最近サーバーのログをチェックしていたら、ClaudeBotという訪問者を見つけた可能性が高い。お客さんではありません。ハッカーでもありません。Anthropicのウェブクローラーであり、地球上で最も高度なAIモデルの1つを訓練するために、あなたのウェブサイトを静かに読んでいるのです。
SaaS製品、Eコマースストア、メディアサイト、ブロックチェーンプロジェクトのいずれを経営していても、ClaudeBotが何をするのか(そして何をしないのか)を理解することは、もはやオプションではありません。AIを活用した検索が、ユーザーがコンテンツを発見する方法を再構築する中、これらのクローラーとどのようにやり取りするかは、AIが生成した回答にあなたのブランドが表示されるかどうか、あるいは回答から完全に消えてしまうかどうかに直接影響する。
このガイドでは、ClaudeBotとは何か、ClaudeBotはどのように自分自身を識別するのか、ClaudeBotのアクセスを外科的な精度で制御する方法、そしてなぜここでのあなたの決断が今後何年にもわたってあなたのブランドのAIの可視性を形成する可能性があるのか、など知っておくべきことをすべて説明します。
ClaudeBotとClawdBot:両者は同じものではない
ClaudeBotは Anthropicの公式ウェブクローラーであり、ClaudeファミリーのAIモデルを訓練し改善するために、一般に公開されているコンテンツを収集するボットです。ClawdBot(現在はOpenClawとしてリブランディングされている)は、オーストリアの開発者Peter Steinbergerによって作られたオープンソースのAIエージェントである。両者には、名前がなんとなく似ているという以上の共通点はない。
混乱は理解できる。スタインバーガーは当初、WhatsApp、Telegram、Discordのようなメッセージング・プラットフォーム上でタスクを自動化できるパーソナルAIアシスタント「Clawdbot」として2025年11月にプロジェクトを立ち上げた。しかし、Anthropicは商標の苦情を申し立て、プロジェクトは2カ月以内に改名された。最初は「Moltbot」、そして2026年1月末までに「OpenClaw」に改名された。
ここが重要な違いだ:
- ClaudeBotは ウェブクローラーです。Anthropicの大規模な言語モデルの学習データを収集するために、あなたのウェブサイトのページを読み込みます。特定のユーザーエージェント文字列でサーバーログに表示され、robots.txtディレクティブを尊重します。
- OpenClaw(旧ClawdBot/MoltBot)はAIエージェントである。ユーザーのデバイス上で動作し、人間のオペレーターに代わってメールの送信、カレンダーの管理、ウェブの閲覧などのタスクを実行する。学習データのためにウェブサイトをクロールすることはない。
アクセスログにClaudeBot 、それはAnthropicだ。自律型AIアシスタントについての会話で誰かが "ClawdBot "と言及したら、それはOpenClawのことです。robots.txtを設定する際、この2つを混同しないでください。一方をブロックしても、もう一方には何の影響もありません。
