Lorsque Google a déployé des aperçus AI SEO dans près de la moitié des résultats de recherche, une question inconfortable a atterri sur le bureau de toutes les équipes SEO : si la réponse est sur la page, pourquoi cliquer ? La réponse honnête est que la plupart des utilisateurs ne le font pas. Les taux de clics organiques chutent jusqu’à 61 % lorsqu’un aperçu de l’IA se déclenche. Mais les marques qui sont citées dans ces résumés générés par l’IA obtiennent 35 % de clics organiques de plus que celles qui ne le sont pas.
C’est cet écart - entre le fait d’être résumé et celui d’être cité - qui détermine aujourd’hui la destination du trafic de recherche. Pour comprendre comment se placer du bon côté, nous avons examiné les modèles documentés dans les études récentes sur les synthèses d’IA et comparé les sources qui ont été citées et celles qui n’ont pas été prises en compte. Les résultats vont à l’encontre de plusieurs hypothèses courantes sur la façon d’apparaître dans les manuels de SEO des synthèses d’IA.
D’où proviennent les aperçus d’IA (il ne s’agit pas seulement du premier rang)
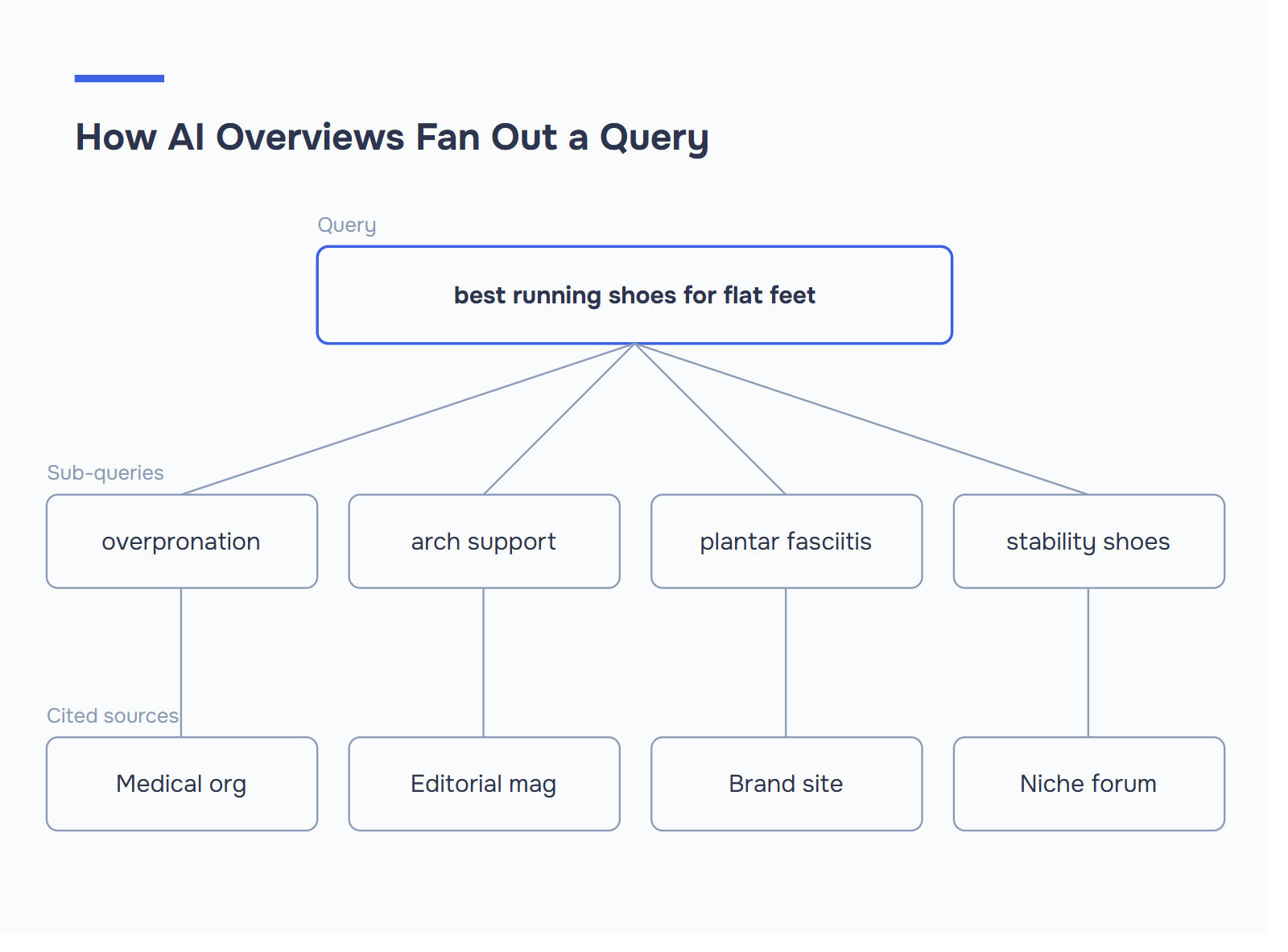
Les aperçus d’IA ne se contentent pas d’extraire le premier résultat organique. Ils décomposent une requête en sous-questions, effectuent des recherches sur chacune d’entre elles séparément, puis rassemblent les citations de sources qui répondent le mieux à chaque fragment - un processus que Google appelle " query fan-out".
