
你目前阅读的所有内容的问题所在
大多数人工智能模式报道都会陷入两种失败模式之一。第一种是气喘吁吁的产品新闻,只描述功能而不解释底层机器。第二种是从业者的安慰性报道,他们吸收了谷歌的观点并将其传播开来-"标准的 SEO 就是你所需要的一切"、"优质内容制胜"、"一切都没有发生根本性的改变"。
这两种做法都是错误的,都会给品牌带来损失。
这篇文章深入浅出。它建立在谷歌的专利文件、经过验证的定量研究,以及更广泛的社区明显没有认真对待的一些发现之上。目的很简单:到最后,你应该明白 AI 模式到底是如何工作的,它为什么会打破传统 SEO 的正统观念,以及到底该怎么做。
我们要讲的内容很多。从最重要的事情开始,几乎所有人都弄错了。
什么是人工智能模式?
这就是目前行业中最昂贵的误解:人工智能模式是你已经知道的东西的智能版本。
其实不然。而将其与我们熟悉的系统混为一谈已经造成了真正的战略错误-品牌在优化 AI Overviews 可见性时假定它可以转移,SEO 团队引用 ChatGPT 行为作为类比,从业者将 AI 模式视为更复杂的精选片段。这些都是分类错误。它们会导致错误的投资决策和错误的衡量框架。
因此,让我们对分类法进行外科手术式的研究。
经典搜索
文档检索系统。你输入一个查询,它就会返回一个排列有序的 URL 列表。谷歌的工作到 SERP 结束。至于你如何处理这些蓝色链接,那就是你的事了。二十年来,这里的优化游戏一直很稳定:向爬虫发出权威信号、匹配关键词意图、赢得参与信号。你知道这个系统。
人工智能概述(AIO)
经典搜索之上的生成层。AIO 将谷歌现有的检索结果合成为一个摘要段落,几乎完全取自排名靠前的网页-76.1% 的 AI 概述引文来自排名前 10 的结果。这是一个用户界面功能,而不是一个新的检索系统。可以将其视为由语言模型撰写文案的智能片段。它下面的索引没有变化;它下面的排名信号也没有变化。经典的 SEO 只要应用得当,基本上就能满足 AIO 的要求。