クロードボットとは?Anthropicのトレーニングクローラーの説明
ClaudeBotはAnthropicの主要なウェブクローラーであり、Claudeを駆動する生成AIモデルを訓練し改善するために使用される可能性のある一般に利用可能なコンテンツを収集するように設計されています。インターネットを体系的に横断し、リンクとサイトマップをたどってウェブページを発見し、ダウンロードします。
ClaudeBotは、Googlebotのような従来の検索エンジンのクローラー(検索結果に表示されるようにページをインデックスする)とは異なり、特に機械学習の目的でコンテンツを収集します。収集されたデータはAnthropicのモデル開発パイプラインに供給され、Claudeが言語、文脈、そしてあらゆるドメインのニュアンスに富んだトピックを理解するのに役立っています。
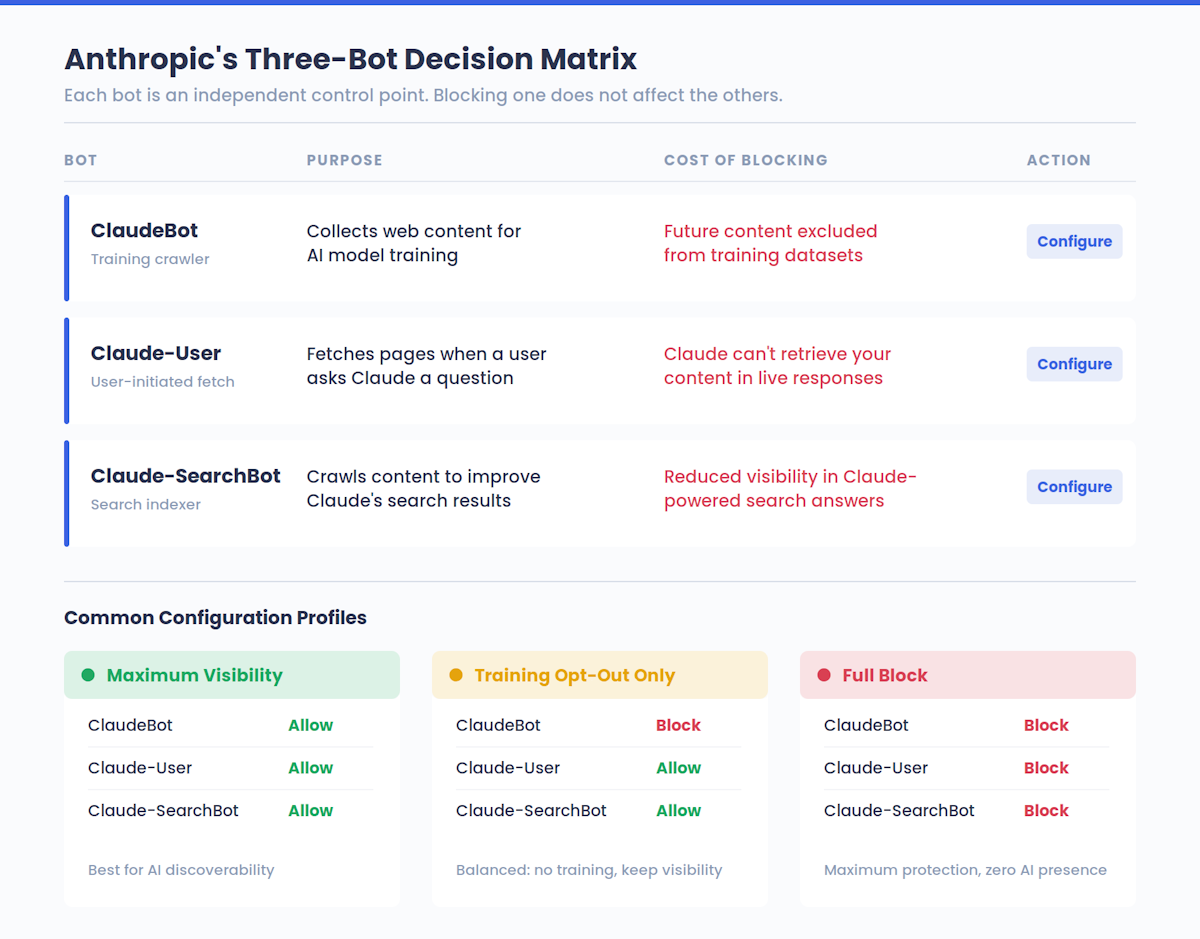
Anthropicは実際には3つの異なるボットを運用しており、それぞれが異なる役割を担っている:
| ボット名 | 目的 | ブロックの効果 |
|---|---|---|
| クロードボット | AIモデルのトレーニングのためにウェブコンテンツを収集 | トレーニングデータセットから将来のコンテンツを除外する |
| クロード・ユーザー | クロード・ユーザーが質問したときにページをフェッチする | クロードがお客様のコンテンツをリアルタイムで取得することを防ぎます。 |
| クロード・サーチボット | クロードの検索結果の質を向上させるためにコンテンツをクローリングする。 | クロードを利用した検索回答におけるあなたの可視性を低下させます。 |
この分離は重要です。ClaudeBotがあなたのコンテンツでトレーニングするのをブロックしても、Claudeユーザーがライブアンサーであなたのページを見るのを防ぐことはできません。また、Claude-SearchBotをブロックしてもトレーニングには影響しません。各ボットは独立したコントロールポイントであり、Anthropicがどのようにコンテンツと相互作用するかについて、ウェブサイト所有者にきめ細かい選択肢を与えます。
この3つ目の列は、実際の戦略的結果をもたらす。このガイドの後半で、可視性のトレードオフの全容を明らかにする。しかし、簡単に説明すると、ほとんどのサイトオーナーは、現在AIプラットフォームがどのような状況にあるのか知らないということだ。何かを変更する前に基準値を知りたいのであれば AIの可視性スコアをチェックするをチェックして、あなたのブランドがクロードや他のAIシステムで今どのように表示されているかを確認してください。
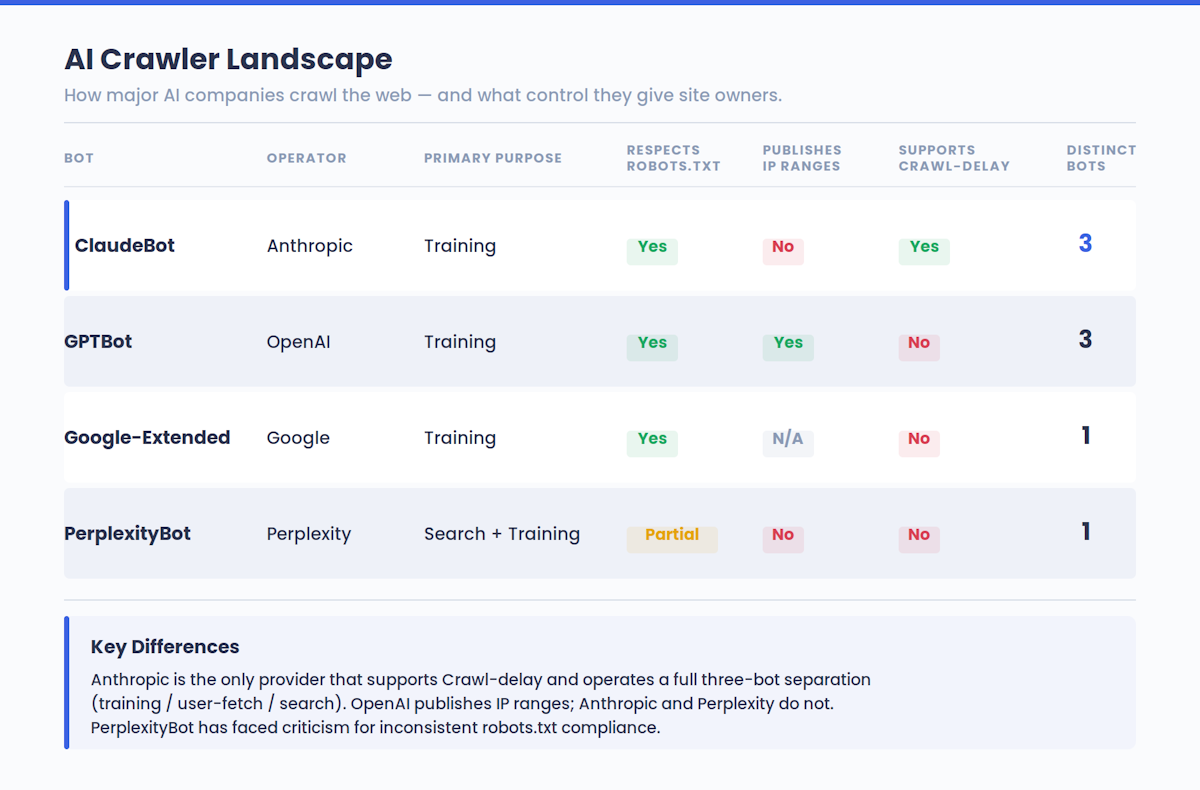
Anthropicは、そのクロールが透明で非破壊的であることを目指していると述べている。ボットはrobots.txtディレクティブを尊重し、CAPTCHAのような回避防止技術を尊重し、レート制限のための非標準的なCrawl-delay 拡張をサポートしています。
