Google이 전체 검색 결과의 절반에 가까운 AI 오버뷰를 도입했을 때, 모든 SEO 팀의 책상 위에는 ‘ 페이지에 답이 있는데 왜 굳이 클릭할까 ‘라는 불편한 질문이 떠올랐습니다. 정직한 대답은 대부분의 사용자가 클릭하지 않는다는 것입니다. AI 개요가 트리거되면 자연 클릭률이 최대 61%까지 떨어집니다. 하지만 AI가 생성한 요약에 인용된 브랜드는 그렇지 않은 브랜드보다 35% 더 많은 유기적 클릭을 얻습니다.
요약되는 것과 인용되는 것 사이의 이 간극이 이제 검색 트래픽이 어디로 향하는지를 결정합니다. 이러한 격차를 줄이는 방법을 이해하기 위해 최근의 AI 개요 연구에서 문서화된 패턴을 검토하고 어떤 출처가 인용되고 어떤 출처가 지나쳐지는지 비교했습니다. 그 결과, AI 개요 SEO 플레이북에 표시되는 방법에 대한 몇 가지 일반적인 가정에 반하는 결과가 나왔습니다.
AI 오버뷰가 뽑은 1위의 비결(단순한 순위가 아닙니다)
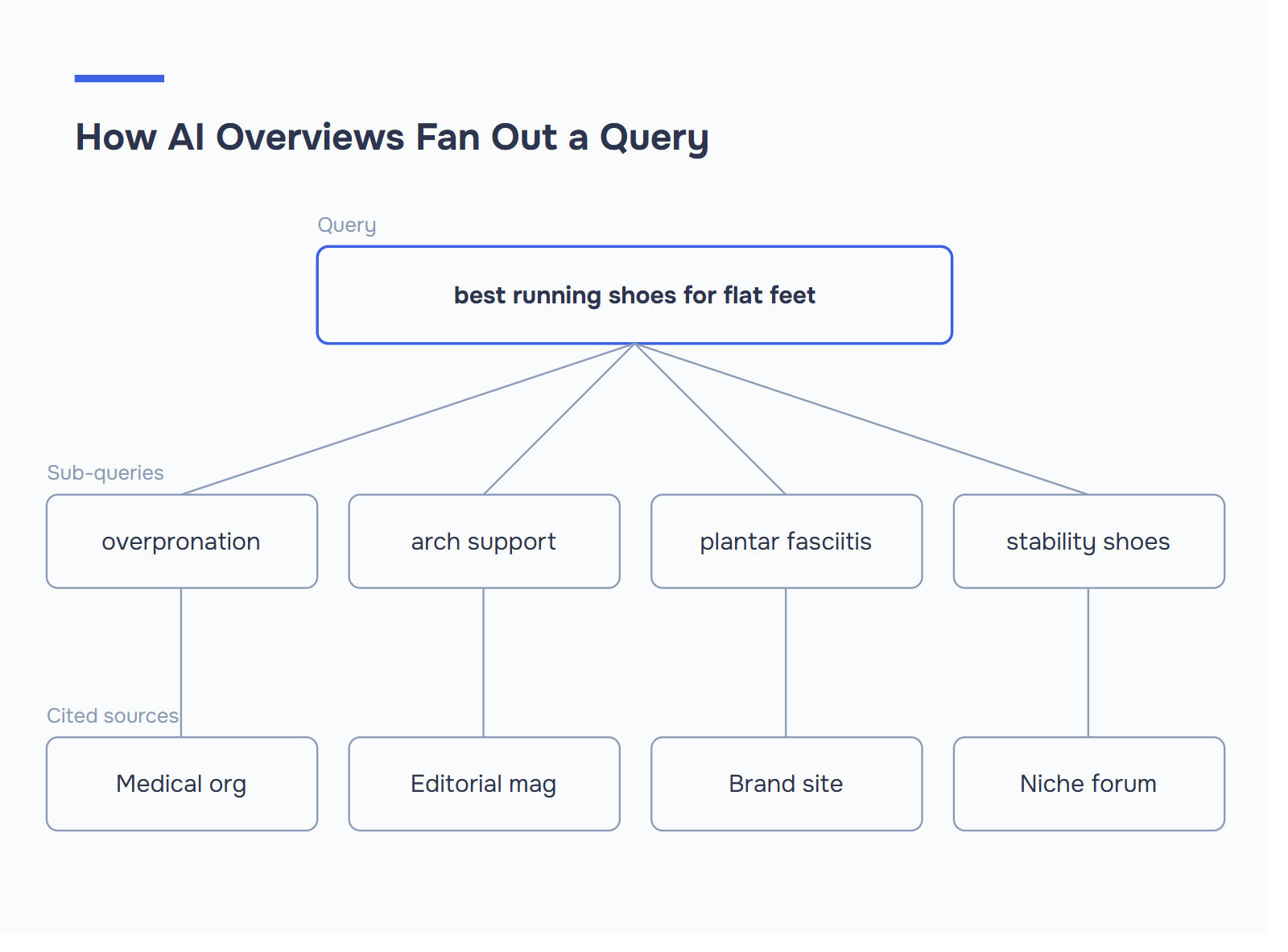
AI 오버뷰는 단순히 상위 오가닉 결과만 골라내는 것이 아닙니다. 검색어를 하위 질문으로 분해하여 각각을 개별적으로 검색한 다음 각 조각에 가장 적합한 답변을 제공하는 출처에서 인용문을 수집하는 프로세스(Google에서는 이를 쿼리 팬아웃이라고 부릅니다)를 수행합니다.
첫 번째 위치에 있는 링크는 AI 개요에 표시될 확률이 약 53%인 반면, 10번째 위치에 있는 링크는 약 37%로 떨어집니다. 더욱 놀라운 점은 99% 이상의 AI 개요 인용이 상위 10위권의 오가닉 결과 페이지에서 발생하며, 약 94%의 인용 중복이 발생한다는 점입니다. 따라서 전통적인 SEO는 여전히 바닥입니다. 더 이상 천장이 아닐 뿐입니다.