Les liens en première position ont environ 53 % de chances d’apparaître dans les aperçus AI, tandis que ceux en 10e position tombent à environ 37 %. Plus frappant encore : plus de 99 % des citations dans les aperçus AI proviennent de pages classées dans les 10 premiers résultats organiques, avec un chevauchement des citations de l’ordre de 94 %. Le SEO traditionnel reste donc le plancher. Il n’est tout simplement plus le plafond.
Dans les modèles que nous avons examinés, trois éléments se répètent :
- La page citée n’était pas toujours la mieux classée. Les pages des positions 3 à 8 ont été placées dans des aperçus lorsque leur structure était plus claire que celle du résultat n° 1. L’IA donne la priorité au passage le plus clair, et non au domaine le plus fort.
- Les petits sites battent les grands sur les requêtes ciblées. Les petites marques apparaissent aux côtés des grandes entreprises et, dans de nombreux cas, la source sélectionnée n’est pas la page la mieux classée.
- Les sous-requêtes permettent de débloquer des citations de niche. Une requête générale sur le "classement des aperçus de l’IA" peut citer une source pour l’algorithme, une autre pour le schéma et une troisième pour le suivi. C’est ce que l’on appelle l’éventail de requêtes en action.
En pratique, il faut cesser d’optimiser les pages en tant que réponses monolithiques. Optimisez les sections - des passages de niveau H2 qui résolvent entièrement une sous-question chacun.
Le diagnostic du fan-out. Choisissez votre mot-clé cible et écrivez 3 à 5 sous-requêtes en lesquelles il pourrait se décomposer de manière plausible. Pour "meilleures chaussures de course pour pieds plats" : chaussures de surpronation, chaussures de soutien de la voûte plantaire, chaussures de course pour la fasciite plantaire, chaussures de stabilité et chaussures neutres. Analysez maintenant votre propre page. Répond-elle à chaque sous-question dans un passage autonome avec un H2 ou un H3 clair ? Si deux des cinq questions sont absentes - ou enfouies dans un bloc de 400 mots - c’est là que votre concurrent est cité et que vous ne l’êtes pas.
Exigences en matière de format de contenu : La structure est la nouvelle autorité
La structure claire l’emporte sur la densité de la prose pour l’extraction de l’IA. L’élément le plus déterminant pour qu’une IA puisse citer votre contenu est qu’elle puisse extraire un bloc de réponse propre et sans ambiguïté.
Trois modèles structurels dominent les sources citées :
- Passages de réponses autonomes. Des recherches analysant des milliers de citations de l’aperçu de l’IA suggèrent que l’IA donne la priorité aux passages qui répondent entièrement aux requêtes dans des unités autonomes d’environ 130 à 170 mots. Un passage qui a besoin d’un contexte à partir de trois paragraphes sera préféré à un paragraphe qui se suffit à lui-même.
- Architecture hiérarchique H2/H3. Les pages citées utilisent très majoritairement des H2 de type interrogatif ("Qu’est-ce que X ?", "Comment fonctionne Y ?") suivies d’une réponse directe dans les 1 ou 2 premières phrases. Ce schéma est tellement cohérent qu’il en devient presque un modèle.