ClaudeBotのユーザーエージェント文字列:ログから特定する方法
ClaudeBot は、ユーザーエージェントトークンClaudeBot で自身を識別し、完全なユーザーエージェント文字列に連絡先電子メールを含めます。以下は、サーバーのアクセスログに表示される完全な文字列です:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
特筆すべき技術的な詳細がいくつかある:
- robots.txtのユーザーエージェントトークンは、単に
ClaudeBot。これがディレクティブで参照する文字列です。 - Anthropicは以前、ユーザーエージェント文字列
Claude-WebとAnthropic-AIの下で動作していました。どちらも現在は廃止されています。もしあなたのrobots.txtがまだこれらの古い文字列を参照している場合、あなたのディレクティブは現在のAnthropicのクローラーに対してもはや有効ではありません。 - 他の2つのボットは、独自のトークンを使用している。
Claude-Userはユーザーによるページ取得用、Claude-SearchBotは検索インデックス用である。
ClaudeBotがあなたのサイトを訪問したかどうかを素早くチェックするには、アクセスログに対してgrepを実行します:
grep "ClaudeBot" /var/log/nginx/access.log
アパッチでもいい:
grep "ClaudeBot" /var/log/apache2/access.log
ClaudeBotを名乗るユーザーエージェントからのヒットがある場合は、真偽を確認する価値があります(IP検証については後述します)。ユーザーエージェントの文字列は詐称することができ、悪質な業者は合法的なクローラーになりすまして無制限にコンテンツをスクレイピングすることがあります。
robots.txtでClaudeBotを許可またはブロックする方法
サイトのルートディレクトリにある標準の robots.txt ディレクティブで ClaudeBot のアクセスを制御します。これはAnthropicが推奨する方法で、確実に動作することを保証する唯一の方法です。
サイト全体からClaudeBotをブロックする
User-agent: ClaudeBot
Disallow: /
これは、ClaudeBotにあなたのドメイン上のどのページにもアクセスできないことを伝えます。Anthropicは、サイトがClaudeBotをブロックすると、そのサイトの将来のコンテンツがAIモデルのトレーニングデータセットから除外されるべきであるというシグナルになると述べている。
クロードボットにフルアクセスを許可する
User-agent: ClaudeBot
Allow: /
あるいは、単に ClaudeBot ディレクティブを含めないでください - デフォルトの動作はクロールを許可します。
クロードボットのクロール速度を落とす
User-agent: ClaudeBot
Crawl-delay: 10
これはClaudeBotにリクエスト間で10秒待つように要求し、アクセスを完全にブロックすることなくサーバーの負荷を軽減する。