저희가 검토한 패턴 전반에서 세 가지가 계속 반복되었습니다:
- 인용된 페이지가 항상 가장 높은 순위에 있는 것은 아닙니다. 3~8위에 있는 페이지는 1위 결과보다 구조가 더 깔끔한 경우 오버뷰에 포함되었습니다. AI는 가장 강력한 도메인이 아니라 가장 깔끔한 구절을 우선시합니다.
- 집중된 쿼리에서 소규모 사이트가 대규모 사이트를 능가합니다. 소규모 브랜드가 대기업과 함께 등장했으며, 선택한 소스가 가장 높은 순위의 페이지가 아닌 경우가 많았습니다.
- 하위 쿼리는 틈새 인용을 잠금 해제합니다. "AI 개요 순위"에 대한 광범위한 쿼리는 알고리즘에 대해서는 한 소스, 스키마에 대해서는 다른 소스, 추적에 대해서는 세 번째 소스를 인용할 수 있습니다. 이것이 바로 쿼리 팬아웃입니다.
실용적인 팁: 페이지를 획일적인 답안으로 최적화하지 마세요. 섹션 최적화 - 각각 하나의 하위 질문을 완전히 해결하는 H2 수준의 구절을 최적화하세요.
팬아웃 진단. 타겟 키워드를 선택하고 이를 그럴듯하게 분해할 수 있는 하위 쿼리 3~5개를 적어보세요. ‘평발에 가장 적합한 러닝화’의 경우: 과내전 신발, 아치 지지 운동화, 족저근막염 러닝화, 안정성 대 중립성 운동화. 이제 자신의 페이지를 스캔해 보세요. 각 하위 질문에 명확한 H2 또는 H3로 독립된 구절로 답변하고 있나요? 5개 중 2개가 누락되었거나 400단어 블록 안에 묻혀 있다면 경쟁업체는 인용되고 귀하는 인용되지 않은 것입니다.
