Если Вы в последнее время проверяли журналы своего сервера, то вполне вероятно, что Вы заметили посетителя по имени ClaudeBot. Это не клиент. Это не хакер. Это веб-краулер компании Anthropic - и он тихо читает Ваш сайт, чтобы помочь обучить одну из самых продвинутых моделей искусственного интеллекта на планете.
Независимо от того, управляете ли Вы SaaS-продуктом, магазином электронной коммерции, медиа-сайтом или блокчейн-проектом, понимание того, что делает ClaudeBot (и чего не делает), уже не опционально. Поскольку AI-поиск меняет то, как пользователи находят контент, то, как Вы взаимодействуете с этими краулерами, напрямую влияет на то, появится ли Ваш бренд в ответах, сгенерированных искусственным интеллектом, - или исчезнет из них совсем.
В этом руководстве описано все, что Вам нужно знать: что такое ClaudeBot, как он себя идентифицирует, как контролировать его доступ с хирургической точностью, и почему Ваши решения здесь могут определить AI-видимость Вашего бренда на годы вперёд.
ClaudeBot против ClawdBot: это не одно и то же
ClaudeBot - это официальный веб-краулер Anthropic- бот, который собирает общедоступный контент для обучения и улучшения моделей ИИ семейства Claude. ClawdBot (в настоящее время переименованный в OpenClaw) - это ИИ-агент с открытым исходным кодом, созданный австрийским разработчиком Питером Штайнбергером. У них нет ничего общего, кроме смутно похожего названия.
Путаница вполне объяснима. Изначально Штайнбергер запустил свой проект под названием "Clawdbot" в ноябре 2025 года - персональный ИИ-помощник, способный автоматизировать задачи на таких платформах обмена сообщениями, как WhatsApp, Telegram и Discord. Но Anthropic подала жалобу о нарушении товарного знака, и в течение двух месяцев проект был переименован - сначала в "Moltbot", а затем в "OpenClaw" к концу января 2026 года.
Вот ключевое различие:
- ClaudeBot - это веб-краулер. Он считывает страницы Вашего сайта, чтобы собрать обучающие данные для больших языковых моделей Anthropic. Он отображается в журналах Вашего сервера с определенной строкой user-agent и соблюдает директивы robots.txt.
- OpenClaw (ранее ClawdBot/MoltBot) - это агент искусственного интеллекта. Он запускается на устройстве пользователя и выполняет задачи - отправку электронной почты, управление календарем, просмотр веб-страниц - от имени человека-оператора. Он не просматривает веб-сайты в поисках обучающих данных.
Если Вы видите ClaudeBot в своих журналах доступа, это Anthropic. Если кто-то упоминает "ClawdBot" в разговоре об автономных ИИ-помощниках, он говорит об OpenClaw. Не путайте эти два понятия при настройке robots.txt - блокировка одного не влияет на другой.
Что такое ClaudeBot? Обучающий кроулер Anthropic - объяснение
ClaudeBot - это основной веб-краулер Anthropic, предназначенный для сбора общедоступного контента, который может быть использован для обучения и улучшения генеративных моделей ИИ, лежащих в основе Claude. Он систематически обходит интернет, следуя ссылкам и картам сайтов, чтобы находить и загружать веб-страницы.
В отличие от традиционных краулеров поисковых систем, таких как Googlebot, которые индексируют страницы, чтобы они появлялись в результатах поиска, ClaudeBot собирает контент специально для целей машинного обучения. Собранные им данные поступают в конвейер разработки моделей Anthropic, помогая Claude понимать язык, контекст и нюансы во всех областях.