3つのAnthropicボットを同時にブロックする
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-User
Disallow: /
User-agent: Claude-SearchBot
Disallow: /
重要保護したいすべてのサブドメインにこれらのルールを適用することを忘れないでください。example.com の robots.txt はdocs.example.com やblog.example.com をカバーしません。
また、既存のrobots.txtを監査して、非推奨の文字列Claude-Web とAnthropic-AI を確認してください。もしこれらの文字列がファイルに残っていれば、現在のAnthropicクローラーに対して何の役にも立ちません。上記の3つのアクティブなボット名に置き換えてください。
部分アクセス:ブログは許可、管理者はブロック
robots.txtはパスレベルのルールに対応しており、特定のセクションを開き、他のセクションをロックすることができます。robots.txtはパスレベルのルールに対応しており、特定のセクションを開き、他のセクションをロックすることができます。これは、公開コンテンツのAIトレーニングを可視化したいが、機密性の高いエリアを保護する必要がある企業にとって、賢明な方法です。
ここでは、SaaSプラットフォーム、オンラインストア、暗号プロジェクトなど、ほとんどのサイトで機能する実用的な設定を紹介する:
User-agent: ClaudeBot
Disallow: /admin/
Disallow: /dashboard/
Disallow: /api/
Disallow: /members/
Disallow: /internal/
Allow: /blog/
Allow: /docs/
Allow: /about/
Allow: /
このセットアップでは、ClaudeBot はあなたのブログ投稿、ドキュメント、および公開ページにアクセスできます。このコンテンツは AI の学習に利用でき、Claude がその応答であなたのブランドを参照する可能性が高くなります。一方、管理パネル、API エンドポイント、およびメンバー専用エリアは立ち入り禁止のままです。
一般的なパーシャルアクセスのパターンをいくつか紹介する:
- Eコマースストア:商品ページ、カテゴリーページ、購入ガイドを許可し、カート、チェックアウト、アカウントエリアをブロックする。
- SaaSプラットフォーム:マーケティングページ、価格、ドキュメントを許可し、アプリのダッシュボード、設定、APIルートをブロックする。
- コンテンツパブリッシャー:記事とカテゴリーページを許可し、検索結果ページとユーザー作成コンテンツセクションをブロックすることで、薄いコンテンツや重複コンテンツがトレーニングセットに入るのを防ぐ。
- 暗号とWeb3のプロジェクト:ドキュメント、ブログ、プロトコルの説明を許可する。管理パネル、内部ツール、ゲート化されたコミュニティエリアをブロックする。
