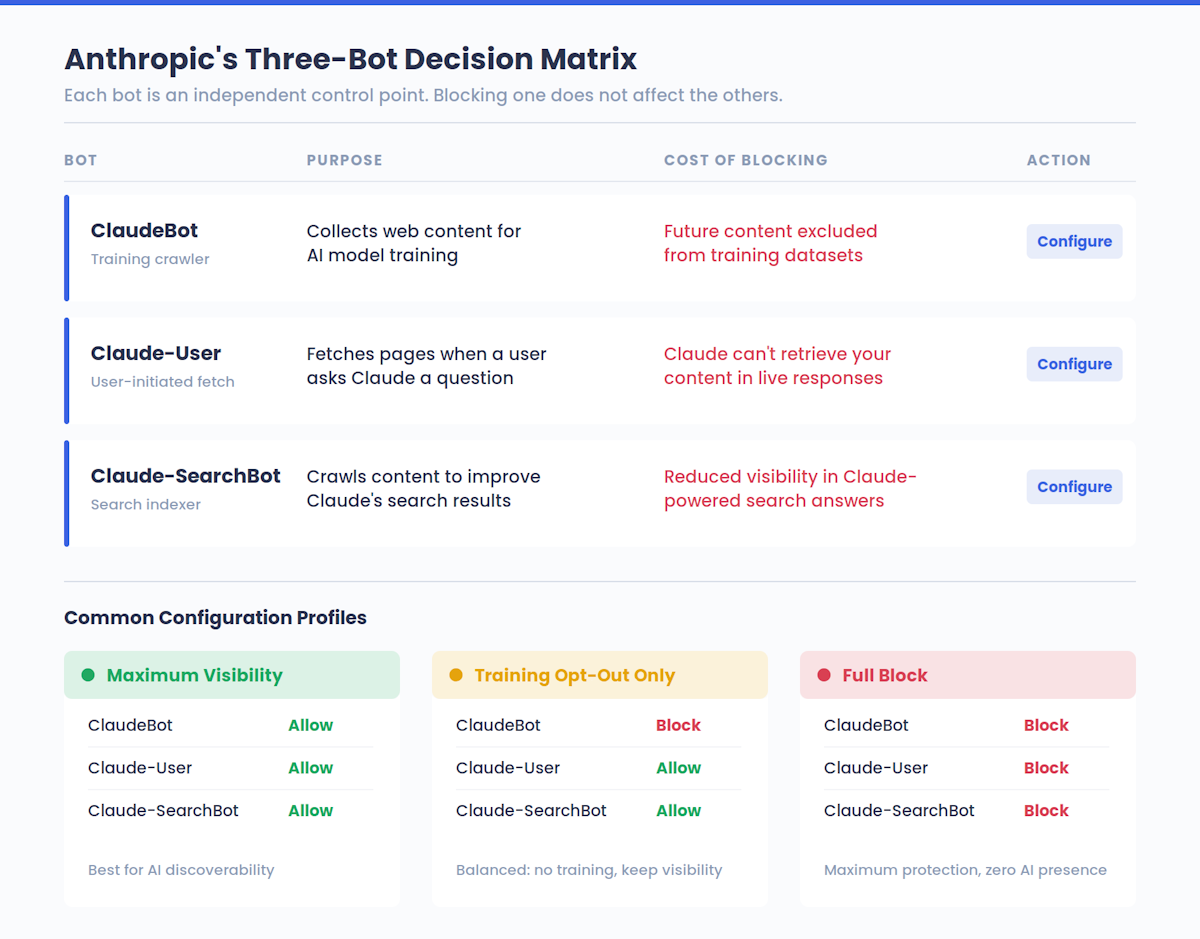
Anthropic gestisce in realtà tre bot distinti, ognuno con un ruolo diverso:
| Nome del bot | Scopo | Cosa fa il blocco |
|---|---|---|
| ClaudeBot | Raccoglie contenuti web per l’addestramento dei modelli di intelligenza artificiale | Esclude i tuoi contenuti futuri dai set di dati di addestramento |
| Claude-Utente | Recupera le pagine quando un utente Claude pone una domanda | Impedisce a Claude di recuperare i tuoi contenuti nelle risposte in tempo reale |
| Claude-SearchBot | Cerca i contenuti per migliorare la qualità dei risultati di ricerca di Claude | Riduce la tua visibilità nelle risposte di ricerca basate su Claude |
Questa separazione è importante. Bloccare ClaudeBot dall’addestramento sui tuoi contenuti non impedisce agli utenti Claude di vedere le tue pagine nelle risposte in tempo reale: questo viene gestito da Claude-User. E bloccare Claude-SearchBot non influisce sulla formazione. Ogni bot è un punto di controllo indipendente, che offre ai proprietari di siti web scelte granulari su come Anthropic interagisce con i loro contenuti.
