Quando o Google introduziu as sínteses de AI SEO em quase metade dos resultados de pesquisa, surgiu uma pergunta incómoda na secretária de todas as equipas de SEO: se a resposta está na página, porquê clicar? A resposta honesta é que a maioria dos utilizadores não o faz. As taxas de cliques orgânicos caem até 61% quando uma visão geral da IA é activada. Mas as marcas que são citadas nesses resumos gerados por IA ganham 35% mais cliques orgânicos do que as que não o fazem.
Essa diferença — entre ser resumido e ser citado — decide agora para onde vai o tráfego de pesquisa. Para entender como chegar ao lado certo, analisamos os padrões documentados em estudos recentes de Visões Gerais de IA e comparámos quais as fontes que foram citadas e quais as que foram ignoradas. As descobertas contrariam várias suposições comuns sobre como aparecer nos manuais de SEO das visões gerais de IA.
De onde vêm as visões gerais de IA (não é apenas a classificação nº 1)
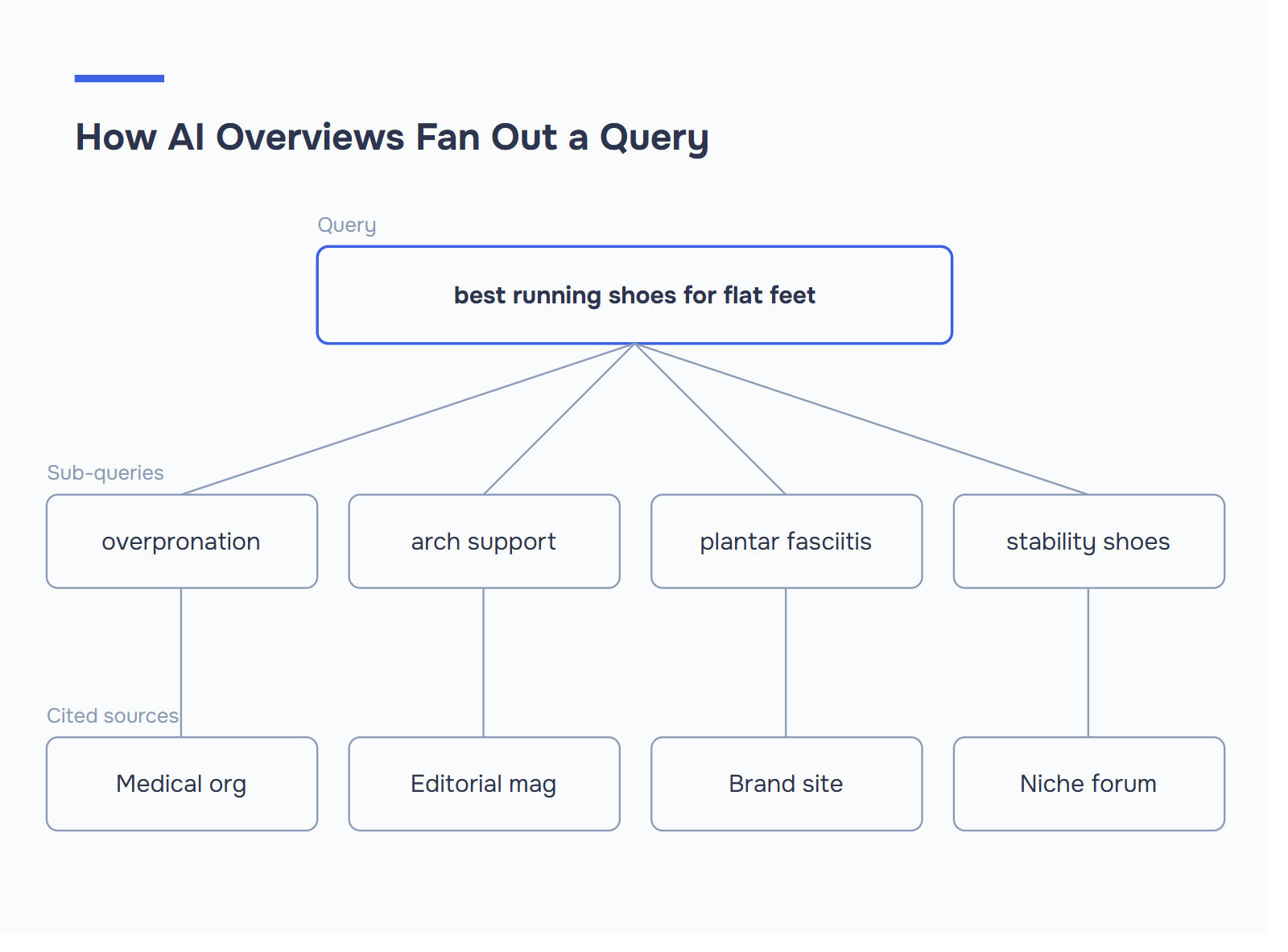
As sínteses de IA não se limitam a selecionar o principal resultado orgânico. Decompõe uma consulta em sub-perguntas, pesquisa cada uma delas separadamente e, em seguida, reúne citações de fontes que melhor respondem a cada fragmento - um processo a que a Google chama fan-out da consulta.
