
当谷歌将 AI 概述引入近一半的搜索结果时,一个令人不安的问题摆在了每个 SEO 团队的桌面上:如果答案就在页面上,为什么还要点击查看呢?诚实的回答是,大多数用户不会点击。当人工智能概述触发时,有机点击率最多会下降 61%。但是,在人工智能生成的概述中被引用的品牌比没有被引用的品牌获得的有机点击率高出 35%。
被总结和被引用之间的差距现在决定了搜索流量的去向。为了了解如何站在正确的一边,我们回顾了近期人工智能概述研究中记录的模式,并比较了哪些来源被引用,哪些被忽略。这些发现与关于如何在 AI 综述 SEO 游戏手册中出现的几个常见假设不谋而合。
人工智能概述的来源(不仅仅是排名第一)
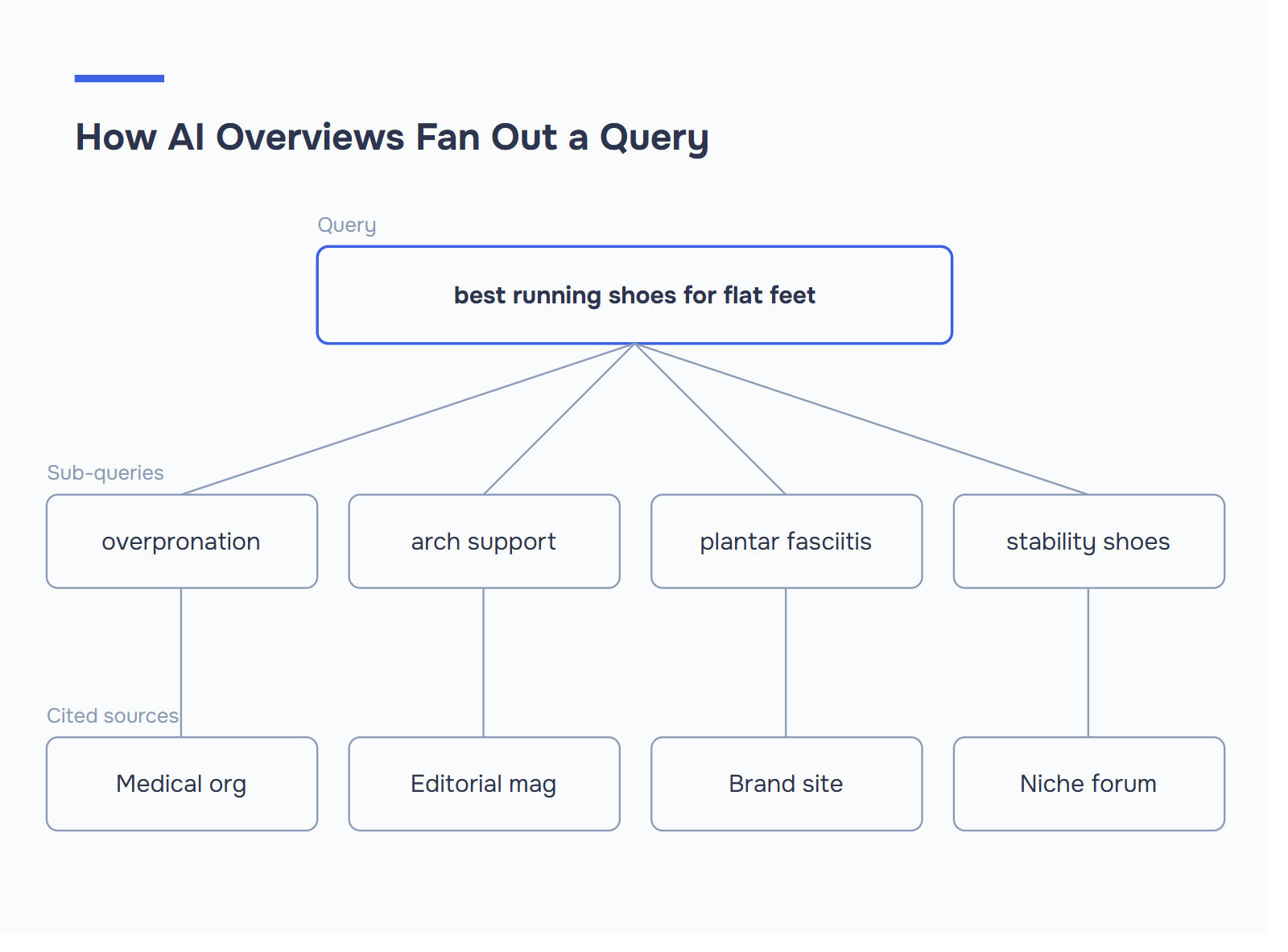
人工智能概述不会简单地摘取最重要的有机结果。它们会将一个查询分解成多个子问题,分别搜索每个子问题,然后从最能回答每个片段的来源中收集引文-谷歌将这一过程称为 "查询扇出"(query fan-out)。
排在第一位的链接出现在人工智能概述中的几率约为 53%,而排在第 10 位的链接出现在人工智能概述中的几率则下降到约 37%。更引人注目的是:超过 99% 的 AI 概述引用来自排名前 10 位的有机结果页面,引用重叠率约为 94%。因此,传统的 SEO 仍然是底线。只是不再是天花板。
在我们审查的所有模式中,有三件事一直在重复:
- 被引用的页面并不总是排名最高的。 排在第 3-8 位的网页,如果结构比排名第一的结果更简洁,就会被拉入概览。人工智能优先考虑的是最清晰的段落,而不是最强的领域。
- 在重点查询中,小网站胜过大网站。 小品牌与大公司同时出现,而且在许多情况下,所选来源并非排名最高的网页。
- 子查询可解锁利基引用。 关于 "人工智能概述排名 "的广泛查询可能会引用一个算法来源、另一个模式来源和第三个跟踪来源。这就是查询的扇出效应。
实际启示:停止将页面优化为单一答案。优化章节-H2 级别的段落,每个段落完全解决一个小问题。
扇出诊断 选择目标关键词,并写下 3-5 个可以分解成的子查询。比如 "最适合扁平足的跑步鞋":过度内旋鞋、足弓支撑运动鞋、足底筋膜炎跑步装备、稳定鞋与中性鞋。现在扫描一下你自己的页面。它是否在自成一体的段落中回答了每个子查询,并有明确的 H2 或 H3?如果五个子查询中缺少两个,或者被埋没在一个 400 字的段落中,这就是你的竞争对手被引用而你没有被引用的地方。
内容格式要求:结构是新的权威
在人工智能提取方面,清晰的结构胜过散文的密度。 人工智能能否引用您的内容,最大的决定因素是它是否能提取出没有歧义的简洁答案块。
引文来源主要有三种结构模式:
- 自带答案段落。 对数以千计的人工智能概述引文进行的研究分析表明,人工智能会优先考虑那些以大约 130-170 个字的独立单元充分回答查询的段落。需要三段以上上下文的段落会输给独立的段落。