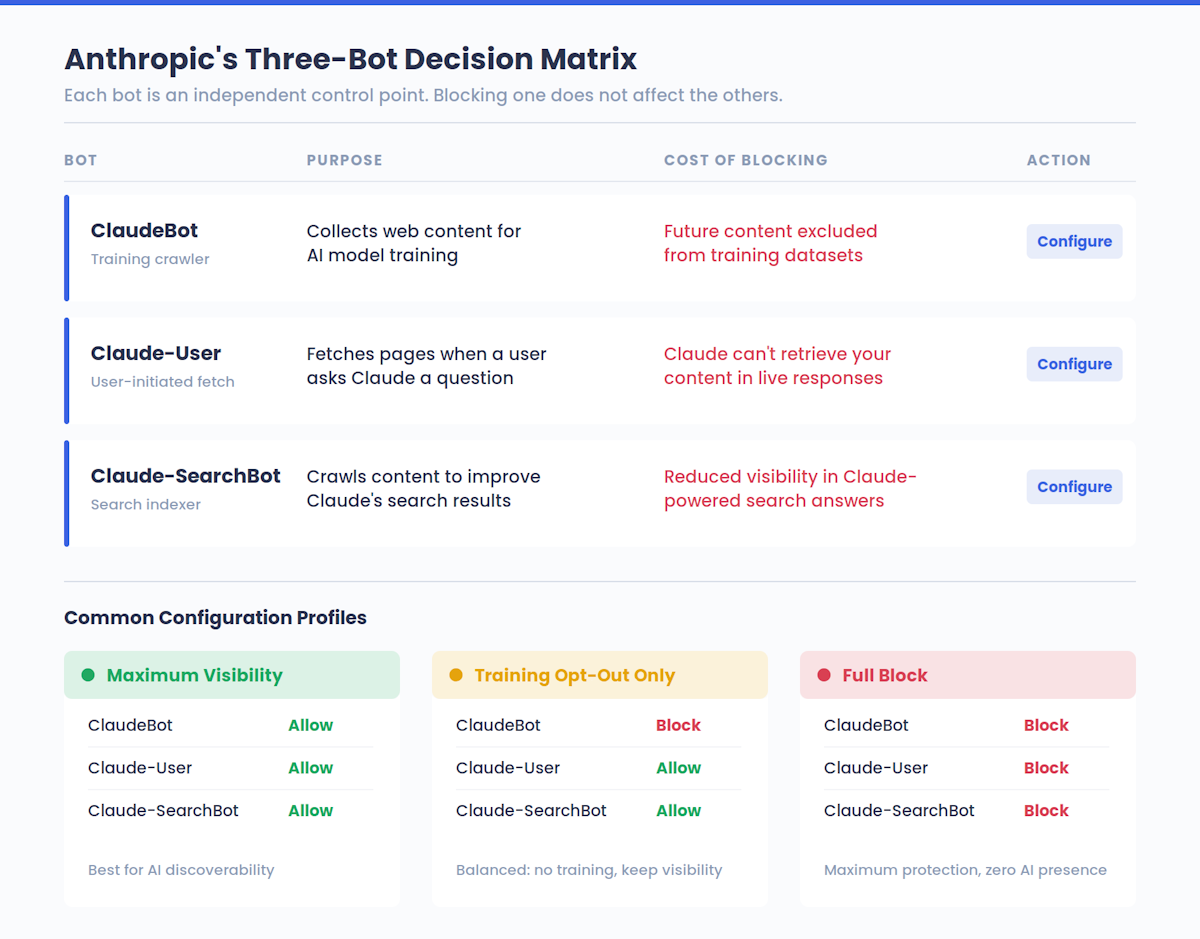
На самом деле Anthropic управляет тремя разными ботами, каждый из которых выполняет свою роль:
| Имя бота | Назначение | Что делает блокировка |
|---|---|---|
| ClaudeBot | Сбор веб-контента для обучения модели искусственного интеллекта | Исключает Ваш будущий контент из обучающих наборов данных |
| Claude-User | Загружает страницы по запросу пользователя Claude | Блокирует получение Вашего контента Claude в режиме реального времени |
| Claude-SearchBot | Сканирует контент для улучшения качества поисковых ответов Claude | Снижает Вашу видимость в поисковых ответах с использованием Claude |
Это разделение имеет значение. Блокировка ClaudeBot от обучения на Вашем контенте не мешает пользователям Claude видеть Ваши страницы в живых ответах - этим занимается Claude-User. А блокировка Claude-SearchBot не влияет на обучение. Каждый бот является независимой точкой контроля, предоставляя владельцам сайтов возможность выбора того, как Anthropic будет взаимодействовать с их контентом.