- Listes, tableaux et blocs d’étapes. Les paragraphes denses et les titres manquants rendent le contenu difficile à extraire pour l’intelligence artificielle. Des titres hiérarchiques clairs, des paragraphes courts, des listes à puces et des tableaux améliorent la lisibilité, tant pour les humains que pour les modèles d’extraction.
Voici ce que les données suggèrent comme étant la différence entre "classé" et "cité" :
| Élément | Classé mais non cité | Classée ET citée dans les synthèses sur l’IA |
|---|---|---|
| Phrase introductive sous H2 | Mise en place du contexte | Répond directement à la question du titre |
| Longueur du paragraphe | 150-300+ mots | 40-80 mots, une idée chacun |
| Listes et tableaux | Rare ou décoratif | Utilisé pour structurer les comparaisons et les étapes |
| Rubriques | Générique ("Vue d’ensemble", "Avantages") | Forme interrogative ("Comment fonctionne X ?") |
| Références internes | "Comme nous l’avons dit plus haut…" | Chaque section est indépendante |
| Éléments multimodaux | Texte uniquement | Texte + image + données structurées |

Les pages qui combinent du texte, des images, des vidéos et des données structurées présentent une probabilité de sélection significativement plus élevée dans plusieurs études d’aperçu de l’IA. Le contenu multimodal n’est pas une décoration - c’est un signal de citation.
Le balisage Schema qui aide : FAQPage, HowTo, Article
Le balisage Schema n’est plus une "bonne chose à faire". C’est la couche qui indique aux systèmes d’intelligence artificielle ce qu’est réellement votre contenu. Trois types de schémas font le gros du travail pour l’éligibilité de l’aperçu AI.

Schéma de la page FAQ
Pourquoi il fonctionne : il préformate votre contenu sous forme de paires question-réponse - exactement comme les systèmes d’intelligence artificielle extraient et présentent les informations. Lorsque vous mettez en œuvre le schéma FAQPage, vous indiquez explicitement aux plateformes d’IA quelle est la question, quelle est la réponse qui fait autorité et comment les éléments sont liés. Cela supprime le fardeau de l’interprétation.
Conseil de mise en œuvre : gardez les réponses entre 40 et 60 mots pour une extraction optimale. Selon des études indépendantes, l’impact moyen de FAQPage sur les taux de citation de l’IA est de l’ordre de 30 %.
Un bloc minimal se présente comme suit :
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "How do I get cited in Google AI Overviews?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Rank in the top 10 for the target query, use question-form H2s with direct-answer first sentences, and add FAQPage or HowTo schema that mirrors the visible content."
}
}]
}
Placez-la dans votre page <head> sous la forme d’un bloc <script type="application/ld+json">, puis validez-la à l’aide du test des résultats riches de Google avant de l’envoyer.
Schéma HowTo
Pourquoi il fonctionne : il présente les instructions étape par étape dans une séquence que l’intelligence artificielle peut interpréter instantanément. Les aperçus de l’IA citent souvent des procédures en 3 à 7 étapes, ce qui rend ce type de schéma particulièrement utile pour les contenus techniques.
Conseil de mise en œuvre : utilisez des étapes numérotées, et non des paragraphes enterrés. Le schéma reflète ce que l’IA va rendre de toute façon - faites en sorte qu’ils correspondent.
Schéma de l’article (avec attribution de l’auteur)
Pourquoi cela fonctionne : cela permet d’établir que le contenu est éditorial, d’y associer une entité auteur et de le relier à une organisation. Le schéma Article identifie le type de contenu ; le schéma FAQPage permet d’extraire les questions et réponses ; le schéma HowTo cartographie les instructions étape par étape. Ensemble, ils couvrent la majeure partie de ce qu’une vue d’ensemble de l’IA peut mettre en évidence.
Conseil de mise en œuvre : incluez toujours author, datePublished, dateModified, et publisher. Les pages qui n’en contiennent pas sont systématiquement dépriorisées.
Ensemble, ces trois types de schéma font la différence entre être cité et être invisible. Une mise en garde s’impose : le schéma ne fonctionne que s’il correspond à ce qui se trouve réellement sur la page. Marquer des FAQ qui ne sont pas visibles par les utilisateurs vous pénalise, pas vous favorise.