- 分层 H2/H3 架构。 引用页面绝大多数使用问题式 H2("X 是什么?"、"Y 如何工作?"),然后在前 1-2 句中直接给出答案。这种模式非常一致,几乎是模板化的。
- 列表、表格和步骤模块。 密集的段落和缺失的标题使人工智能难以提取内容。清晰的分层标题、简短的段落、项目符号列表和表格可以提高可扫描性-对于人类和提取模型来说都是如此。
以下是数据显示的 "排名 "和 "引用 "之间的区别:
| 要素 | 已排名但未引用 | 在《人工智能概述》中排名并被引用 |
|---|---|---|
| H2 下的开头句 | 设置上下文 | 直接回答标题问题 |
| 段落长度 | 150-300+ 字 | 40-80 个单词,每个单词一个想法 |
| 列表和表格 | 稀有或装饰性 | 用于构建比较和步骤 |
| 标题 | 通用("概述"、"好处) | 问题式("X 如何工作?) |
| 内部参考资料 | "如上所述……" | 每个部分都是独立的 |
| 多模式元素 | 仅限文本 | 文本 + 图像 + 结构化数据 |

在多项人工智能概述研究中,结合了文本、图片、视频和结构化数据的页面显示出更高的选择概率。多模态内容不是装饰,而是引用信号。
帮助您的 Schema 标记:常见问题页面、操作方法、文章
Schema 标记不再是一个 "好东西"。它是告诉人工智能系统你的内容到底是什么的一层。 三种模式类型为人工智能概述资格做了大量工作。

常见问题页面模式
它的工作原理:它将内容预先格式化为问题-答案对,这正是人工智能系统提取和呈现信息的方式。当您实施 FAQPage 模式时,您就明确地告诉了人工智能平台问题是什么、权威答案是什么以及这些元素之间的关系。这就消除了解释的负担。
实施建议:将答案字数控制在 40-60 字之间,以获得最佳提取效果。独立研究表明,FAQPage 对人工智能引用率的平均提升率约为 30%。
一个最小的区块是这样的
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "How do I get cited in Google AI Overviews?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Rank in the top 10 for the target query, use question-form H2s with direct-answer first sentences, and add FAQPage or HowTo schema that mirrors the visible content."