La terza colonna ha conseguenze strategiche reali - approfondiremo i compromessi di visibilità più avanti in questa guida. Ma la versione breve è che la maggior parte dei proprietari di siti non ha idea della loro posizione attuale rispetto alle piattaforme di intelligenza artificiale. Se vuoi avere una base di riferimento prima di cambiare qualcosa, controlla il tuo punteggio di visibilità AI per vedere come appare il tuo marchio su Claude e altri sistemi di intelligenza artificiale.
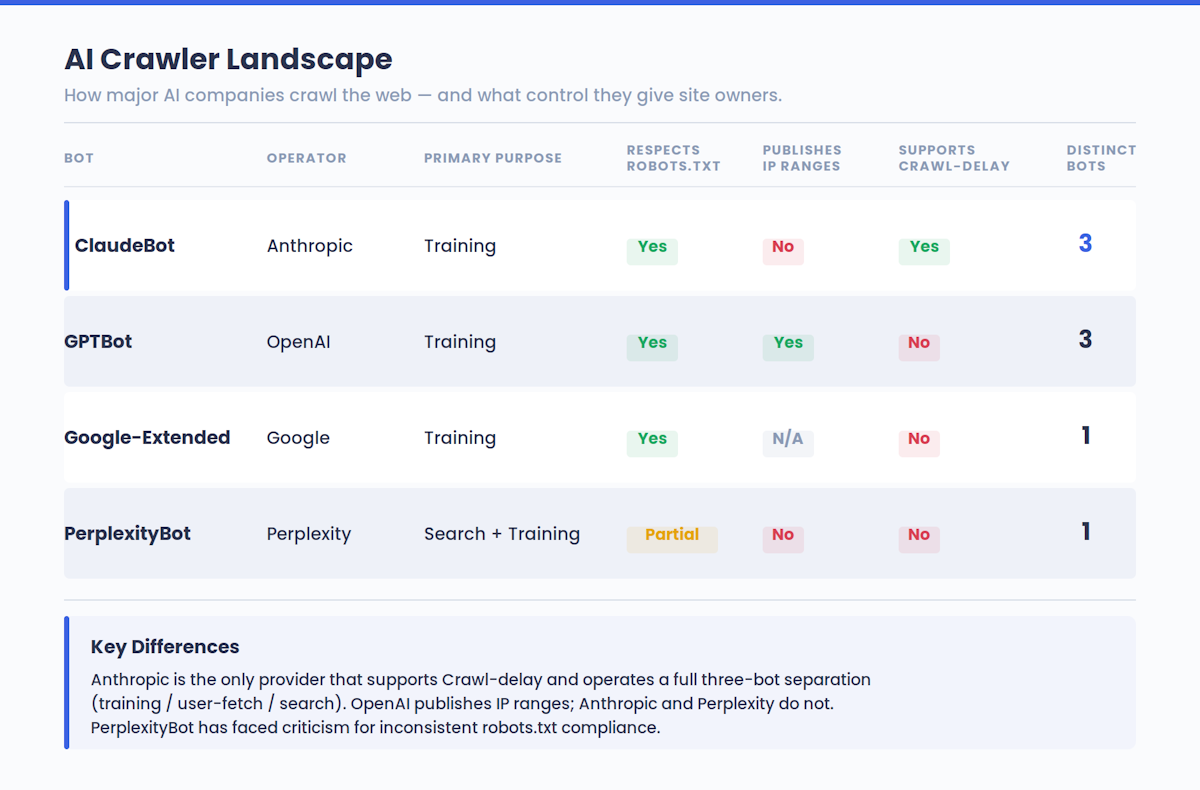
Anthropic ha dichiarato che il suo crawling mira a essere trasparente e non distruttivo. I bot rispettano le direttive di robots.txt, rispettano le tecnologie antielusione come i CAPTCHA e supportano l’estensione non standard Crawl-delay per la limitazione della velocità.