SGE(搜索生成体验)
死亡。实验室实验一直持续到 2023-2024 年。不要再把它当作一个活的系统。
双子座(独立)
法律硕士助手没有与谷歌实时搜索索引的持久连接。没有知识图谱集成。没有购物图谱。其响应来自训练数据,而非实时检索。推理管道与本列表中的其他产品完全不同。
Perplexity 和 ChatGPT 搜索
检索增强生成(RAG)系统从公共网络索引中提取内容并合成答案。Perplexity 采用实时抓取;ChatGPT 则在运行时通过必应 API 抓取完整的 URL 内容。它们的检索相对简单-没有持久的用户模型,没有多层知识基础设施,没有跨会话的有状态上下文。
人工智能模式
以上都不是。
AI Mode 是一个多阶段、有状态、个性化的段落级检索和合成引擎,它针对谷歌的全部知识基础设施(搜索索引、知识图谱、购物图谱(50B 多种产品)和地图)发起多个并行子查询,并将检索到的段落组装成一个自定义语料库,使用成对的 LLM 对其重新排序,并生成带有片段级引用验证的响应。
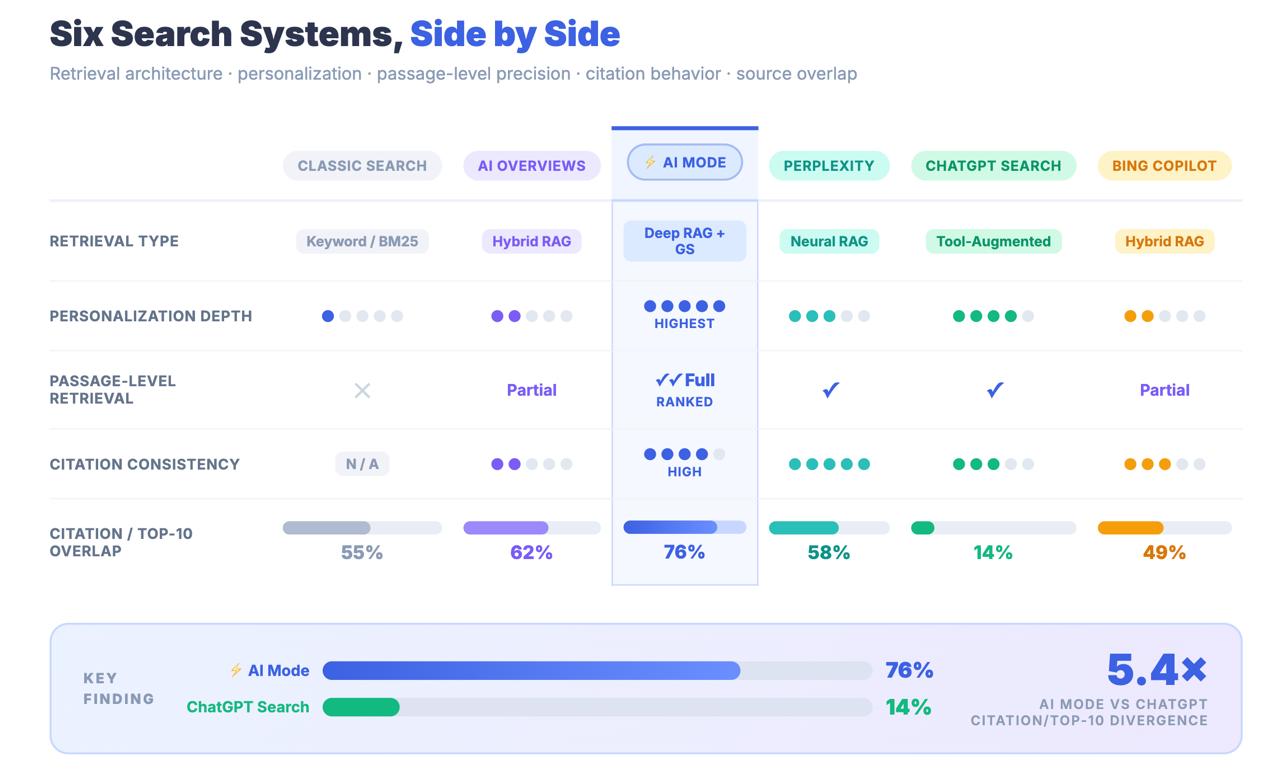
它不是经典搜索的包装。它是一个平行的搜索系统,碰巧存在于同一产品中。而这个数字应该会让你吓一跳:
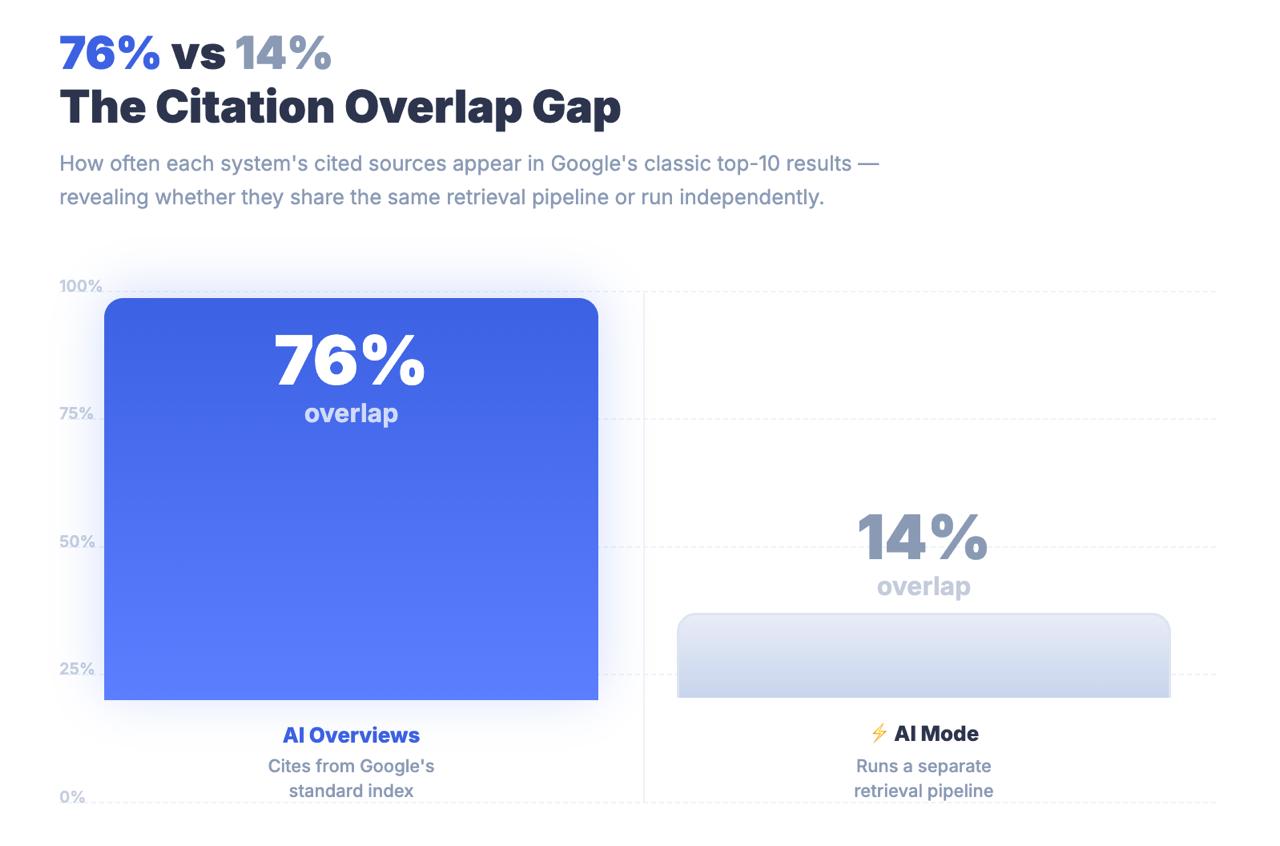
人工智能模式引用的 URL 中,只有 14% 排在谷歌传统的前 10 位。
就人工智能概述而言,这一数字为 76%。这两个数字之间的差距并不是四舍五入的误差。这是一个架构上的发现,它告诉你人工智能模式并不是通过传统的排名信号来查找内容的。它是通过一个完全不同的检索管道来查找内容的-而让你排到第一页的优化策略可能与你是否被引用基本无关。
对于人工智能概述的可见性来说,在谷歌第一页是必要的;而对于人工智能模式来说,这在很大程度上是无关紧要的。