콘텐츠 형식 요구 사항: 구조가 새로운 권한
명확한 구조가 AI 추출을 위한 산문 밀도를 능가합니다. AI가 콘텐츠를 인용할 수 있는지 여부를 결정하는 가장 큰 요소는 모호함 없이 깨끗한 답변 블록을 추출할 수 있는지 여부입니다.
세 가지 구조적 패턴이 인용된 출처를 지배했습니다:
- 자체 포함된 답안 구절. 수천 개의 AI 개요 인용을 분석한 연구에 따르면 AI는 약 130~170단어의 독립된 단위로 질문에 완전히 답변하는 구절에 우선순위를 두는 것으로 나타났습니다. 세 단락 이상의 문맥이 필요한 구절은 단독 문단보다 우선순위에 밀립니다.
- 계층적 H2/H3 아키텍처. 인용된 페이지에서는 "X란 무엇인가요?", "Y는 어떻게 작동하나요?"와 같은 질문형 H2가 압도적으로 많이 사용되었고, 첫 1~2문장에 직접적인 답변이 뒤따랐습니다. 이 패턴은 거의 템플릿에 가까울 정도로 일관성이 있습니다.
- 목록, 표 및 단계 블록. 빽빽한 단락과 누락된 제목은 AI가 콘텐츠를 추출하기 어렵게 만듭니다. 명확한 계층적 제목, 짧은 단락, 글머리 기호 목록 및 표는 사람과 추출 모델 모두의 스캔 가능성을 높여줍니다.
데이터에 따르면 ‘순위’와 ‘인용’의 차이점은 다음과 같습니다:
| 요소 | 순위는 있지만 인용되지 않음 | AI 개요에서 순위 및 인용 |
|---|---|---|
| H2 아래의 첫 문장 | 컨텍스트 설정 | 제목 질문에 직접 답변 |
| 단락 길이 | 150-300단어 이상 | 40~80단어, 아이디어 1개씩 |
| 목록 및 표 | 희귀 또는 장식용 | 비교 및 단계를 구성하는 데 사용 |
| 제목 | 일반("개요", "혜택") | 질문 양식("X는 어떻게 작동하나요?") |
| 내부 참조 | "위에서 언급했듯이…" | 각 섹션은 독립적으로 존재합니다. |
| 멀티모달 요소 | 텍스트만 | 텍스트 + 이미지 + 구조화된 데이터 |

텍스트, 이미지, 동영상, 구조화된 데이터를 결합한 페이지는 여러 AI 개요 연구에서 의미 있게 높은 선택 확률을 보였습니다. 멀티모달 콘텐츠는 장식이 아니라 인용 신호입니다.
도움이 되는 스키마 마크업 FAQ페이지, 사용법, 문서
스키마 마크업은 더 이상 "있으면 좋은 것"이 아닙니다. 스키마 마크업은 AI 시스템에 콘텐츠가 실제로 무엇인지 알려주는 계층입니다. 세 가지 스키마 유형이 AI 개요 자격을 위한 무거운 작업을 수행합니다.

FAQ페이지 스키마
작동 이유: 콘텐츠를 질문과 답변 쌍으로 미리 포맷하여 AI 시스템이 정보를 추출하고 제시하는 방식과 정확히 일치합니다. FAQPage 스키마를 구현하면 질문이 무엇인지, 권위 있는 답변이 무엇인지, 요소들이 어떻게 연관되어 있는지를 AI 플랫폼에 명시적으로 알려주게 됩니다. 따라서 해석에 대한 부담이 줄어듭니다.
구현 팁: 최적의 추출을 위해 답변을 40~60단어 사이로 유지하세요. 독립적인 연구에 따르면 FAQPage의 평균 AI 인용률은 약 30%에 달합니다.
최소 블록은 다음과 같습니다:
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "How do I get cited in Google AI Overviews?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Rank in the top 10 for the target query, use question-form H2s with direct-answer first sentences, and add FAQPage or HowTo schema that mirrors the visible content."