Эта третья колонка имеет реальные стратегические последствия - мы расскажем о всех компромиссах, связанных с видимостью, позже в этом руководстве. Но вкратце: большинство владельцев сайтов понятия не имеют о своём текущем положении на AI-платформах. Если Вам нужен базовый уровень, прежде чем что-то менять, проверьте свой показатель видимости AI чтобы узнать, как Ваш бренд отображается в Claude и других системах искусственного интеллекта прямо сейчас.
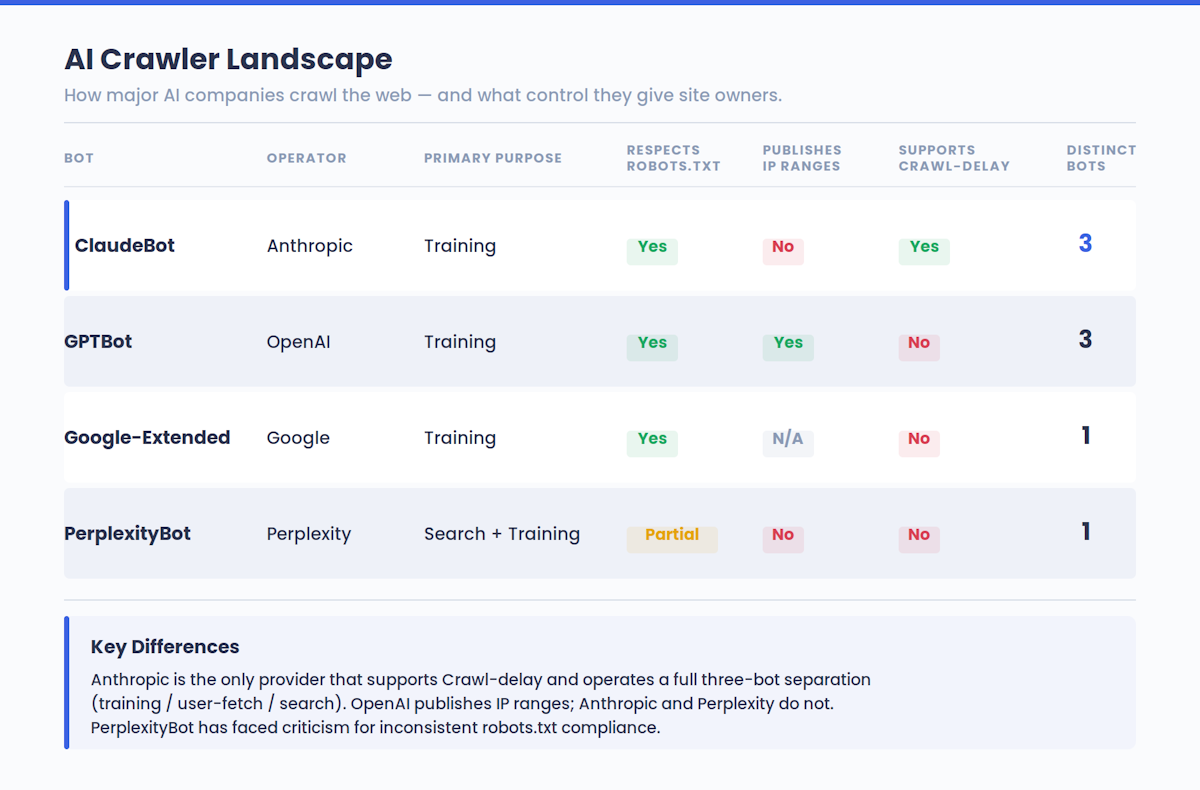
Anthropic заявил, что его краулеры работают прозрачно и ненавязчиво. Боты соблюдают директивы robots.txt, уважают технологии защиты от обхода, такие как CAPTCHA, и поддерживают нестандартное расширение Crawl-delay для ограничения скорости.