这两个系统的关系就像图书馆和研究助理的关系一样。两者都处理书籍。一个给你一个排好序的书架。另一个则为你阅读书籍,归纳答案,并决定哪些段落值得引用。你的工作在本质上是不同的,这取决于你在优化哪一个系统,而现在,大多数团队都在优化书架,而研究助理才是他们的受众正在使用的系统。
主要启示人工智能模式与谷歌搜索共享一个品牌,与人工智能概述共享一个URL,但它是一个结构独特的检索系统。只有14%的AI模式引用来自传统的前10名结果,而AI概述的引用率为76%。将 AI Mode 视为 AIO 扩展是一种测量误差,会带来真正的战略后果。
架构:查询如何成为答案
对人工智能模式的大多数解释都是从外部描述它的作用:"它能更好地理解你的查询"、"它能综合多种来源"、"它能提供对话式的回答"。这些描述并没有错。但它们对优化毫无用处。
接下来,我们将逐一介绍整个流水线的各个组成部分,以及每个阶段的专利。这就是优化对目标的实际意义-因为你无法系统地改进一个你无法命名的系统。
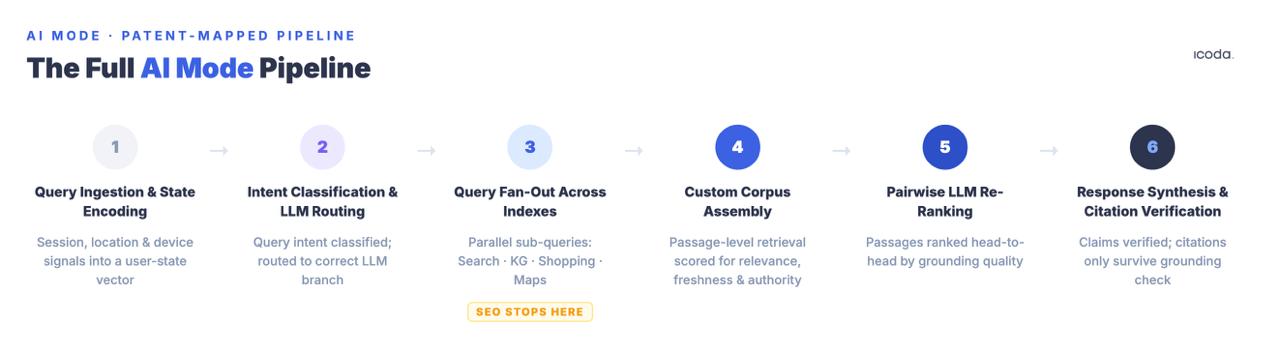
六阶段管道实际上就是你要优化的。目前的大多数做法只针对一个阶段。
第 1 阶段:查询输入和用户状态编码
原始查询不会直接进入检索。它首先与用户的状态上下文向量配对-这是一种密集嵌入,由会话历史记录、所有会话中的先前查询、设备、位置、时间和 Google 生态系统信号(搜索、地图、Gmail、YouTube)构建而成。这个个性化向量会在任何检索开始之前修改 "此查询的含义"。
两个输入相同查询的用户实际上发出了不同的检索指令。这一点影响重大,值得在本节之后单独讨论。
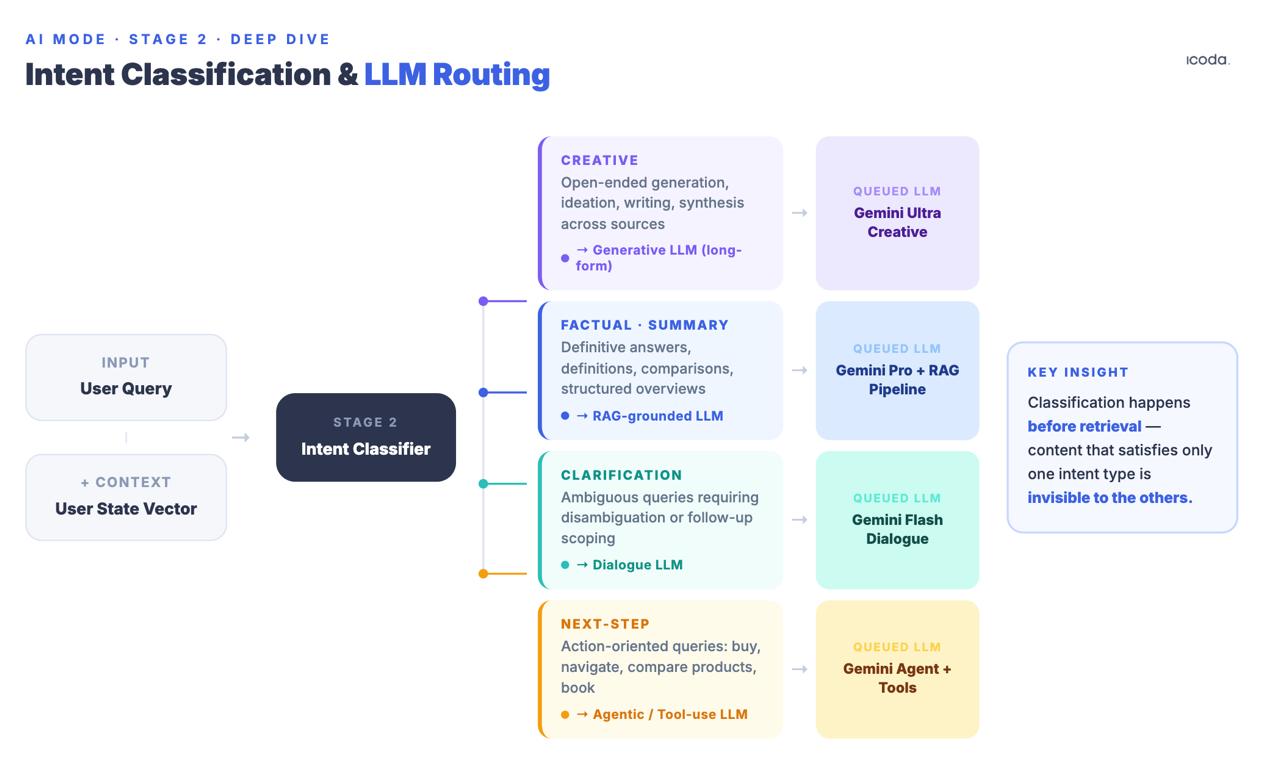
第 2 阶段:查询意图分类和 LLM 路由
在检索之前,系统会将查询按意图分类:创意、事实/摘要、说明或下一步/任务。在此分类基础上,不同的下游语言模型被排成队列。有状态聊天专利(US20240289407A1)明确命名了这些模型:创意文本 LLM、SRP 生成 LLM、澄清 LLM、下一步 LLM。