As hiperligações na primeira posição têm cerca de 53% de hipóteses de aparecer nas sínteses da IA, enquanto as da 10ª posição caem para cerca de 37%. Mais surpreendente: mais de 99% das citações da AI Overview provêm de páginas classificadas nos 10 primeiros resultados orgânicos, com uma sobreposição de citações de cerca de 94%. Portanto, o SEO tradicional continua a ser a base. Mas já não é o teto.
Nos padrões que analisámos, há três coisas que se repetem:
- A página citada nem sempre foi a mais bem classificada. As páginas nas posições 3-8 foram colocadas em visões gerais quando a sua estrutura era mais limpa do que a do resultado n.º 1. A IA dá prioridade à passagem mais clara, não ao domínio mais forte.
- Os sites mais pequenos vencem os maiores em consultas específicas. As marcas mais pequenas apareceram ao lado das grandes empresas e, em muitos casos, a fonte selecionada não era a página mais bem classificada.
- As subconsultas desbloqueiam citações de nichos. Uma consulta alargada sobre "AI Overviews ranking" pode citar uma fonte para o algoritmo, outra para o esquema e uma terceira para o rastreio. Isto é o fan-out da consulta em ação.
A conclusão prática: pára de otimizar as páginas como respostas monolíticas. Optimiza as secções - passagens de nível H2 que resolvem completamente uma sub-pergunta cada.
O diagnóstico de fan-out. Escolhe a tua palavra-chave alvo e escreve 3-5 subconsultas em que ela se decomporia de forma plausível. Para "melhores ténis de corrida para pés chatos": ténis para pronação excessiva, ténis com suporte de arco, material de corrida para fascite plantar, ténis de estabilidade vs ténis neutros. Agora analisa a tua própria página. Responde a cada subconsulta numa passagem autónoma com um H2 ou H3 claro? Se faltarem duas das cinco - ou estiverem enterradas num bloco de 400 palavras - é aí que o teu concorrente está a ser citado e tu não.
Requisitos de formato do conteúdo: A estrutura é a nova autoridade
A estrutura clara supera a densidade da prosa para a extração de IA. O maior fator determinante para saber se uma IA pode citar o teu conteúdo é se consegue extrair um bloco de respostas limpo e sem ambiguidades.
Três padrões estruturais dominaram as fontes citadas:
- Passagens de resposta autónomas. A investigação que analisou milhares de citações da Visão Geral da IA sugere que a IA dá prioridade a passagens que respondem completamente a perguntas em unidades autónomas de cerca de 130-170 palavras. Uma passagem que precise de contexto a partir de três parágrafos perderá para um parágrafo que se mantenha isolado.
- Arquitetura hierárquica H2/H3. As páginas citadas utilizaram esmagadoramente H2s do tipo pergunta ("O que é X?", "Como funciona Y?") seguidas de uma resposta direta nas primeiras 1-2 frases. O padrão é tão consistente que é quase um modelo.
- Listas, tabelas e blocos de passos. Parágrafos densos e títulos em falta dificultam a extração de conteúdos pela IA. Títulos hierárquicos claros, parágrafos curtos, listas com marcadores e tabelas melhoram a facilidade de leitura, tanto para os humanos como para os modelos de extração.