Строка пользовательского агента ClaudeBot: Как определить ее в Ваших журналах
ClaudeBot идентифицирует себя с помощью токена user-agent ClaudeBot и включает контактный e-mail в свою полную строку user-agent. Вот полная строка, которую Вы увидите в журналах доступа Вашего сервера:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com)
Несколько технических деталей, на которые стоит обратить внимание:
- Токен user-agent для целей robots.txt - это просто
ClaudeBot. Именно на эту строку Вы ссылаетесь в своих директивах. - Ранее Anthropic работал под строками user-agent
Claude-WebиAnthropic-AI. Теперь обе они устарели. Если Ваш robots.txt все еще ссылается на эти старые строки, Ваши директивы больше не действуют против современных краулеров Anthropic. - Два других бота используют собственные токены:
Claude-Userдля поиска страниц по инициативе пользователя иClaude-SearchBotдля поисковой индексации.
Чтобы быстро проверить, посещал ли ClaudeBot Ваш сайт, выполните grep по журналам доступа:
grep "ClaudeBot" /var/log/nginx/access.log
Или для Apache:
grep "ClaudeBot" /var/log/apache2/access.log
Если Вы замечаете обращения от user-agent, выдающего себя за ClaudeBot, стоит проверить его подлинность (подробнее о проверке IP ниже). Строки user-agent могут быть подделаны, а злоумышленники порой выдают себя за легитимные краулеры, чтобы беспрепятственно парсить контент.
Как разрешить или заблокировать ClaudeBot в robots.txt
Вы контролируете доступ ClaudeBot с помощью стандартных директив robots.txt, размещенных в корневом каталоге Вашего сайта. Это рекомендуемый Anthropic метод - и единственный, который, как они гарантируют, будет работать надежно.
Заблокируйте ClaudeBot на всем Вашем сайте
User-agent: ClaudeBot
Disallow: /
Это сообщает ClaudeBot, что он не может получить доступ ни к одной странице на Вашем домене. Anthropic утверждает, что когда сайт блокирует ClaudeBot, это сигнализирует о том, что будущий контент сайта должен быть исключен из наборов данных для обучения моделей ИИ.
Предоставьте ClaudeBot полный доступ
User-agent: ClaudeBot
Allow: /
Или просто не включайте никакую директиву ClaudeBot — по умолчанию краулинг разрешён.
Ограничьте скорость сканирования ClaudeBot
User-agent: ClaudeBot
Crawl-delay: 10
Это попросит ClaudeBot подождать 10 секунд между запросами, снижая нагрузку на сервер без полного блокирования доступа.
Заблокируйте всех трех ботов Anthropic одновременно
User-agent: ClaudeBot
Disallow: /
User-agent: Claude-User
Disallow: /
User-agent: Claude-SearchBot
Disallow: /
Важно: Не забудьте применить эти правила к каждому поддомену, который Вы хотите защитить. robots.txt на example.com не распространяется на docs.example.com или blog.example.com.
Также уделите время проверке Вашего существующего robots.txt на предмет устаревших строк Claude-Web и Anthropic-AI. Если они все еще присутствуют в Вашем файле, то они ничего не сделают против современных краулеров Anthropic. Замените их тремя активными именами ботов, перечисленными выше.
Частичный доступ: разрешите блог, закройте раздел администратора
Вам не нужно принимать решение "все или ничего" - robots.txt поддерживает правила на уровне пути, которые позволяют Вам открывать определенные разделы, а другие держать под замком. Это разумное решение для любого бизнеса, который хочет включить публичный контент в обучение ИИ, но при этом должен защитить конфиденциальные разделы.