这发生在检索之前。分类不仅决定了由哪个模型合成响应,还决定了哪些检索信号最重要。如果意图分类器将一个在信息查询中排名靠前的页面导向下一步的 LLM,而 LLM 的优化目标是完成任务而不是信息合成,那么这个页面可能根本不会进入候选池。
第 3 阶段:查询扇出
这也是人工智能模式与之前所有系统最大的不同之处。
该系统从原始数据生成多个合成子查询,涵盖八种记录的变体类型:等同、相关、隐含、比较、澄清、时间、地理和专业背景。注意申报日期。谷歌开发多查询扇出功能已有七年之久。人工智能模式是一个漫长架构跑道上的消费产品。
隐含 "和 "比较 "变体类型值得特别关注,因为它们会生成用户没有提出但可能需要的查询。如果有人搜索 "最适合初创公司的 CRM",扇出生成的不仅是重构,还有隐含查询("什么 CRM 可以扩展到 A 轮融资之后?")、比较查询("Salesforce 与 HubSpot 对于早期公司的对比")、时间查询("CRM 定价 2025 年的变化"),以及专业背景变体,以区分正在进行研究的创始人和正在进行决策的 RevOps 经理。
所有子查询可同时在谷歌搜索索引、知识图谱、购物图谱和地图上运行。谷歌已经证实,人工智能模式可以对一个复杂的查询进行 "数百次搜索"。主题搜索专利(US12158907B1)将搜索结果组织成语义集群;子主题会迭代触发额外的检索轮次-这意味着扇出可以递归,而不仅仅是一次爆发。
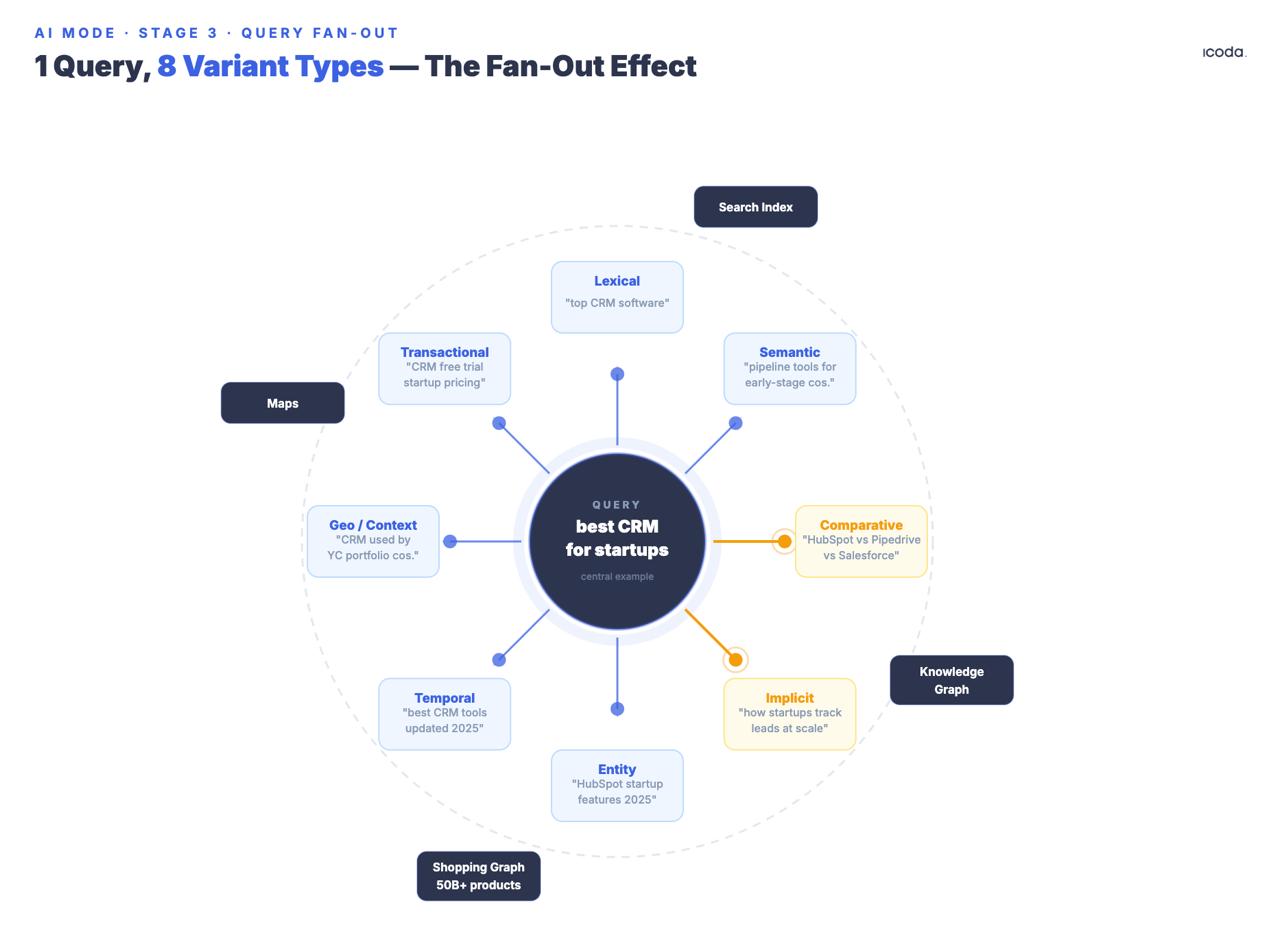
谷歌在 2018 年申请了基础性扇出专利-AI 模式是历经七年架构打造的消费级产品。
如果一个品牌拥有 "最佳客户关系管理 "方面的权威内容,但没有任何比较性、时间性的内容,也没有任何针对专业背景变体的内容,那么该品牌就不会在每个相关会话中出现多个查询类型。扇出并不关心你的域名权威性,它关心的是每个变体子查询是否会出现一个在成对比较中获胜的段落。
第 4 阶段:定制语料库组装