Allow 、Disallow のルールは特異性で評価され、より特異なパスが優先されることを覚えておいてほしい。より広いAllow: / が存在しても、Disallow: /admin/ 指令は/admin/settings をブロックする。
ClaudeBotのIPアドレスを確認する方法
Anthropicは、自社のウェブクローラーのIP範囲の固定リストを公表しておらず、同社は、IPベースのブロッキングを主要な防御として依存しないよう助言している。Anthropicのボットはパブリッククラウドのインフラで動作しているため、IPアドレスが変更される可能性があります。IPレンジをブロックすると、ボットがrobots.txtを読めなくなり、意図しないクロール動作につながる可能性もある。
とはいえ、AnthropicはIP検証のための参照リストを提供しています。クローラーがClaudeBotであると主張し、そのソースIPがAnthropicの公開リストに表示された場合、そのクローラーが純粋にAnthropicからのものであることが確認できます。このリストはAnthropicの公式サポートドキュメントに掲載されています。
個々のリクエストを検証するには、DNSの逆引きが最適なツールだ:
# Step 1: Reverse DNS lookup on the crawler's IP
host 216.73.216.1
# Step 2: Forward DNS to confirm
host [result-from-step-1]
逆引きDNSがAnthropic(またはそのクラウドインフラストラクチャ)に関連するドメインに解決する場合、リクエストは本物である可能性が高い。関連性のないドメインに解決したり、完全に失敗した場合は、なりすましのユーザーエージェント(ClaudeBotになりすました誰か)を見ている可能性があります。
より広範なモニタリングについては、以下のアプローチを検討する:
- サーバーログ分析:
ClaudeBot、定期的にログを解析し、Anthropicの公開リストとIPを照合します。 - ボット検知プラットフォーム:Known Agents(旧Dark Visitors)やPlainSignalのようなサービスは、クローラーの訪問を認証し、なりすましのトラフィックにフラグを立てることができるリアルタイムのエージェント分析を提供します。
- リバースプロキシのルール:CloudflareやNginxのようなツールでは、アクセスを許可する前に、既知のIP範囲に対してユーザーエージェントの主張を検証する条件付きルールを作成することができます。
結論:robots.txtを主要な管理メカニズムとして使用し、IP検証を補助的な真正性チェックとして使用する。
ClaudeBotがAIの可視性に与える影響
ClaudeBotへのアクセスに関するすべての決定は、AIが生成した回答に貴社ブランドが表示されるかどうかに直接影響します。これは、技術的なクローラー管理と成長戦略が出会う場所です。

そのトレードオフを分かりやすく説明しよう:
- ClaudeBotを許可する→ あなたのコンテンツがAnthropicのトレーニングパイプラインに入ります。クロードは、ユーザーが関連する質問をしたときに、あなたのブランドについて言及したり、製品について説明したり、サービスを勧めたりする可能性が高くなります。
- ClaudeBot をブロック→ あなたの将来のコンテンツはトレーニングから除外されます。クロードのブランドに関する知識は、ブロック前に収集されたもので停滞する。時間の経過とともに、クロールを許可している競合他社は、AIが生成するレコメンデーションにおいてますます優位に立つ。
このダイナミズムは、クロードだけでなく、AIの世界全体で繰り広げられている。OpenAIのGPTBotも、GoogleのAIクローラーも、Perplexityのボットも、すべて同じような論理で動いている。AIのトレーニングに参加したサイトは、AIの回答に引用される。
あらゆる業界において、利害は具体的である:
- SaaS創業者見込み客がクロードに「リモートチームに最適なプロジェクト管理ツールは何ですか」と尋ねたとき、その答えはクロードが学んだことから導き出される。もし、あなたのドキュメント、比較ページ、機能内訳がその学習の一部であったなら、あなたは推薦されたことになる。もしそうでなければ、あなたの競合他社が選ばれるでしょう。
- Eコマース事業者:買い物客が「偏平足に最適なランニングシューズは何ですか」と尋ねると、クロードが摂取した商品ページや購入ガイドによって形作られた答えが返ってくる。クローラーをブロックしたブランドは、その答えには登場しない。
- 出版社やメディアサイトユーザーがClaudeにトレンドトピックの説明を求めると、Claudeは知っているソースから合成します。あなたのレポートや分析がトレーニングデータにあれば、Claudeはあなたのフレーミングを引用します。そうでない場合は、他の人のシナリオが優位になります。
- 暗号とWeb3プロジェクト投資家が "最良のレイヤー2ソリューションは何か?"あるいは"(あなたのプロトコルは)どのように機能するのか?"と尋ねるとき、その答えはクロードがプロトコルの文書やブログ記事から学んだことを反映する。もしあなたのものが除外されていれば、その読者からは見えないことになる。
いずれの場合も、クロードがアクセスできるコンテンツが、クロードが推薦するコンテンツになるというパターンは同じである。
AIの可視性(AIを活用したプラットフォームで、いかに目立つように、かつ正確にブランドを表示させるか)という概念は、従来のSEOと並ぶ別個の分野として台頭してきている。そのためには、独自の監査、独自の戦略、独自のモニタリングが必要だ。そして、Google Search Consoleでランキングを追跡できる従来のSEOとは異なり、AIの可視性はほとんどのチームにとってブラックボックスだった。
決める前に測る
あなたができる最悪のことは、やみくもにClaudeBotの設定を変更することです。Anthropicの3つのクローラーを許可またはブロックする前に、ベースラインが必要です:Claudeがあなたのブランドについて言及する頻度は?クロードはあなたの製品について正確に説明していますか?代わりに競合他社を勧めているか?