}
}]
}
페이지의 <head> 에 <script type="application/ld+json"> 블록으로 드롭한 다음 Google의 리치 결과 테스트를 통해 유효성을 검사한 후 배송하세요.
스키마 사용법
작동 이유: 단계별 지침을 AI가 즉시 해석할 수 있는 순서로 매핑합니다. AI 개요에는 3~7단계 절차가 자주 인용되므로 이 스키마 유형은 기술 콘텐츠에 특히 유용합니다.
구현 팁: 묻혀 있는 단락이 아닌 번호가 매겨진 단계를 사용하세요. 스키마는 어쨌든 AI가 렌더링할 내용을 반영하여 일치하도록 합니다.
문서 스키마(저작자 속성 포함)
작동 이유: 콘텐츠를 에디토리얼로 설정하고, 작성자 엔터티를 첨부하고, 조직에 연결합니다. 문서 스키마는 콘텐츠 유형을 식별하고, FAQ 페이지는 Q&A 추출을 가능하게 하며, HowTo 스키마는 단계별 지침을 매핑합니다. 이 두 가지를 합치면 AI 개요에 표시되는 대부분의 내용을 다룹니다.
구현 팁: 항상 author, datePublished, dateModified, publisher 을 포함하세요. 이러한 항목이 없는 페이지는 체계적으로 우선 순위가 떨어집니다.
이 세 가지 스키마 유형은 함께 인용되는 것과 보이지 않는 것의 차이를 결정합니다. 한 가지 주의할 점은 스키마는 실제로 페이지에 있는 내용과 일치할 때만 작동한다는 것입니다. 사용자에게 표시되지 않는 FAQ를 마크업하면 승격이 아니라 불이익을 받게 됩니다.
기술적 요인: 페이지 속도, HTTPS, 모바일 및 크롤링 가능성
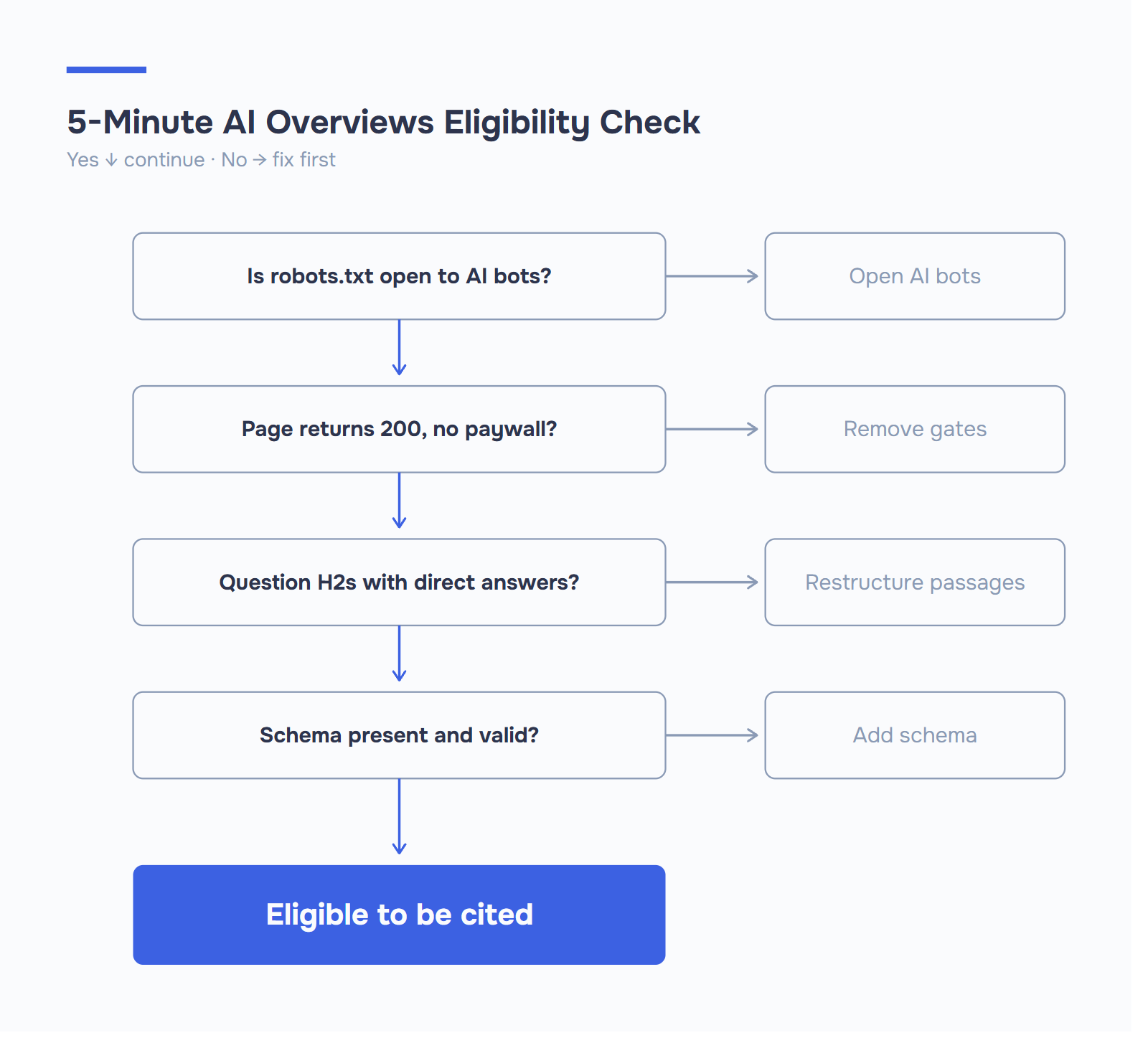
신호가 중요해지려면 먼저 AI 크롤러가 페이지에 도달해야 합니다. 당연한 이야기처럼 들립니다. 또한 의외로 많은 사이트가 조용히 자격을 박탈당하는 곳이기도 합니다.
봇이 URL을 가져올 수 없는 경우 이 목록의 다른 어떤 것도 도움이 되지 않습니다. 페이지는 깨끗한 200 상태 코드를 반환하고, 인증 벽 없이 로드되어야 하며, 트레이닝 크롤링과 실시간 접지 모두에서 도달 가능한 상태를 유지해야 합니다.