Facteurs techniques : Vitesse de la page, HTTPS, Mobile et Crawlabilité
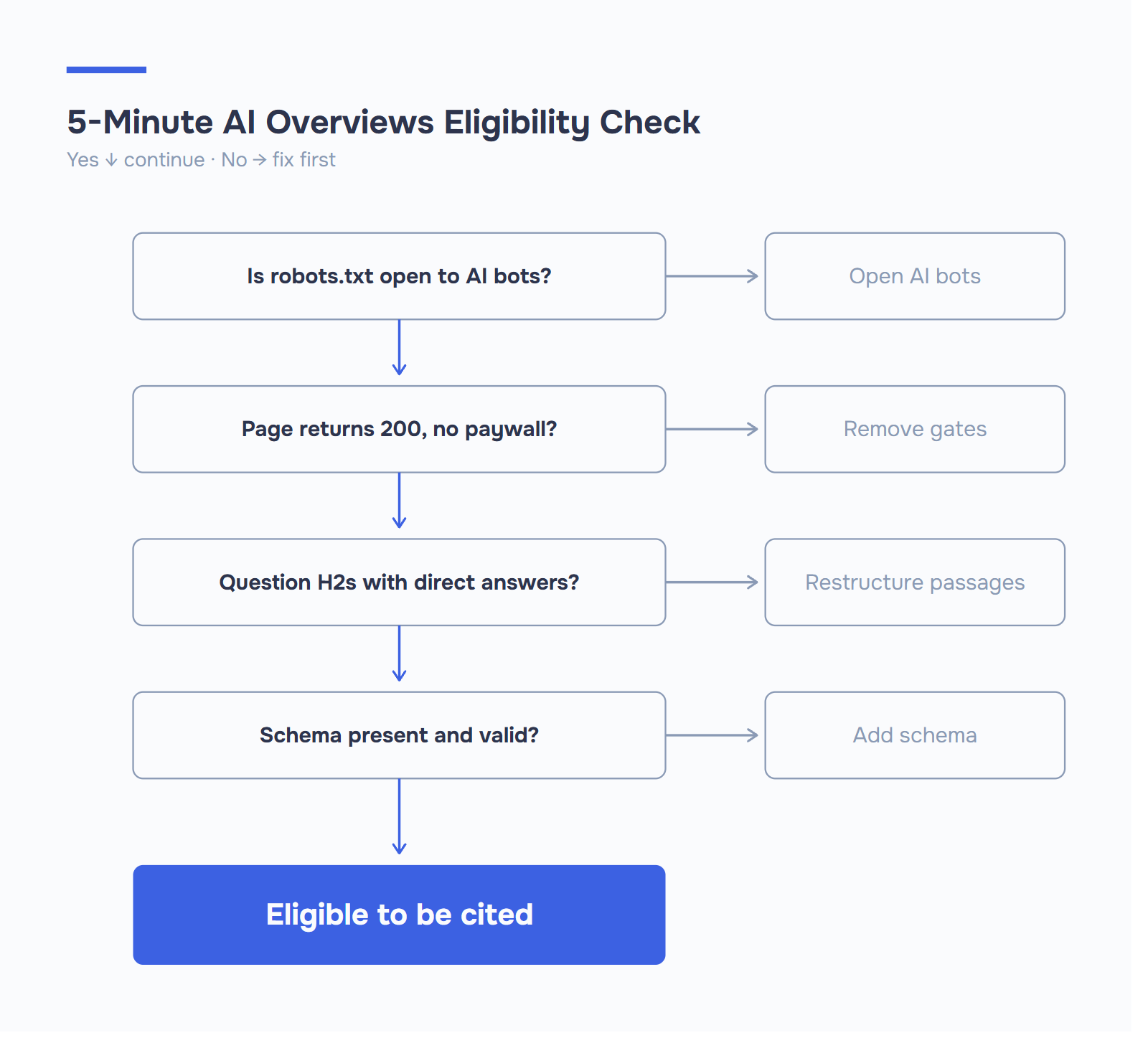
Avant qu’un signal n’entre en ligne de compte, un robot d’indexation de l’IA doit atteindre votre page. Cela semble évident. C’est aussi là qu’un nombre surprenant de sites se disqualifient discrètement.