Stringa User-Agent di ClaudeBot: Come identificarla nei log
ClaudeBot si identifica con il token user-agent ClaudeBot e include un’email di contatto nella sua stringa user-agent completa. Ecco la stringa completa che vedrai nei log di accesso al tuo server:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Alcuni dettagli tecnici degni di nota:
- Il token user-agent ai fini di robots.txt è semplicemente
ClaudeBot. Questa è la stringa a cui fai riferimento nelle tue direttive. - In precedenza Anthropic operava con le stringhe user-agent
Claude-WebeAnthropic-AI. Entrambe sono ora deprecate. Se il tuo robots.txt fa ancora riferimento a queste vecchie stringhe, le tue direttive non sono più efficaci contro gli attuali crawler di Anthropic. - Gli altri due bot utilizzano i propri token:
Claude-Userper la ricerca di pagine da parte degli utenti eClaude-SearchBotper l’indicizzazione delle ricerche.
Per verificare rapidamente se ClaudeBot ha visitato il tuo sito, esegui un grep sui tuoi log di accesso:
grep "ClaudeBot" /var/log/nginx/access.log
O per Apache:
grep "ClaudeBot" /var/log/apache2/access.log
Se stai vedendo visite da un user-agent che afferma di essere ClaudeBot, vale la pena di verificarne l’autenticità (maggiori informazioni sulla verifica dell’IP più avanti). Le stringhe degli user-agent possono essere falsificate e i malintenzionati a volte si spacciano per crawler legittimi per scrapare contenuti senza restrizioni.
Come consentire o bloccare ClaudeBot in robots.txt
Puoi controllare l’accesso di ClaudeBot attraverso le direttive standard robots.txt inserite nella directory principale del tuo sito. Questo è il metodo consigliato da Anthropic e l’unico che garantisce che funzionerà in modo affidabile.
Blocca ClaudeBot da tutto il tuo sito
User-agent: ClaudeBot
Disallow: /
In questo modo ClaudeBot non può accedere a nessuna pagina del tuo dominio. Anthropic afferma che quando un sito blocca ClaudeBot, segnala che i contenuti futuri del sito devono essere esclusi dai dataset di addestramento del modello AI.
Consenti a ClaudeBot l’accesso completo
User-agent: ClaudeBot
Allow: /
Oppure semplicemente non includere alcuna direttiva ClaudeBot: il comportamento predefinito è quello di consentire il crawling.
Rallenta la velocità di scansione di ClaudeBot
User-agent: ClaudeBot
Crawl-delay: 10
Questo chiede a ClaudeBot di aspettare 10 secondi tra una richiesta e l’altra, riducendo il carico del server senza bloccare completamente l’accesso.
Blocca tutti e tre i bot Anthropic contemporaneamente
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-User
Disallow: /
User-agent: Claude-SearchBot
Disallow: /
Importante: Ricorda di applicare queste regole a tutti i sottodomini che vuoi proteggere. Un robots.txt su example.com non copre docs.example.com o blog.example.com.
Inoltre, controlla il tuo robots.txt esistente per verificare la presenza delle stringhe deprecate Claude-Web e Anthropic-AI. Se sono ancora presenti nel tuo file, non hanno alcun effetto sugli attuali crawler di Anthropic. Sostituiscile con i tre nomi di bot attivi elencati sopra.
Accesso parziale: Consenti il tuo blog, blocca il tuo amministratore
Non devi decidere tutto o niente: robots.txt supporta regole a livello di percorso che ti permettono di aprire sezioni specifiche e di bloccarne altre. Si tratta di una soluzione intelligente per tutte le aziende che desiderano la visibilità della formazione AI per i propri contenuti pubblici, ma che devono proteggere le aree sensibili.