협상할 수 없는 기술적 기준선입니다:
- 모든 곳에서 HTTPS. 비보안 페이지는 모든 AI 표면에서 체계적으로 우선순위가 낮아집니다.
- 모바일 우선 렌더링. Google은 모바일 버전을 색인화합니다. 모바일 레이아웃이 표를 축소하거나 탭하여 펼치기 뒤에 FAQ를 숨기는 경우 AI는 축소된 버전을 보게 됩니다.
- 녹색으로 표시된 핵심 웹 바이탈. LCP 2.5초 미만, INP 200ms 미만, CLS 0.1 미만. 느린 페이지는 크롤링 빈도와 재접근 빈도가 낮으며, 최신성이 중요한 AI 개요에서 크롤링 빈도가 낮다는 것은 오래된 인용을 의미합니다.
- 중요한 콘텐츠를 위한 서버 렌더링 HTML. 답변 단락이 자바스크립트 하이드레이션 후에만 표시되는 경우 일부 크롤러는 이를 볼 수 없다고 가정합니다.
- 크롤러 액세스를 엽니다. 대부분의 사이트가 잘못 알고 있는 부분입니다.
2026년에 ‘접근 가능’이란 12개의 다른 사용자 에이전트가 접근할 수 있다는 의미입니다. 이제 AI 봇을 명시적으로 허용하는 깔끔한 robots.txt 이 기본이 될 것입니다. 다음은 모델 학습을 허용하지 않고 AI 검색 인용을 허용하는 구성입니다:
# Allow AI search crawlers
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: ClaudeBot
Allow: /
# Disallow training-only crawlers (optional, based on policy)
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
Perplexity는 robots.txt 지시어를 존중하며, 이를 허용하지 않는 사이트에는 PerplexityBot이 색인을 생성하지 않습니다. 따라서 실수로든 다른 이유로든 PerplexityBot이 차단된 경우 Perplexity 인용에 표시되지 않습니다.