检索到的段落-不是文档,而是段落-被组合成一个自定义语料库。专利 WO2024064249A1 描述了系统如何检索相关段落周围最多五个相邻的语块,以保持上下文的连贯性。这意味着文档章节中的散文流非常重要。一个结构良好的论点如果能获得检索命中,就会将周围的段落一起拉入语料库。
语料库是定制的。每个用户、每个会话、每个查询都会产生不同的语料库。您的内容并不在一个通用的文档库中竞争,而是在数百万个用户特定的文档库中按需组合。
第 5 阶段:成对 LLM 重新排序
来自所有扇出子查询的段落相互竞争。排序机制不是 BM25。也不是 TF-IDF。LLM 是成对地比较段落-哪个段落更能满足给定的子查询?- 进行多轮比较。胜者晋级,败者出局。
这一阶段是目前大多数 SEO 投资未能取得联系的地方。在第一句话中就能回答特定子问题的密集、直接、事实性段落能在配对比较中获胜。叙事性、议论性、观点性强的内容-这种在长篇编辑 SEO 中表现出色的内容-往往会败下阵来,因为它让 LLM 更难提取相关的主张。在 Reddit 上,一个直接回答利基问题的主题可能会胜过一个将答案隐藏在第八段的 3000 字权威指南。成对机制奖励的是即时回报,而不是累积的可信度。
第 6 阶段:答复综合与引用核实
残存的段落被输入到双子座。Gemini 会生成自然语言回复。然后,"回应链接引擎 "会执行片段级验证:它会将生成的回应中的每个片段与特定语料库段落进行匹配,并嵌入引文。
这不是页面级别的引用。回复中的一句话与您博客中的一段话相吻合,就可以获得引用。而页面的其他部分可能根本不会被引用。一篇事实密集的 400 字文章可以胜过一篇 3000 字的权威指南-因为它在单位文本中产生了更多可验证的片段。这种机制在结构上奖励的是论断密度,而不是全面覆盖。这直接颠覆了传统长篇 SEO 的优化目标。
主要启示人工智能模式是一个六阶段管道。传统的 SEO 主要解决第 3 阶段(检索资格)的问题。引文的得失取决于第 4-6 阶段-段落级密度、成对 LLM 竞争和片段级事实基础-标准优化实践都无法解决这些问题。