Вот практичная конфигурация, которая подойдет для большинства сайтов - будь то SaaS-платформа, интернет-магазин или криптовалютный проект:
User-agent: ClaudeBot
Disallow: /admin/
Disallow: /dashboard/
Disallow: /api/
Disallow: /members/
Disallow: /internal/
Allow: /blog/
Allow: /docs/
Allow: /about/
Allow: /
При такой настройке ClaudeBot может получить доступ к Вашим записям в блоге, документации и публичным страницам, что делает этот контент доступным для обучения ИИ и повышает вероятность того, что Claude будет ссылаться на Ваш бренд в своих ответах. При этом панели администратора, конечные точки API и области, предназначенные только для пользователей, остаются под запретом.
Несколько типичных схем частичного доступа:
- Магазины электронной коммерции: Разрешите страницы товаров, категории и руководства по покупке; заблокируйте области корзины, оформления заказа и учетной записи.
- SaaS-платформы: Разрешите маркетинговые страницы, цены и документацию; заблокируйте панели приложений, настройки и маршруты API.
- Издатели контента: Разрешите статьи и страницы категорий; заблокируйте страницы результатов поиска и разделы пользовательского контента, чтобы избежать попадания в обучающий набор некачественного или дублирующего контента.
- Криптовалюты и проекты Web3: Разрешите документацию, блог и объяснения протоколов; заблокируйте панели администратора, внутренние инструменты и закрытые зоны сообщества.
Помните, что правила Allow и Disallow оцениваются по специфичности - более специфичные пути имеют приоритет. Директива Disallow: /admin/ будет блокировать /admin/settings, даже если существует более широкая Allow: /.
Как проверить IP-адреса ClaudeBot
Anthropic не публикует фиксированный список диапазонов IP-адресов для своих веб-краулеров, и компания не советует полагаться на блокировку по IP-адресу в качестве основной защиты. Их боты работают через публичную облачную инфраструктуру, а значит, IP-адреса могут меняться. Блокирование диапазонов IP-адресов также может помешать боту прочитать Ваш robots.txt, что может привести к непреднамеренному поведению краулера.
Тем не менее, Anthropic предоставляет справочный список IP-адресов для верификации. Если краулер утверждает, что он ClaudeBot, а его IP указан в этом списке, это подтверждает, что краулер действительно из Anthropic. Вы можете найти этот список в официальной документации поддержки Anthropic.
Для проверки отдельных запросов лучше всего использовать обратный поиск DNS:
# Step 1: Reverse DNS lookup on the crawler's IP
host 216.73.216.1
# Step 2: Forward DNS to confirm
host [result-from-step-1]
Если обратный DNS разрешается в домен, связанный с Anthropic (или его облачной инфраструктурой), запрос, скорее всего, подлинный. Если он разрешается в домен, не имеющий отношения к Anthropic, или вообще не выполняется, возможно, перед Вами поддельный пользовательский агент - кто-то выдает себя за ClaudeBot.
Для более широкого мониторинга рассмотрите эти подходы:
- Анализ журналов сервера: Регулярно анализируйте свои журналы на предмет записей
ClaudeBotи сверяйте IP-адреса с опубликованным списком Anthropic. - Платформы для обнаружения ботов: Такие сервисы, как Known Agents (ранее Dark Visitors) и PlainSignal, предлагают аналитику агентов в режиме реального времени, которая позволяет установить подлинность посещений краулеров и выявить поддельный трафик.
- Правила обратного прокси: Такие инструменты, как Cloudflare и Nginx, позволяют Вам создавать условные правила, которые сверяют заявленный user-agent с известными диапазонами IP-адресов перед тем, как предоставить доступ.
Итог: используйте robots.txt как основной инструмент контроля, а проверку IP-адресов — как дополнительное подтверждение подлинности, а не наоборот.