피해야 할 사항 얇은 콘텐츠, 페이월, 상충되는 정보
AI 개요는 완전성, 일관성, 접근성을 신뢰할 수 없는 콘텐츠를 적극적으로 필터링합니다. 몇 가지 패턴으로 인해 페이지가 자동으로 제외됩니다:
- 얇은 콘텐츠. 질문에 대한 답변 없이 질문만 되풀이하거나 본론에 도달하기 전에 제휴사 관련 내용만 늘어놓는 페이지는 인용 출처에 거의 표시되지 않습니다. 실제 답변에 도달하기 전에 "X란 무엇인가"라는 프레임워크에 400단어를 쓰는 600단어짜리 글은 1단락에서 답변하는 600단어짜리 글에 밀립니다.
- 페이월 및 로그인 게이트. AI 크롤러가 인증 벽에 부딪히면 해당 페이지는 액세스할 수 없는 것으로 처리됩니다. 소프트 페이월(미리보기 + CTA)은 괜찮지만 하드 페이월은 실격 처리됩니다.
- 사이트 전체에서 상충되는 정보. 홈페이지에는 "2018년 설립", 블로그 게시물에는 "2017년 설립", 회사 소개 페이지에는 "5년 이상"이라고 표시되어 있습니다. AI는 이 세 가지의 우선순위를 모두 낮춥니다. 날짜, 클레임, 제품 설명 전반에서 엔티티의 일관성은 사람들이 생각하는 것보다 훨씬 더 중요합니다.
- 오래된 콘텐츠. 분기별로 업데이트되지 않는 페이지는 인용이 손실될 가능성이 약 3배 더 높습니다. AI 개요는 새로운 신호를 선호합니다.
- 누락된 E-E-A-T 신호. Google의 E-E-A-T 프레임워크는 단순한 품질 가이드라인이 아니라 사실상 순위 필터가 되었습니다. E-E-A-T 지표가 높은 페이지는 AI가 생성한 결과에서 눈에 띄게 높은 가시성을 보여줍니다.
- 모호한 저작자. 작성자 바이라인, 약력, 작성자 실체에 대한 링크가 없는 페이지는 아이러니하게도 AI를 포함하여 누구나 생성할 수 있는 것처럼 보입니다.
- 스키마가 잘못 정렬되었습니다. 페이지에 존재하지 않는 콘텐츠를 마크업하는 것은 스키마가 아예 없는 것보다 나쁩니다. 가장 일반적인 버전입니다: 페이지의 어느 곳에서도 독자에게 실제로 표시되지 않는 질문과 답변이 있는 FAQPage 스키마. 리치 결과 테스트에서 플래그를 지정하고 얼마 지나지 않아 인용이 사라집니다.
이 모든 것의 패턴은 다음과 같습니다: AI 개요는 확인할 수 있는 것만 인용합니다. 모호성을 유발하는 모든 것은 위험 신호로 취급됩니다.
모니터링: AI 개요에서 모양을 추적하는 방법
측정할 수 없는 것은 최적화할 수 없으며, AI 개요 추적은 기존 순위 추적보다 더 어렵습니다. 데이터는 Google 검색 콘솔, 타사 도구 및 수동 검사에 걸쳐 파편화되어 있습니다. 이것이 솔직한 현실입니다.
Google 검색 콘솔
GSC는 부분적인 가시성을 추가했지만, 주의 사항이 있습니다. 업데이트된 검색 노출 방식 필터에는 이제 AI 개요 및 AI 모드 쿼리를 위한 전용 세그먼트가 포함되어 있어, 전체 웹 검색 데이터에 포함되지 않고 이러한 AI 생성 형식에서 노출 수, 클릭 수 및 CTR을 구체적으로 확인할 수 있습니다.