Ecco una configurazione pratica che funziona per la maggior parte dei siti, sia che tu stia gestendo una piattaforma SaaS, un negozio online o un progetto di criptovaluta:
User-agent: ClaudeBot
Disallow: /admin/
Disallow: /dashboard/
Disallow: /api/
Disallow: /members/
Disallow: /internal/
Allow: /blog/
Allow: /docs/
Allow: /about/
Allow: /
In questa configurazione, ClaudeBot può accedere ai post del tuo blog, alla documentazione e alle pagine pubbliche, rendendo questi contenuti disponibili per l’addestramento dell’intelligenza artificiale e aumentando la possibilità che Claude faccia riferimento al tuo marchio nelle sue risposte. Nel frattempo, i pannelli di amministrazione, gli endpoint API e le aree riservate ai membri rimangono off-limits.
Alcuni modelli comuni di accesso parziale:
- Negozi di e-commerce: Consenti le pagine dei prodotti, le pagine delle categorie e le guide all’acquisto; blocca le aree del carrello, del checkout e dell’account.
- Piattaforme SaaS: Consenti le pagine di marketing, i prezzi e i documenti; blocca le dashboard delle app, le impostazioni e i percorsi API.
- Editori di contenuti: Consenti gli articoli e le pagine di categoria; blocca le pagine dei risultati di ricerca e le sezioni di contenuti generati dagli utenti per evitare che i contenuti scarni o duplicati entrino nel set di formazione.
- Progetti Crypto e Web3: Consenti la documentazione, il blog e le spiegazioni dei protocolli; blocca i pannelli di amministrazione, gli strumenti interni e le aree riservate della comunità.
Ricorda che le regole Allow e Disallow sono valutate in base alla specificità: i percorsi più specifici hanno la precedenza. La direttiva Disallow: /admin/ bloccherà /admin/settings anche se esiste una più ampia Allow: /.
Come verificare gli indirizzi IP di ClaudeBot
Anthropic non pubblica un elenco fisso di intervalli IP per i suoi web crawler e l’azienda consiglia di non affidarsi al blocco basato sull’IP come difesa principale. I loro bot operano attraverso un’infrastruttura cloud pubblica, quindi gli indirizzi IP possono cambiare. Il blocco degli intervalli IP potrebbe anche impedire al bot di leggere il tuo robots.txt, il che potrebbe portare a un comportamento di crawling indesiderato.
Detto questo, Anthropic fornisce un elenco di riferimento per la verifica dell’IP. Se un crawler dichiara di essere ClaudeBot e il suo IP di origine compare nell’elenco pubblicato da Anthropic, ciò conferma che il crawler proviene effettivamente da Anthropic. Puoi trovare questo elenco nella documentazione di supporto ufficiale di Anthropic.
Per verificare le singole richieste, il miglior strumento è una ricerca DNS inversa:
# Step 1: Reverse DNS lookup on the crawler's IP
host 216.73.216.1
# Step 2: Forward DNS to confirm
host [result-from-step-1]
Se il reverse DNS si risolve in un dominio associato ad Anthropic (o alla sua infrastruttura cloud), è probabile che la richiesta sia autentica. Se si risolve in un dominio non correlato o fallisce del tutto, è possibile che si tratti di un agente utente spoofato - qualcuno che impersona ClaudeBot.
Per un monitoraggio più ampio, considera questi approcci:
- Analisi dei log del server: Analizza regolarmente i tuoi log alla ricerca di voci di
ClaudeBote confronta gli IP con l’elenco pubblicato da Anthropic. - Piattaforme di rilevamento bot: Servizi come Known Agents (ex Dark Visitors) e PlainSignal offrono un’analisi in tempo reale degli agenti in grado di autenticare le visite dei crawler e di segnalare il traffico spoofed.
- Regole di reverse proxy: Strumenti come Cloudflare e Nginx ti permettono di creare regole condizionali che verificano le richieste dell’utente-agente rispetto a intervalli IP noti prima di concedere l’accesso.
In conclusione, usa il robots.txt come meccanismo di controllo principale e utilizza la verifica dell’IP come controllo supplementare dell’autenticità, non il contrario.
Come ClaudeBot influisce sulla visibilità della tua IA
Ogni decisione che prendi in merito all’accesso a ClaudeBot ha un impatto diretto sulla possibilità che il tuo marchio appaia nelle risposte generate dall’intelligenza artificiale, un canale che sta rapidamente diventando importante quanto la ricerca tradizionale. È qui che la gestione tecnica dei crawler incontra la strategia di crescita.