Как ClaudeBot влияет на Вашу видимость ИИ
Каждое Ваше решение относительно доступа к ClaudeBot напрямую влияет на то, появится ли Ваш бренд в ответах, сгенерированных искусственным интеллектом, - канал, который быстро становится таким же важным, как и традиционный поиск. Именно здесь техническое управление краулерами пересекается со стратегией роста.

Вот компромисс в простом изложении:
- Разрешить ClaudeBot → Ваш контент попадает в обучающий конвейер Anthropic. Клод с большей вероятностью будет ссылаться на Ваш бренд, объяснять Ваш продукт или рекомендовать Ваши услуги, когда пользователи будут задавать соответствующие вопросы.
- Заблокировать ClaudeBot → Ваш будущий контент исключается из обучения. Знания Клода о Вашем бренде остаются на уровне того, что было собрано до блокировки. Со временем конкуренты, разрешившие краулинг, получают всё большее преимущество в AI-рекомендациях.
Такая динамика наблюдается не только в Claude, но и во всей экосистеме ИИ. GPTBot от OpenAI, ИИ-краулеры Google и бот Perplexity работают по схожей логике. Сайты, которые участвуют в обучении ИИ, цитируются в ответах ИИ.
Последствия ощутимы в каждой отрасли:
- Основатели SaaS: Когда потенциальный клиент спрашивает Клода: "Какой лучший инструмент управления проектами для удаленных команд?", ответ строится на том, чему Клод научился. Если Ваша документация, страницы сравнения и описание функций были частью этого обучения, Вы окажетесь в числе рекомендованных. Если нет — Ваш конкурент.
- Операторы электронной коммерции: Покупатель, задающий вопрос "Какие кроссовки лучше всего подходят для плоскостопия?", получает ответ, сформированный на страницах товаров и руководств по покупке, из которых обучался Клод. Бренды, заблокировавшие краулер, в этом ответе не появятся.
- Издательства и сайты СМИ: Когда пользователи просят Клода объяснить модную тему, он синтезирует ответ из известных ему источников. Если Ваши репортажи и анализ были включены в обучающие данные, Клод будет ссылаться на Вашу версию событий. Если нет — доминировать будет чужая.
- Криптовалюты и проекты Web3: Когда инвестор спрашивает: "Какие решения уровня 2 являются лучшими?" или "Как работает [Ваш протокол]?", ответ отражает то, что Клод узнал из документации по протоколу и записей в блогах. Если Ваш протокол был исключен, Вы невидимы для этой аудитории.
Во всех случаях закономерность одна: контент, к которому Клод имеет доступ, становится контентом, который Клод рекомендует.
Концепция AI visibility - то, насколько заметно и точно Ваш бренд отображается на AI-платформах, - становится отдельной дисциплиной наряду с традиционным SEO. Это требует отдельного аудита, собственной стратегии и самостоятельного мониторинга. И в отличие от традиционного SEO, где Вы можете отслеживать рейтинги в Google Search Console, AI visibility оставалась «чёрным ящиком» для большинства команд — до недавнего времени.
Измерьте, прежде чем принять решение
Худшее, что Вы можете сделать, - это вслепую изменить конфигурацию ClaudeBot. Прежде чем разрешать или блокировать любой из трех краулеров Anthropic, Вам необходимо определить базовый уровень: Как часто Claude упоминает Ваш бренд сегодня? Точно ли он описывает Ваш продукт? Рекомендует ли он вместо него конкурентов?
Инструмент ICODA "Видимость ИИ " отвечает на эти вопросы за считанные минуты. Он сканирует, как Ваш бренд отображается на основных платформах ИИ - Claude, ChatGPT, Perplexity, Gemini - и дает Вам четкое представление о Вашем текущем положении. Вооружившись этими данными, Вы сможете принимать взвешенные решения о том, каких ботов разрешить, каких заблокировать, и какие разделы Вашего сайта приоритизировать для AI-видимости.