찾으려면 실적 → 검색 결과 → 검색 노출 필터 → "AI 개요"로 이동합니다. 이렇게 하면 나머지 웹 검색 데이터와 분리된 AI 개요 내에서 노출된 쿼리로 범위가 지정된 노출 수, 클릭 수, CTR 및 평균 게재 순위가 표시됩니다.
살펴볼 내용:
- 노출 수 대 클릭 수 비율. AI 개요에 노출되면 노출 수는 많지만 기존 목록보다 CTR이 현저히 낮아집니다. 클릭 수가 평탄한 상태에서 갑자기 노출 수가 급증하는 것은 일반적으로 AI 개요가 트래픽을 가로채고 있다는 의미입니다.
- 쿼리 수준 CTR이 떨어집니다. CTR은 하락했지만 노출 수는 제자리걸음인 검색어는 이제 숙소 위에 AI 오버뷰가 트리거될 가능성이 높습니다.
- AI 개요 노출 수가 증가하는 페이지. 이것이 바로 인용 후보입니다. 구조, 스키마, 최신성을 감사하세요. 작은 수정이 가장 큰 영향력을 발휘하는 곳입니다.
타사 도구
인용 수준 추적("내가 인용되었는지 아닌지?")의 경우, GSC만으로는 충분하지 않습니다. Semrush, Ahrefs, SISTRIX는 특정 키워드에 대해 언제, 어디서 AI 오버뷰가 나타나는지 추적하는 기능을 갖추고 있어 이 부분을 채우기 위해 만들어진 것이 바로 SEO AI 오버뷰 도구입니다. 이를 GSC 데이터와 상호 참조하는 것은 영향력을 추정할 수 있는 가장 좋은 무료 방법입니다.
전용 AI 가시성 플랫폼(Otterly, OmniSEO, Wellows 등)은 AI 엔진을 직접 폴링하고 Google AI 개요, Perplexity, ChatGPT 검색, Gemini에 도메인이 표시되는지 여부를 기록함으로써 한 단계 더 나아갑니다.
수동 스팟 점검
확장성이 가장 낮으면서도 가장 안정적인 방법입니다. 20~30개의 타겟 쿼리를 선택합니다. Google AI Overviews, Perplexity, ChatGPT Search 및 Gemini에서 실행합니다. 기록합니다:
- 도메인이 인용되었나요?
- 특정 URL은 무엇인가요?
- 인용 목록에서 어느 위치에 있나요?
- 어떤 경쟁사 인용문이 귀사의 인용문과 나란히 배치되어 있나요?
이러한 열과 매월 업데이트되는 날짜가 포함된 간단한 Google 시트는 실제 인용 패턴을 파악하는 데 있어 대부분의 유료 도구를 능가합니다. 한 주 동안 어떤 검색어를 체계적으로 놓쳤는지, 어떤 경쟁자가 내 자리를 계속 차지하고 있는지 파악하는 것이 중요합니다.
유용한 KPI 프레임워크
다음 네 가지 지표를 추적하세요:
- 존재율 - 내가 인용으로 표시되는 추적된 쿼리의 비율
- 인용 위치 - 인용 목록의 위치(첫 번째 출처가 가장 많은 비중을 차지함)
- 트리거율 - AI 개요를 전혀 트리거하지 않는 추적된 쿼리의 %입니다.
- 경쟁사 중복 - 내 도메인과 함께 인용되는 도메인, 내 자리를 차지하고 있는 도메인
실제 자격 여부 확인
AI SEO 개요에 표시되는 방법 대부분의 SEO 조언은 몇 달에 걸친 콘텐츠 및 구조 작업에 초점을 맞추고 있습니다. 근본적인 질문인 봇이 애초에 페이지에 도달할 수 있는가? - 라는 근본적인 질문은 훨씬 덜 주목받습니다. 그리고 이 질문은 5분 안에 답을 찾을 수 있습니다.
PerplexityBot, OAI-SearchBot 또는 Google-Extended가 robots.txt 에서 차단된 경우 이 가이드의 다른 모든 최적화는 무의미합니다. 콘텐츠가 색인화되지 않고 인용되지 않으며 이미 검색의 절반 가까이를 차지하는 채널에서 보이지 않게 됩니다.