Ecco il compromesso in parole povere:
- Consenti a ClaudeBot → I tuoi contenuti entrano nella pipeline di formazione di Anthropic. Claude è più propenso a fare riferimento al tuo marchio, a spiegare il tuo prodotto o a consigliare i tuoi servizi quando gli utenti fanno domande pertinenti.
- Blocca ClaudeBot → I tuoi contenuti futuri sono esclusi dalla formazione. La conoscenza del tuo marchio da parte di Claude si ferma a ciò che è stato raccolto prima del blocco. Nel tempo, i concorrenti che consentono il crawling ottengono un vantaggio crescente nelle raccomandazioni generate dall’intelligenza artificiale.
Questa dinamica si sta riproducendo in tutto il panorama dell’IA, non solo con Claude. Il GPTBot di OpenAI, i crawler di Google e il bot di Perplexity operano tutti secondo una logica simile. I siti che partecipano all’addestramento dell’IA sono quelli che vengono citati nelle risposte dell’IA.
La posta in gioco è concreta in ogni settore:
- Fondatori di SaaS: Quando un potenziale cliente chiede a Claude "Qual è il miglior strumento di gestione dei progetti per i team remoti?", la risposta si basa su ciò che Claude ha imparato. Se i tuoi documenti, le tue pagine di confronto e le tue descrizioni delle caratteristiche hanno fatto parte di questo apprendimento, sei tra i raccomandati. Se non lo sono stati, lo è il tuo concorrente.
- Operatori di e-commerce: Un acquirente che chiede "Qual è la migliore scarpa da corsa per i piedi piatti?" riceve una risposta formata da pagine di prodotti e guide all’acquisto ingerite da Claude. I marchi che hanno bloccato il crawler non compaiono nella risposta.
- Editori e siti di media: Quando gli utenti chiedono a Claude di spiegare un argomento di tendenza, Claude sintetizza dalle fonti che conosce. Se il tuo reportage e la tua analisi erano presenti nei dati di formazione, Claude cita il tuo articolo. In caso contrario, domina la narrazione di qualcun altro.
- Progetti Crypto e Web3: Quando un investitore chiede "Quali sono le migliori soluzioni Layer 2?" o "Come funziona [il tuo protocollo]?", la risposta riflette ciò che Claude ha appreso dalla documentazione del protocollo e dai post sul blog. Se la tua è stata esclusa, sei invisibile per quel pubblico.
In ogni caso, lo schema è identico: il contenuto a cui Claude può accedere diventa il contenuto che Claude raccomanda.
Il concetto di visibilità dell’AI, ovvero la visibilità e l’accuratezza con cui il tuo marchio appare sulle piattaforme alimentate dall’AI, sta emergendo come disciplina a sé stante accanto alla SEO tradizionale. Richiede una propria verifica, una propria strategia e un proprio monitoraggio. E a differenza della SEO tradizionale, dove è possibile monitorare le classifiche in Google Search Console, la visibilità dell’AI è rimasta una scatola nera per la maggior parte dei team, fino ad ora.
Misura prima di decidere
La cosa peggiore che puoi fare è cambiare la configurazione di ClaudeBot alla cieca. Prima di consentire o bloccare uno dei tre crawler di Anthropic, devi avere una base di riferimento: Quanto spesso Claude menziona il tuo marchio oggi? Descrive accuratamente il tuo prodotto? Raccomanda invece i concorrenti?
L’AI Visibility Tool di ICODA risponde a queste domande in pochi minuti. Esamina come il tuo marchio appare sulle principali piattaforme di intelligenza artificiale (Claude, ChatGPT, Perplexity, Gemini) e ti fornisce un quadro chiaro della tua posizione attuale. Armato di questi dati, potrai prendere decisioni informate su quali bot consentire, quali bloccare e quali sezioni del tuo sito privilegiare per la scopribilità dell’AI.
Controlla subito il tuo punteggio di visibilità dell’AI →
Punti di forza
La gestione di ClaudeBot non è più un compito da sysadmin di nicchia: è una decisione strategica che influisce sulla scopribilità del tuo marchio nell’era dell’intelligenza artificiale. Ecco cosa ricordare:
- ClaudeBot è il crawler di formazione di Anthropic, separato dall’agente OpenClaw (ex ClawdBot/MoltBot) e da Claude-User e Claude-SearchBot.