Проверьте свой показатель видимости ИИ прямо сейчас →
Основные выводы
Управление ClaudeBot больше не является нишевой задачей сисадмина - это стратегическое решение, которое влияет на видимость Вашего бренда в эпоху ИИ. Вот что следует помнить:
- ClaudeBot - это обучающий краулер Anthropic, отдельный от агента OpenClaw (ранее ClawdBot/MoltBot) и от Claude-User и Claude-SearchBot.
- Используйте robots.txt в качестве основного механизма контроля. Боты Anthropic надежно соблюдают эти директивы.
- Проверьте свой robots.txt на наличие устаревших строк (
Claude-Web,Anthropic-AI) и замените их наClaudeBot,Claude-User, иClaude-SearchBot. - Используйте правила частичного доступа, чтобы делиться своим публичным содержимым, защищая при этом конфиденциальные области.
- Не полагайтесь только на блокировку IP-адресов - Anthropic использует облачную инфраструктуру с меняющимися IP-адресами и не публикует фиксированные диапазоны краулеров.
- Сначала измерьте видимость AI - воспользуйтесь инструментом ICODA " AI Visibility Tool", чтобы установить базовый уровень, прежде чем вносить какие-либо изменения в доступ краулеров.
- Мыслите стратегически: блокирование краулеров ИИ защищает Ваш контент, но снижает видимость ИИ. Лучший подход уравновешивает обе проблемы, основываясь на реальных данных.
Компании, которые понимают этот баланс - измеряют свой AI-след, выборочно делятся своим лучшим контентом с краулерами и защищают то, что нуждается в защите, - именно они будут доминировать как в традиционном поиске, так и в AI-ответах завтрашнего дня.
Часто задаваемые вопросы (FAQ)
Ползание по публичным страницам не требует согласия - то же правило действует и для Googlebot. Добавьте Disallow: / под User-agent: ClaudeBot в robots.txt, и он немедленно остановится. Если для Вас важна пропускная способность, а не принцип, Crawl-delay: 10 снижает частоту, не блокируя доступ.
Блокировка ClaudeBot не влияет на рейтинг Google - это краулер Anthropic, полностью отделенный от инфраструктуры Google. Реальный компромисс - это видимость AI: контент, исключенный из индекса ClaudeBot, не будет появляться в ответах Claude. Это проблема, отличная от SEO, но становящаяся все более важной.
Аутентичный ClaudeBot идентифицируется как ClaudeBot/1.0 с claudebot@anthropic.com в строке user-agent. Проверьте это, выполнив обратный поиск DNS по IP-адресу источника - он должен разрешиться в инфраструктуру, связанную с Anthropic. Anthropic также публикует список эталонных IP-адресов в своей официальной документации.
Каждый бот служит отдельной цели: ClaudeBot собирает данные для обучения, Claude-User ищет страницы для живых ответов, Claude-SearchBot обеспечивает работу функции поиска. Блокировка только ClaudeBot останавливает обучение, но оставляет двух других активными. Чтобы полностью отключить Anthropic, всем троим нужны явные правила Disallow.
Блокировка полностью исключает получение рекомендаций от ИИ. Когда пользователи спрашивают у Claude или ChatGPT: "Какой инструмент лучше всего подходит для X", ответы формируются на основе того, что узнали модели - сайты, которые заблокировали краулеры, не появляются. Выборочная блокировка по пути обычно более разумна, чем решение "все или ничего".
Правила robots.txt на уровне путей точно справляются с этой проблемой. Используйте Disallow: /dashboard/ и Disallow: /api/ наряду с Allow: /blog/ - более конкретные пути имеют приоритет. Примечание: robots.txt на example.com не распространяется на app.example.com; субдоменам нужен свой собственный файл.
Это стоит пяти минут внимания. Ответы, сгенерированные искусственным интеллектом, являются реальным и растущим каналом открытий - Ваша позиция в robots.txt определяет, появится ли в них Ваш контент. Ошибка заключается не в выборе блокировать или разрешать, а в отсутствии продуманной позиции.
Поделиться


Оцените статью