个性化层:为什么排名跟踪的衡量标准是虚构的?
AI 模式架构中蕴含着一个事实,而 SEO 行业尚未充分考虑到这一点。让我们直截了当地说出来:
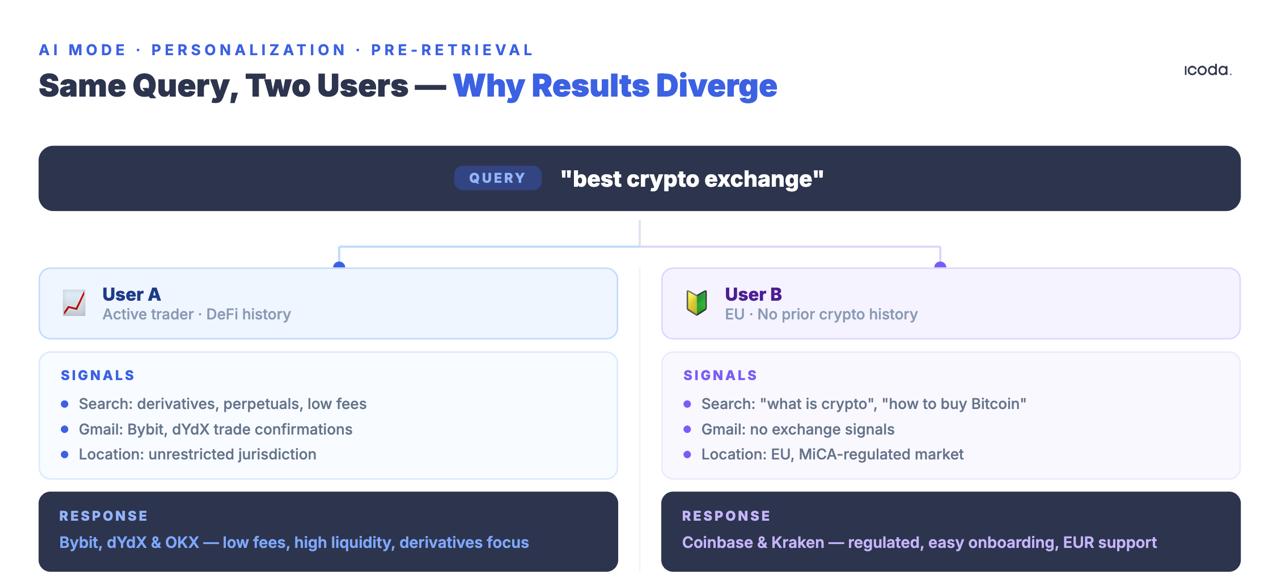
两个不同用户发出的相同查询会产生不同的检索集。不是相同文件的不同排名。而是完全不同的文档。
用户嵌入模型专利描述了谷歌如何将行为信号-查询、点击、停留时间、位置历史记录、地图活动、YouTube 观看历史记录、Gmail 内容-编码成密集向量,并与每个进入的查询配对。在应用任何传统排名信号之前,个性化向量会修改检索。
您不是在与竞争对手争夺一个普遍的排名位置。您是在特定的用户个性查询上下文中争夺相关性,您无法直接观察、直接测量,也无法在排名跟踪工具中复制。
为用户提供什么 嵌入
有状态聊天专利(US20240289407A1)和用户嵌入模型专利共同描述了一种个性化堆栈,该堆栈借鉴了以下技术:
- 所有 Google 搜索会话的完整查询历史记录(针对已登录用户)
- 综合行为规模的点击、悬停和停留模式
- 设备类型和位置信号
- Google 生态系统数据:地图签到、按主题划分的 YouTube 观看时间、Gmail 内容
最后一个类别值得一提。个人语境 "功能在2025年谷歌I/O大会上进行了预览,并在2026年初进行了部分部署,它将明确地把Gmail、日历和谷歌账户数据直接纳入检索。当该功能全面推出时,上周通过电子邮件发送滑雪旅行信息的用户与最近在谷歌购物网站上购买跑鞋的用户将获得不同的人工智能模式对 "冬季户外装备 "的响应。任何查询的典型搜索结果概念都将在功能上消亡。每个结果都将是用户在整个谷歌生态系统中行为历史的产物,而不仅仅是他们的搜索查询。
测量结果
排名跟踪工具是从无尘室、非情境化环境中进行查询的。而真实用户是深度情景化的。该工具测量的是一个假设的位置,而真实用户看不到这个位置。