- Usa il file robots.txt come meccanismo di controllo principale. I bot di Anthropic rispettano queste direttive in modo affidabile.
- Controlla il tuo robots.txt alla ricerca di stringhe deprecate (
Claude-Web,Anthropic-AI) e sostituiscile conClaudeBot,Claude-UsereClaude-SearchBot. - Usa le regole di accesso parziale per condividere i tuoi contenuti pubblici proteggendo le aree sensibili.
- Non fare affidamento solo sul blocco dell’IP - Anthropic utilizza un’infrastruttura cloud con IP mutevoli e non pubblica intervalli di crawler fissi.
- Misura prima la visibilità dell’AI: usa lo strumento di visibilità dell’AI di ICODA per stabilire una linea di base prima di apportare modifiche all’accesso al crawler.
- Pensa in modo strategico: bloccare i crawler dell’AI protegge i tuoi contenuti ma riduce la visibilità dell’AI. L’approccio migliore bilancia entrambe le preoccupazioni sulla base dei dati reali.
Le aziende che comprendono questo equilibrio - misurando la propria impronta AI, condividendo selettivamente i contenuti migliori con i crawler e proteggendo ciò che deve essere protetto - sono quelle che domineranno sia la ricerca tradizionale che le caselle di risposta generate dall’AI di domani.
Domande frequenti (FAQ)
Il crawling di pagine pubbliche non richiede alcun consenso: la stessa regola vale per Googlebot. Aggiungi Disallow: / sotto User-agent: ClaudeBot nel robots.txt e si fermerà immediatamente. Se il problema è la larghezza di banda e non il principio, Crawl-delay: 10 riduce la frequenza senza bloccare l’accesso.
Il blocco di ClaudeBot non ha alcun effetto sulle classifiche di Google: è il crawler di Anthropic, completamente separato dall’infrastruttura di Google. Il vero compromesso è la visibilità dell’AI: i contenuti esclusi dall’indice di ClaudeBot non appariranno nelle risposte di Claude. Si tratta di un problema diverso dalla SEO, ma sempre più importante.
ClaudeBot autentico si identifica come ClaudeBot/1.0 con claudebot@anthropic.com nella stringa dell’user-agent. Verifica eseguendo una ricerca DNS inversa sull’IP di origine: dovrebbe risolversi in un’infrastruttura associata ad Anthropic. Anthropic pubblica anche un elenco di IP di riferimento nei suoi documenti ufficiali.
Ogni bot ha uno scopo distinto: ClaudeBot raccoglie i dati di formazione, Claude-User recupera le pagine per le risposte in tempo reale, Claude-SearchBot alimenta la funzione di ricerca. Bloccando solo ClaudeBot si interrompe la formazione ma si lasciano attivi gli altri due. Per bloccare completamente Anthropic, tutti e tre hanno bisogno di regole Disallow esplicite.
Un blocco generalizzato ti esclude completamente dalle raccomandazioni generate dall’intelligenza artificiale. Quando gli utenti chiedono a Claude o a ChatGPT "qual è il miglior strumento per X", le risposte si basano su ciò che i modelli hanno imparato: i siti che hanno bloccato i crawler non appaiono. Il blocco selettivo in base al percorso è di solito più intelligente di una decisione "tutto o niente".
Le regole di robots.txt a livello di percorso gestiscono esattamente questo aspetto. Usa Disallow: /dashboard/ e Disallow: /api/ insieme a Allow: /blog/ - i percorsi più specifici hanno la precedenza. Nota: un robots.txt su example.com non copre app.example.com; i sottodomini hanno bisogno di un proprio file.
Vale la pena dedicargli cinque minuti di attenzione. Le risposte generate dall’intelligenza artificiale sono un canale di scoperta reale e in crescita: la tua posizione nel robots.txt determina la presenza dei tuoi contenuti. L’errore non sta nella scelta di bloccare o consentire, ma nel non avere alcuna posizione deliberata.
Condividi


Valuta l'articolo