ICODAのAI Visibility Toolは、これらの質問に数分で答えます。このツールは、主要なAIプラットフォーム(Claude、ChatGPT、Perplexity、Gemini)上であなたのブランドがどのように表示されているかをスキャンし、現在の状況を明確に示します。そのデータによって、どのボットを許可し、どのボットをブロックし、AIによる発見可能性のためにサイトのどのセクションを優先させるかについて、情報に基づいた決定を下すことができます。
あなたのAI可視性スコアを今すぐチェック → AI可視性スコア
要点
ClaudeBotの管理は、もはやニッチなシステム管理者の仕事ではありません。それは、AI時代におけるブランドの発見可能性に影響を与える戦略的な決定です。覚えておくべきことは以下の通りです:
- ClaudeBotはAnthropicのトレーニングクローラーで、OpenClawエージェント(旧ClawdBot/MoltBot)やClaude-User、Claude-SearchBotとは別物です。
- robots.txtを主要な制御メカニズムとして使用してください。Anthropicのボットはこれらのディレクティブを確実に尊重します。
- robots.txtで非推奨の文字列(
Claude-Web,Anthropic-AI)を調べ、ClaudeBot,Claude-User,Claude-SearchBotに置き換える。 - 部分的なアクセスルールを使用して、機密領域を保護しながら公開コンテンツを共有できます。
- IPブロックだけに頼らない- AnthropicはIPが変化するクラウドインフラを使用しており、固定のクローラー範囲を公開していません。
- クローラーアクセスの変更を行う前に、ICODAのAI Visibility Toolを使用してベースラインを確立してください。
- 戦略的に考える:AIのクローラーをブロックすることで、コンテンツは保護されるが、AIの可視性は低下する。実際のデータに基づいて、両方の懸念のバランスをとるのが最良のアプローチです。
AIのフットプリントを測定し、最高のコンテンツを選択的にクローラーと共有し、保護が必要なものを保護する-このバランスを理解している企業は、従来の検索とAIが生成する明日の回答ボックスの両方を支配することになるだろう。
よくある質問(FAQ)
公開ページをクロールすることに同意は必要ありません - Googlebotにも同じルールが適用されます。robots.txtのUser-agent: ClaudeBot の下にDisallow: / を追加すると、すぐに停止します。原則よりも帯域幅が問題なら、Crawl-delay: 10 、アクセスをブロックすることなく頻度を絞ることができる。
ClaudeBotはAnthropicのクローラーであり、Googleのインフラとは全く別のものです。本当のトレードオフは、AIの可視性である。ClaudeBotのインデックスから除外されたコンテンツは、Claudeの回答に表示されない。これはSEOとは別の問題だが、ますます重要な問題だ。
ClaudeBot/1.0 本物のClaudeBotは、ユーザーエージェント文字列にclaudebot@anthropic.com 。ソースIPのDNS逆引きを実行して確認してください - Anthropic関連のインフラに解決するはずです。Anthropicは公式ドキュメントで参照IPリストも公開しています。
ClaudeBot はトレーニングデータを収集し、Claude-User はライブアンサー用のページを取得し、Claude-SearchBot は検索機能を提供します。ClaudeBotだけをブロックするとトレーニングは停止しますが、他の2つはアクティブなままです。Anthropicを完全に遮断するには、3つとも明示的なDisallow ルールが必要だ。
包括的なブロックは、AIが生成するレコメンデーションから完全にあなたを除外します。ユーザーがクロードやChatGPTに「Xに最適なツールは何か」と尋ねると、回答はモデルが学習したものから導き出される。パスによる選択的なブロックは、通常、オール・オア・ナッシングの決定よりも賢い。
パスレベルのrobots.txtルールは、これを正確に処理します。Allow: /blog/ と並行してDisallow: /dashboard/ とDisallow: /api/ を使用してください。注意:example.com の robots.txt はapp.example.com をカバーしません。
5分間注目する価値があるAIが生成する回答は、現実的かつ成長しつつあるディスカバリーチャンネルであり、robots.txtのスタンスによって、あなたのコンテンツがそこに表示されるかどうかが決まります。間違いは、ブロックするか許可するかを選択することではなく、意図的な立場を全く持たないことだ。
シェア


記事を評価する