Si un robot ne peut pas récupérer votre URL, rien d’autre dans cette liste n’est utile. Les pages doivent renvoyer un code de statut 200 propre, se charger sans murs d’authentification et rester accessibles lors des crawls d’entraînement et des mises à la terre en temps réel.
La base technique non négociable :
- HTTPS partout. Les pages non sécurisées sont systématiquement dépriorisées sur toutes les surfaces d’IA.
- Rendu mobile d’abord. Google indexe la version mobile. Si votre mise en page mobile réduit vos tableaux ou cache vos FAQ derrière un "tap-to-expand", l’IA voit la version réduite.
- L’indice de référence de l’internet est dans le vert. LCP inférieur à 2,5 secondes, INP inférieur à 200 ms, CLS inférieur à 0,1. Les pages lentes sont explorées moins fréquemment et remises à jour moins souvent - et sur les aperçus d’IA, où la fraîcheur est importante, une exploration moins fréquente signifie des citations périmées.
- HTML rendu serveur pour les contenus critiques. Si vos paragraphes de réponse n’apparaissent qu’après l’hydratation du JavaScript, supposez que certains robots d’indexation ne les verront pas.
- Accès ouvert au crawler. C’est le point sur lequel la plupart des sites se trompent.
En 2026, "accessible" signifie accessible à une douzaine d’agents utilisateurs différents. Un site robots.txt propre qui accueille explicitement les robots d’intelligence artificielle constitue désormais une référence. Voici une configuration qui autorise les citations de recherche d’IA sans permettre l’entraînement de modèles :
# Allow AI search crawlers
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: ClaudeBot
Allow: /
# Disallow training-only crawlers (optional, based on policy)
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
Perplexity respecte les directives robots.txt, et PerplexityBot n’indexera aucun site qui l’interdit. Donc si PerplexityBot est bloqué - accidentellement ou autrement - vous êtes invisible aux citations de Perplexity.
Ce qu’il faut éviter : Contenu superficiel, murs payants, informations contradictoires
Les aperçus d’IA filtrent de manière agressive les contenus dont on ne peut pas garantir l’exhaustivité, la cohérence ou l’accessibilité. Quelques modèles obtiennent des pages exclues silencieusement :
- Contenu superficiel. Les pages qui ne font que répéter la question sans y répondre, ou qui se contentent d’ajouter des informations sur les affiliés avant d’aborder le fond, n’apparaissent presque jamais dans les sources citées. Un article de 600 mots qui consacre 400 mots à la question "qu’est-ce que X" avant d’arriver à la réponse proprement dite est perdant par rapport à un article de 600 mots qui répond dans le premier paragraphe.
- Parois payantes et barrières de connexion. Si le robot d’indexation de l’IA rencontre un mur d’authentification, la page est considérée comme inaccessible. Les paywalls souples (aperçu + CTA) sont acceptables ; les paywalls durs vous disqualifient.
- Informations contradictoires sur l’ensemble du site. Votre page d’accueil dit "fondé en 2018″, un article de blog dit "nous existons depuis 2017″, la page "À propos" dit "plus de cinq ans". L’IA donne la priorité aux trois. La cohérence des entités - entre les dates, les déclarations et les descriptions de produits - est plus importante qu’on ne le pense.
- Contenu périmé. Les pages qui ne sont pas mises à jour trimestriellement sont environ 3 fois plus susceptibles de perdre des citations. Les aperçus d’IA favorisent les signaux frais.
- Signaux E-E-A-T manquants. Le cadre E-E-A-T de Google est effectivement devenu un filtre de classement, et non plus seulement une ligne directrice en matière de qualité. Les pages présentant de solides indicateurs E-E-A-T sont nettement plus visibles dans les résultats générés par l’IA.
- Auteur vague. Les pages sans signature, sans biographie et sans lien vers une entité auteur semblent pouvoir être générées par n’importe qui, y compris, ironiquement, par l’intelligence artificielle.
- Schéma mal aligné. Marquer un contenu qui n’existe pas sur la page est pire que de ne pas avoir de schéma du tout. La version la plus courante : Un schéma de page FAQ avec des questions et des réponses qui ne sont pas réellement visibles par le lecteur, où que ce soit sur la page. Le test des résultats riches le signale, et les citations se tarissent peu après.