这不是精确性方面的投诉。这是对有效性的抱怨。测量不是不精确,而是完全测量错了。与人工智能模式相对应的排名跟踪器的位置跟踪数字代表的是一个没有搜索历史、没有位置信号、没有生态系统数据、没有会话上下文的用户的体验。该用户不存在任何有意义的数量。
反垄断裁决以一种具有讽刺意味的方式强化了这一点。2025 年 12 月的补救措施要求谷歌在五年内两次与竞争对手共享搜索索引。但它不能共享用户嵌入模型。索引数据-现在已成为一种商品-并不是人工智能模式个性化的驱动力。学习飞轮才是:每天 140 亿次查询,不断更新的用户嵌入模型是竞争对手无法复制的。竞争对手获得的是书架的快照。而谷歌却能让图书管理员读懂每一位读者的表情。
对测量有效的方法
最能驾驭这种情况的品牌并不是那些拥有最高保真度排名跟踪的品牌。它们接受了个性化人工智能检索需要不同的衡量范式这一观点,并为此而努力。四种具有真实信号的代理:
通过第三方工具(Profound、ZipTie、Ahrefs Brand Radar)跟踪的人工智能回复中的品牌声音份额。这些工具是基于抽样的近似值,并非完全覆盖-但它们衡量的是引用的存在,这是正确的输出变量。对照竞争对手进行跟踪,而不是对照绝对分数。
在查询段层面实现 GSC 印象/点击解耦。 信息查询显示印象上升而点击率下降,这是人工智能模式蚕食的主要明显特征。按意图类型进行细分;随着时间的推移,观察分歧会越来越明显。
针对 20 个最重要的商业查询进行人工智能模式引文审核。 注意哪些页面被引用,哪些段落出现在回复中,以及您的品牌是否出现在以竞争对手为重点的扇出子查询中-因为有时会出现。人工智能模式平均每个回复会产生 3.3 个实体提及,而人工智能概述则为 1.3 个。您的品牌可能会出现在从未点击过您的域名的会话中。
将品牌搜索量作为下游信号。 如果 "人工智能模式 "能够在不带动直接点击的情况下提高品牌知名度,那么品牌搜索量就会在 60-90 天的时间窗口内作为滞后指标出现变化。