}
}]
}
将其作为<script type="application/ld+json"> 块放到页面的<head> 中,然后在发送前使用 Google 的丰富结果测试进行验证。
HowTo 模式
它的工作原理:它以人工智能可即时解读的顺序映射分步说明。人工智能概述经常引用 3-7 个步骤的程序,因此这种模式类型对技术内容特别有价值。
实施提示:使用编号步骤,而不是埋在地下的段落。反正模式反映的是人工智能将要呈现的内容-让它们匹配。
文章模式(带作者署名)
其工作原理:将内容确定为编辑内容,附加作者实体,并连接到组织。文章模式可识别内容类型;FAQPage 可实现问答提取;HowTo 模式可映射分步说明。它们共同涵盖了人工智能概述将显示的大部分内容。
实施提示:始终包括author,datePublished,dateModified, 和publisher 。不包含这些内容的页面会被系统地取消优先级。
这三种模式类型加在一起,就是被引用与不被引用的区别。需要注意的是:模式只有在与页面实际内容相匹配时才能发挥作用。对用户不可见的常见问题进行标记会让你受到惩罚,而不是提升。
技术因素:页面速度、HTTPS、移动和可抓取性
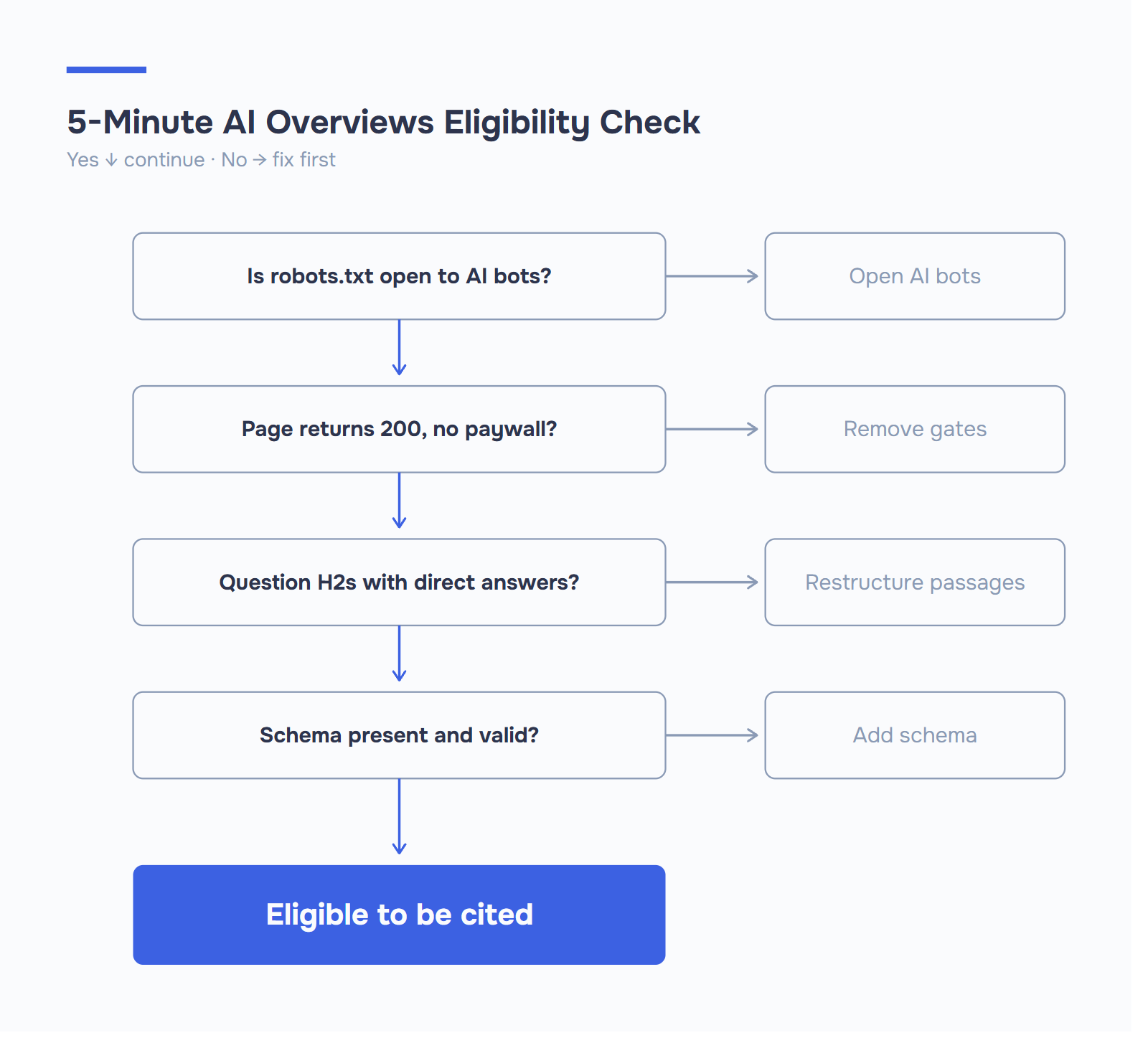
在任何信号发挥作用之前,人工智能爬虫都必须到达您的页面。 这听起来很明显。但也正是在这一点上,许多网站悄无声息地失去了资格。
如果机器人无法获取您的 URL,那么本列表中的其他内容都无济于事。网页需要返回简洁的 200 状态代码,在没有验证墙的情况下加载,并在训练抓取和实时接地时保持可访问性。
不容讨价还价的技术基准:
- HTTPS 无处不在。 在每个人工智能表面,非安全页面都会被系统地取消优先级。
- 移动优先渲染 谷歌会索引移动版本。如果您的移动版面设计将表格折叠或将常见问题隐藏在 "点击展开 "后面,人工智能就会看到折叠的版本。
- Core Web Vitals 处于绿色状态。 LCP 小于 2.5 秒,INP 小于 200 毫秒,CLS 小于 0.1。速度慢的页面被抓取的频率较低,重新定位的频率也较低,而在人工智能概述上,新鲜度非常重要,抓取频率低意味着引用陈旧。
- 关键内容采用服务器渲染的 HTML。 如果您的答案段落只是在 JavaScript 水化后才出现,那么就假设有些爬虫不会看到它们。
- 开放爬虫访问。 这是大多数网站都会出错的地方。