La tendance qui se dégage de tous ces exemples est la suivante : Les aperçus de l’IA ne citent que ce qu’ils peuvent vérifier. Tout ce qui crée une ambiguïté est traité comme un signal de risque.
Suivi : Comment suivre les apparitions dans les aperçus d’IA
Vous ne pouvez pas optimiser ce que vous ne pouvez pas mesurer - et le suivi de l’aperçu de l’IA est plus difficile que le suivi traditionnel du classement. Les données sont fragmentées entre Google Search Console, des outils tiers et des vérifications manuelles. Voici l’état des lieux.
Google Search Console
Le CGC a ajouté une visibilité partielle, mais avec des mises en garde. Le filtre Search Appearance mis à jour comprend désormais des segments dédiés aux aperçus AI et aux requêtes AI Mode, ce qui vous permet de voir les impressions, les clics et le CTR provenant spécifiquement de ces formats générés par l’IA, plutôt que de les voir intégrés dans les données agrégées de la recherche sur le web.
Pour le trouver : Performances → Résultats de recherche → Filtre d’apparence de recherche → "Aperçu AI". Vous obtiendrez ainsi les impressions, les clics, le CTR et la position moyenne pour les requêtes dans lesquelles vous êtes apparu dans un aperçu AI, séparé du reste de vos données de recherche sur le web.
Ce qu’il faut regarder :
- Ratio impressions/clics. L’apparition dans un aperçu AI génère un grand nombre d’impressions, mais un CTR nettement inférieur à celui des listes traditionnelles. Une augmentation soudaine du nombre d’impressions accompagnée d’une stagnation des clics signifie généralement qu’un aperçu AI intercepte le trafic.
- Baisse du CTR au niveau des requêtes. Les requêtes pour lesquelles le CTR s’est effondré mais les impressions sont restées stables sont susceptibles de déclencher des aperçus AI au-dessus de votre liste.
- Pages dont le nombre d’impressions de l’aperçu AI est en hausse. Ce sont vos candidats à la citation. Vérifiez leur structure, leur schéma et leur fraîcheur - c’est là que les petites corrections ont le plus d’effet.
Outils tiers
Pour le suivi au niveau de la citation (le binaire "ai-je été cité ou non ?"), GSC n’est pas suffisant. C’est la lacune que les outils d’aperçus AI SEO sont construits pour combler - Semrush, Ahrefs, et SISTRIX ont des fonctionnalités pour suivre quand et où les aperçus AI apparaissent pour des mots clés spécifiques. Le recoupement de ces données avec les données GSC est le meilleur moyen gratuit d’estimer l’impact.
Les plateformes dédiées à la visibilité de l’IA (Otterly, OmniSEO, Wellows et autres) vont plus loin en interrogeant directement les moteurs d’IA et en enregistrant si votre domaine apparaît à travers les aperçus d’IA de Google, Perplexity, ChatGPT Search et Gemini.
Contrôles ponctuels manuels
La méthode la moins évolutive, mais aussi la plus fiable. Choisissez 20 à 30 requêtes cibles. Exécutez-les dans Google AI Overviews, Perplexity, ChatGPT Search et Gemini. Enregistrez :
- Votre domaine a-t-il été cité ?
- Quel URL spécifique ?
- Quelle position dans la liste des citations ?
- Quelles sont les citations de vos concurrents qui figurent à côté de la vôtre ?
Une simple feuille Google avec ces colonnes et la date - mise à jour mensuellement - surpasse la plupart des outils payants pour comprendre vos schémas de citation réels. Vous ne recherchez pas une mauvaise semaine ; vous cherchez à savoir quelles requêtes vous manquez systématiquement et quels concurrents continuent à prendre votre place.
Un cadre utile pour les indicateurs de performance clés
Suivez ces quatre paramètres :
- Taux de présence - % de vos requêtes suivies où vous apparaissez en tant que citation
- Position dans la citation - où vous vous situez dans la liste des citations (la première source a le plus de poids)
- Taux de déclenchement - % de vos requêtes suivies qui déclenchent une vue d’ensemble de l’IA
- Chevauchement des concurrents - quels domaines sont cités à vos côtés et lesquels prennent votre place.