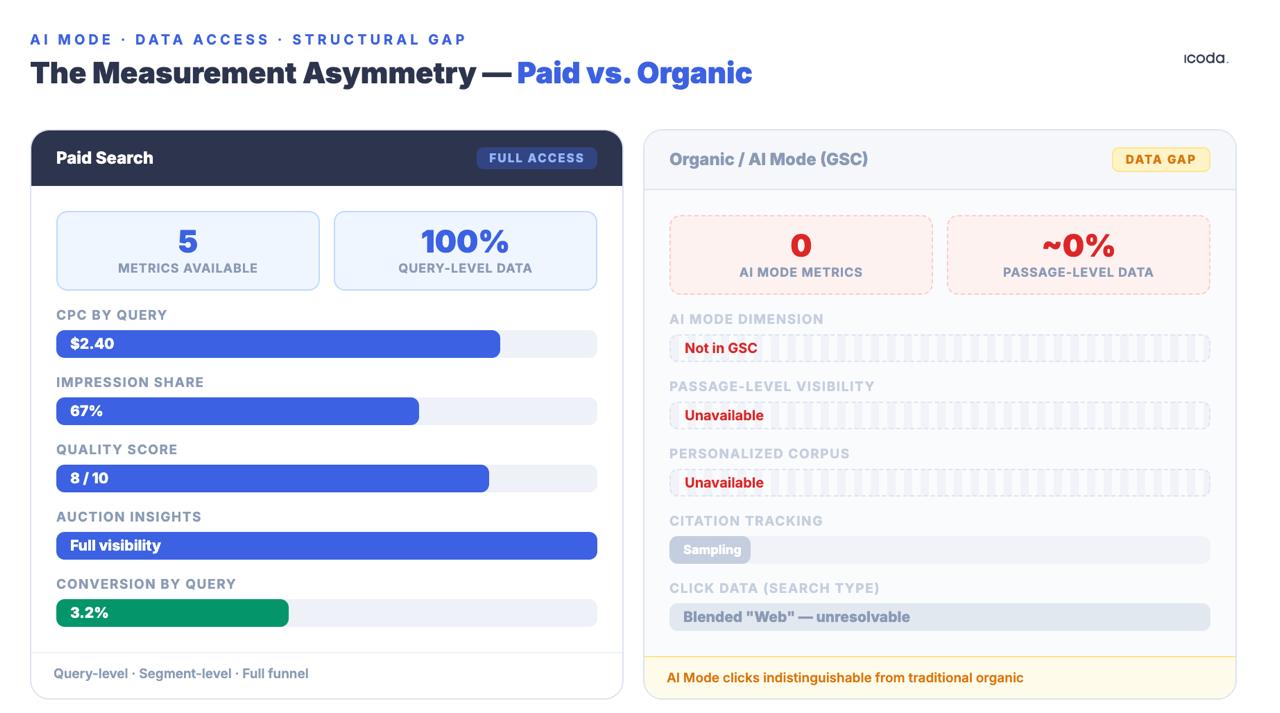
付费搜索和有机搜索之间的衡量差距已存在多年。人工智能模式将其扩大为结构性鸿沟。
这些都不完美。与付费搜索团队之间的不对称是结构性的,也是重要的:付费团队拥有 CPC 数据、印象份额、质量分数和查询层面的拍卖洞察力。而有机团队获得的 GSC 数据则是刻意汇总、抽样和匿名的,人工智能模式点击被混入通用的 "网络 "搜索类型,与传统的有机流量无法区分。这种差距不是暂时的工具问题。它是一个经过深思熟虑的产品架构决策,而且随着人工智能模式使有机检索变得更加不透明,而不是更加不透明,它还在不断扩大。
诚实的回答是,您目前无法精确测量人工智能模式的可见性。你可以衡量代理。你可以跟踪品牌存在。您可以实时观察印象/点击比率的恶化情况,并以此确定优先顺序。但是,您不应该将代理测量与地面实况混为一谈,您也不应该再假装一个指向非语境化查询的排名跟踪器能告诉您真实的、登录的、语境化的用户在人工智能模式下是如何体验您的内容的。
主要启示用户嵌入向量会在传统排名信号应用之前修改人工智能模式检索,从而使排名跟踪(目前的做法)成为对不存在的用户的衡量。在人工智能响应中,将主要衡量标准从位置转向品牌声音份额,并辅以 GSC 解耦信号和人工引用审计。
结论
人工智能模式不是更智能的经典搜索。它是一个独立的检索系统-六个阶段、段落级、个性化,然后才是任何排名信号-它已经在决定受众正在阅读的答案中存在哪些品牌。
14% 的引用量与传统排名前十的结果重叠,说明了一切:排名和引用量现在是独立变量。你可以占据第一页,但在人工智能模式下却无迹可寻。如果您的内容能在正确的子查询变体的成对 LLM 比较中获胜,您就可以排在第 47 位,并获得持续的引用。
架构已记录在案。专利是公开的。在人工智能模式成为默认搜索体验之前,适应的窗口期是以季度计算的,而不是以年计算。
接下来会发生什么是一个选择。
分享


给文章评分