2026 年,"可访问 "意味着十几种不同的用户代理都可以访问。现在,明确欢迎人工智能机器人的简洁robots.txt 已成为基准线。下面是一个允许人工智能搜索引用而不允许模型训练的配置:
# Allow AI search crawlers
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: ClaudeBot
Allow: /
# Disallow training-only crawlers (optional, based on policy)
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
Perplexity尊重robots.txt指令,PerplexityBot不会索引任何禁止它的网站。因此,如果PerplexityBot被阻止了-不管是意外还是其他原因-Perplexity的引用将看不到您。
应避免什么?内容贫乏、付费墙、信息冲突
人工智能概述会主动过滤掉不完整、不一致或不可访问的内容。 一些模式的页面会被静默排除:
- 内容单薄。 只重述问题而不回答问题的页面,或者在进入实质内容之前先填充附属内容的页面,几乎不会出现在引用来源中。一篇 600 字的文章,如果花了 400 字在 "什么是 X "的框架上,然后才给出真正的答案,那么它就输给了一篇 600 字的文章,而后者在第一段就给出了答案。
- 付费墙和登录闸门 如果人工智能爬虫遇到验证墙,页面将被视为无法访问。软付费墙(预览+CTA)没有问题;硬付费墙会取消您的资格。
- 整个网站的信息相互矛盾。 你的主页上写着 "成立于 2018 年",博文上写着 "我们自 2017 年起开始运营","关于我们 "页面上写着 "已有五年多的历史"。人工智能会对这三者进行优先排序。在日期、声明和产品描述中,实体的一致性比人们意识到的更重要。
- 内容陈旧。 每季度不更新的页面失去引用的可能性大约是原来的 3 倍。人工智能概述偏爱新鲜信号。
- 缺少 E-E-A-T 信号。 谷歌的 E-E-A-T 框架实际上已成为一种排名过滤器,而不仅仅是一种质量指南。在人工智能生成的结果中,E-E-A-T 指标高的网页能见度明显更高。
- 作者模糊不清。 没有作者署名、没有简介、没有作者实体链接的页面看起来像是由任何人生成的,讽刺的是,其中也包括人工智能。