도메인에서 크롤러 액세스 검사를 실행하세요. ICODA의 AI 가시성 도구는 주요 AI 검색 봇(PerplexityBot, OAI-SearchBot, GPTBot, Google-Extended, ClaudeBot)이 실제로 귀하의 페이지에 접근할 수 있는지 테스트하고 각 봇이 인용 여부를 결정하는 데 사용하는 스키마와 기술 신호를 플래그 처리합니다. 저희가 감사한 대부분의 사이트에서 자신도 몰랐던 실수로 인한 블록이 하나 이상 발견되었습니다.
2026년 AI 개요 인용에서 수상한 브랜드는 가장 큰 도메인을 보유한 브랜드가 아닙니다. 페이지 수준뿐만 아니라 구절 수준에서도 깔끔하고 구조적이며 크롤링이 가능하고 신뢰할 수 있는 페이지를 보유한 브랜드입니다. 작업은 할 수 있습니다. 문제는 지금 시작할 것인지, 아니면 한 분기 더 CTR이 하락한 후에 시작할 것인지입니다.
자주 묻는 질문(FAQ)
상위 10위 안에 들어야 하지만 반드시 1위를 차지해야 하는 것은 아닙니다. 3~8위에 있는 페이지는 상위 결과보다 구조가 더 깔끔한 경우 정기적으로 AI 개요로 가져옵니다. AI는 가장 강력한 도메인 권한이 아니라 가장 명확하게 추출 가능한 구절을 선택합니다. 1위는 약 53%의 인용 확률을, 10위는 약 37%의 인용 확률을 제공합니다. 이 차이는 실재하지만 극복할 수 없는 수준은 아닙니다.
예, 소규모 사이트가 구조적으로 유리한 몇 안 되는 곳 중 하나입니다. AI 개요는 ‘쿼리 팬아웃’을 통해 쿼리를 하위 질문으로 분해한 다음 도메인 규모에 관계없이 각 조각에 대해 가장 명확한 답변을 가져옵니다. 깔끔한 H2 블록에서 하나의 좁은 하위 쿼리에 완벽하게 답변하는 600단어 페이지가 7단락에 같은 답변을 묻어두는 부피가 큰 기업 페이지를 이길 수 있습니다.
독립적인 연구에 따르면 FAQPage 스키마는 인용률을 30% 정도 높이는 것으로 나타났습니다. 스키마는 콘텐츠를 질문과 답변 쌍으로 미리 형식화하여 AI 시스템이 정보를 추출하고 표시하는 방식과 정확히 일치하기 때문에 작동합니다. 즉, 스키마는 페이지에 실제로 표시되는 내용을 반영하는 경우에만 작동합니다. HTML에 존재하지 않는 FAQ를 마크업하면 승격이 아니라 불이익을 받게 됩니다.
PerplexityBot을 차단하면 Perplexity 인용에서 완전히 보이지 않게 되며 robots.txt 지시문을 엄격하게 준수합니다. 특히 Google AI 개요의 경우 Google-Extended 및 Googlebot 이 허용되는지 확인해야 합니다. 이들은 별도의 규칙을 가진 별도의 봇이며, AI 크롤러 이전의 robots.txt 구성에서 실수로 차단되는 경우가 종종 있습니다. 봇이 페이지에 도달할 수 없다면 다른 모든 최적화는 무의미합니다.
거의 확실합니다. 순위를 매기는 쿼리에 대해 AI 개요가 트리거되면 GSC는 두 번의 노출을 계산하지만 클릭 기회는 한 번만 계산하며, 대부분의 사용자는 클릭하지 않습니다. 노출 수 급증, 클릭 수 보합 또는 하락, CTR 하락, 평균 순위 유지 또는 향상 등의 현상이 나타납니다. GSC에서 검색 노출 필터를 확인하고 ‘AI 개요’로 필터링하여 어떤 쿼리가 이러한 문제를 일으키는지 확인하세요.
공유


기사 평가하기