Vérifiez si vous êtes réellement éligible
La plupart des conseils en matière de SEO se concentrent sur le contenu et la structure qui s’accumulent au fil des mois. La question fondamentale - les robots peuvent-ils atteindre vos pages en premier lieu ? - reçoit beaucoup moins d’attention. Pourtant, il est possible d’y répondre en cinq minutes.
Si PerplexityBot, OAI-SearchBot ou Google-Extended sont bloqués sur votre site robots.txt, toutes les autres optimisations présentées dans ce guide sont inutiles. Votre contenu n’est pas indexé, il n’est pas cité et vous êtes invisible pour un canal qui représente déjà près de la moitié des recherches.
Lancez une vérification de l’accès des robots de recherche sur votre domaine. L’outil AI Visibility d’ICODA vérifie si les principaux robots de recherche peuvent effectivement atteindre vos pages - PerplexityBot, OAI-SearchBot, GPTBot, Google-Extended, ClaudeBot - et signale le schéma et les signaux techniques que chaque robot utilise pour décider de vous citer ou non. La plupart des sites que nous avons audités ont trouvé au moins un blocage accidentel dont ils ignoraient l’existence.
Les marques qui obtiendront les citations de l’aperçu AI en 2026 ne sont pas celles qui ont les plus grands domaines. Ce sont celles dont les pages sont propres, structurées, explorables et dignes de confiance - au niveau du passage, et pas seulement au niveau de la page. Le travail est faisable. La question est de savoir si vous commencez maintenant ou après un autre trimestre d’érosion du CTR.
Foire aux questions (FAQ)
Vous devez vous classer dans les 10 premiers, mais pas nécessairement au premier rang. Les pages des positions 3 à 8 sont régulièrement intégrées dans les aperçus de l’IA lorsque leur structure est plus propre que celle des premiers résultats. L’IA choisit le passage extractible le plus clair, et non l’autorité de domaine la plus forte. La position 1 vous donne environ 53 % de chances d’être cité ; la position 10 vous donne environ 37 %. L’écart est réel mais pas insurmontable.
Oui, et c’est l’un des rares domaines où les petits sites ont un avantage structurel. Les aperçus AI décomposent les requêtes en sous-questions par le biais d’un "éventail de requêtes", puis extraient la réponse la plus claire pour chaque fragment, quelle que soit la taille du domaine. Une page ciblée de 600 mots qui répond entièrement à une sous-question étroite dans un bloc H2 propre l’emportera sur une page d’entreprise gonflée qui enfouit la même réponse dans le septième paragraphe.
Le schéma FAQPage a un effet mesurable - des études indépendantes l’évaluent à environ 30 % sur les taux de citation. Il fonctionne parce qu’il préformate votre contenu sous forme de paires question-réponse, ce qui est exactement la façon dont les systèmes d’intelligence artificielle extraient et présentent les informations. Cela dit, le schéma ne fonctionne que s’il reflète ce qui est réellement visible sur la page. Marquer des FAQ qui n’existent pas dans votre HTML vous pénalise, pas vous favorise.
Le blocage de PerplexityBot vous rend complètement invisible dans les citations de Perplexity - il respecte strictement les directives de robots.txt. Pour les aperçus de Google AI en particulier, vous devez vérifier que Google-Extended et Googlebot sont autorisés. Il s’agit de robots distincts avec des règles distinctes, et il est courant de trouver des blocages accidentels provenant d’anciennes configurations de robots.txt antérieures aux crawlers d’IA. Lancez un audit d’accès aux robots avant toute chose - toute autre optimisation est inutile si les robots ne peuvent pas accéder à vos pages.
Il est presque certain que oui. Lorsqu’un aperçu AI se déclenche pour une requête dans laquelle vous êtes classé, GSC compte deux impressions mais une seule opportunité de clic - et la plupart des utilisateurs ne cliquent pas. L’empreinte digitale est la suivante : les impressions augmentent, les clics restent stables ou diminuent, le CTR s’effondre, la position moyenne se maintient ou s’améliore. Vérifiez le filtre Search Appearance dans GSC et filtrez par "AI Overview" pour confirmer quelles requêtes vous font cet effet.
Partager


Notez l'article