- 模式不对齐。 标记页面上不存在的内容比没有模式更糟糕。最常见的版本是FAQ页面模式中的问题和答案实际上在页面的任何地方都看不到。丰富结果测试会将其标记,不久之后引用就会枯竭。
所有这些的模式:人工智能概述只引用他们可以验证的内容。任何含糊不清的内容都会被视为风险信号。
监控:如何跟踪人工智能概述中的外观
无法衡量就无法优化,而人工智能概述跟踪比传统的排名跟踪更难。 这些数据分散在 Google Search Console、第三方工具和人工检查中。以下是真实情况。
谷歌搜索控制台
GSC 增加了部分可见性,但有注意事项。更新后的 "搜索外观 "过滤器现在包含了人工智能概览和人工智能模式查询的专用分段,让您可以专门查看这些人工智能生成格式的印象、点击和点击率,而不是将它们折叠到网页搜索数据汇总中。
要找到它性能→搜索结果→搜索外观过滤器→"AI概览"。这将为您提供印象、点击、点击率和平均位置,并将您出现在 AI 概述中的查询与其他网络搜索数据分开。
看什么?
- 印象与点击比率 与传统列表相比,出现在 AI 概述中会产生大量的印象数,但点击率却明显较低。印象量突然激增而点击量却平平,通常意味着人工智能概述正在拦截流量。
- 查询级点击率下降。 点击率下降但印象保持不变的查询现在很可能会触发列表上方的人工智能概述。
- 人工智能概述印象上升的页面。 这些是您的引文候选者。审核它们的结构、模式和新鲜度-这正是小修小补的最大优势所在。
第三方工具
对于引用级别的跟踪("我是否被引用?"的二进制),GSC 是不够的。Semrush、Ahrefs和SISTRIX都具有跟踪AI概述何时何地出现在特定关键词上的功能。将其与 GSC 数据相互参照是估算影响的最佳免费方法。
专门的人工智能可见性平台(Otterly、OmniSEO、Wellows 等)则更进一步,它们直接对人工智能引擎进行投票,并记录您的域名是否在 Google AI Overviews、Perplexity、ChatGPT Search 和 Gemini 上显示。
人工抽查
扩展性最小的方法,也是最可靠的方法。挑选 20-30 个目标查询。在 Google AI Overviews、Perplexity、ChatGPT Search 和 Gemini 中运行它们。记录:
- 您的域名被引用了吗?
- 具体是哪个 URL?
- 在引文列表中处于什么位置?
- 哪些竞争对手的引文与您的引文并列?
在了解实际引用模式方面,包含这些列和日期的简单 Google Sheet(每月更新)比大多数付费工具更胜一筹。您要找的不是某个糟糕的星期;您要找的是您系统性地错过了哪些查询,哪些竞争对手一直在抢占您的位置。
有用的关键绩效指标框架
跟踪这四个指标:
- 出现率-在您跟踪的查询中,您作为引用出现的百分比
- 引用位置-你在引用列表中的位置(第一个来源的权重最大)
- 触发率- 完全触发人工智能概述的跟踪查询百分比
- 竞争对手重叠-哪些域名与您同时被引用,哪些域名取代了您的位置
检查您是否真正符合资格
大多数如何在 AI 概述中显示出来的 SEO 建议都侧重于内容和结构方面的工作,这些工作会在数月内不断累积。而基础问题-机器人能否首先访问您的网页?- 这个基础性问题受到的关注要少得多。而这个问题只需五分钟就能回答。
如果您的robots.txt 中屏蔽了 PerplexityBot、OAI-SearchBot 或 Google-Extended,那么本指南中的所有其他优化都将失去意义。您的内容不会被索引,不会被引用,而且对于已经占据了近一半搜索份额的渠道来说,您的内容是不可见的。
对您的域名进行爬虫访问检查。 ICODA 的人工智能可见性工具可测试主要的人工智能搜索机器人是否能够实际访问您的页面-PerplexityBot、OAI-SearchBot、GPTBot、Google-Extended、ClaudeBot-并标记每个机器人用于决定是否引用您的内容的模式和技术信号。我们审核过的大多数网站都发现至少有一个他们不知道的意外阻塞。
2026年赢得人工智能概述引用的品牌并不是那些拥有最大域名的品牌。他们的网页干净整洁、结构合理、可抓取且值得信赖-不仅是页面,还有段落层面。这项工作是可行的。问题在于您是现在就开始,还是在 CTR 遭到另一个季度的侵蚀后再开始。
常见问题(FAQ)
您需要排名在前 10 位,但不一定是第一位。排在第 3-8 位的网页,如果其结构比排名靠前的网页更清晰,就会经常被拉入人工智能概述。人工智能会选择最清晰的可提取段落,而不是最强的域名权威。排在第 1 位的网页被引用的几率大约为 53%;排在第 10 位的网页被引用的几率大约为 37%。这种差距是真实存在的,但并非不可逾越。
是的,这是小型网站在结构上具有优势的少数几个地方之一。人工智能概述通过 "查询扇出 "将查询分解为子问题,然后为每个片段提取最清晰的答案-无论领域大小。一个重点突出的 600 字页面,如果能在简洁的 H2 区块中完整回答一个狭窄的子问题,就能击败将同样的答案埋没在第七段中的臃肿企业页面。
FAQPage 模式具有显著的提升效果-独立研究表明,它能提高 30% 左右的引用率。它之所以有效,是因为它将内容预先格式化为问答对,而这正是人工智能系统提取和呈现信息的方式。尽管如此,模式只有在反映页面上实际可见内容的情况下才能发挥作用。标注HTML中不存在的常见问题会使您受到惩罚,而不是提升。
阻止PerplexityBot可以让你在Perplexity引用中完全隐身-它严格遵守robots.txt 指令。具体到谷歌人工智能概述,您需要检查是否允许使用Google-Extended 和Googlebot 。这些都是具有不同规则的独立机器人,在人工智能爬虫出现之前的旧版robots.txt 配置中经常会发现意外阻止。在做其他任何事情之前,请先进行爬虫访问审核,如果机器人无法访问您的网页,其他任何优化都将失去意义。
几乎肯定是。当人工智能概述触发您排名的查询时,GSC 会计算两次印象,但只有一次点击机会,而大多数用户都不会点击。其特征是:展示量激增,点击量持平或下降,点击率下降,平均位置保持或提高。检查 GSC 中的 "搜索外观 "过滤器,并通过 "人工智能概述 "进行过滤,以确认哪些查询对您造成了这种影响。
分享


给文章评分