Eis o que os dados sugerem ser a diferença entre "classificado" e "citado":
| Elemento | Classificado mas não citado | Classificado e citado em visões gerais da IA |
|---|---|---|
| Frase de abertura em H2 | Estabelece o contexto | Responde diretamente à pergunta do título |
| Comprimento do parágrafo | Mais de 150-300 palavras | 40-80 palavras, uma ideia cada |
| Listas e tabelas | Raro ou decorativo | Utilizado para estruturar comparações e etapas |
| Rubricas | Genérico ("Visão geral", "Benefícios") | Forma de pergunta ("Como é que X funciona?") |
| Referências internas | "Como mencionámos acima…" | Cada secção é independente |
| Elementos multimodais | Apenas texto | Texto + imagem + dados estruturados |

As páginas que combinam texto, imagens, vídeo e dados estruturados apresentam uma probabilidade de seleção significativamente mais elevada em vários estudos de visão geral da IA. O conteúdo multimodal não é decoração - é um sinal de citação.
Marcação de esquema que ajuda: FAQPage, HowTo, Artigo
A marcação de esquema já não é um "bom ter". É a camada que diz aos sistemas de IA o que é realmente o teu conteúdo. Três tipos de esquemas fazem o trabalho pesado para a elegibilidade da síntese de IA.

Esquema da FAQPage
Porque funciona: pré-formata o teu conteúdo como pares de perguntas e respostas - exatamente como os sistemas de IA extraem e apresentam informações. Quando implementas o esquema FAQPage, estás a dizer explicitamente às plataformas de IA qual é a pergunta, qual é a resposta autorizada e como os elementos se relacionam. Isto elimina a carga interpretativa.
Dica de implementação: mantém as respostas entre 40-60 palavras para uma extração óptima. Estudos independentes estimam que o aumento médio da FAQPage nas taxas de citação da IA ronda os 30%.
Um bloco mínimo tem o seguinte aspeto:
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "How do I get cited in Google AI Overviews?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Rank in the top 10 for the target query, use question-form H2s with direct-answer first sentences, and add FAQPage or HowTo schema that mirrors the visible content."
}
}]
}
Coloca-o no <head> da tua página como um bloco <script type="application/ld+json"> e, em seguida, valida-o com o Teste de pesquisa avançada do Google antes de o enviar.
Esquema HowTo
Porque funciona: mapeia instruções passo a passo numa sequência que a IA pode interpretar instantaneamente. As sínteses de IA citam frequentemente procedimentos de 3-7 passos, o que torna este tipo de esquema particularmente valioso para conteúdos técnicos.
Dica de implementação: utiliza passos numerados, não parágrafos enterrados. O esquema reflecte o que a IA vai apresentar de qualquer forma - faz com que coincidam.
Esquema de artigo (com atribuição de autor)
Porque funciona: estabelece o conteúdo como editorial, anexa uma entidade de autor e liga a uma Organização. O esquema de artigo identifica o tipo de conteúdo; FAQPage permite a extração de P&R; o esquema HowTo mapeia instruções passo-a-passo. Em conjunto, cobrem a maior parte do que uma visão geral da IA irá revelar.
Dica de implementação: inclui sempre author, datePublished, dateModified, e publisher. As páginas sem estes elementos são sistematicamente despriorizadas.
Juntos, estes três tipos de esquema são a diferença entre ser citado e ser invisível. Uma ressalva: o esquema só funciona quando corresponde ao que está realmente na página. Marcar FAQs que não são visíveis para os utilizadores faz com que sejas penalizado, não promovido.
Factores técnicos: Velocidade da página, HTTPS, telemóvel e rastreabilidade
Antes de qualquer sinal ser importante, um rastreador de IA tem de chegar à tua página. Isto parece óbvio. É também onde um número surpreendente de sites se desqualificam discretamente.
Se um bot não conseguir obter o teu URL, nada mais nesta lista ajuda. As páginas precisam de devolver um código de estado 200 limpo, carregar sem paredes de autenticação e permanecer acessíveis durante os rastreios de treino e o aterramento em tempo real.
A linha de base técnica não negociável:
- HTTPS em todo o lado. As páginas não seguras são sistematicamente despriorizadas em todas as superfícies de IA.
- Renderização mobile-first. O Google indexa a versão para telemóvel. Se o teu layout para telemóvel recolher as tuas tabelas ou ocultar as tuas FAQs através do toque para expandir, a IA vê a versão recolhida.
- Core Web Vitals no verde. LCP inferior a 2,5s, INP inferior a 200ms, CLS inferior a 0,1. As páginas lentas são rastreadas com menos frequência e reposicionadas com menos frequência - e nas AI Overviews, onde a atualidade é importante, um rastreio menos frequente significa citações obsoletas.
- HTML renderizado pelo servidor para conteúdo crítico. Se os teus parágrafos de resposta só aparecem depois da hidratação do JavaScript, assume que alguns crawlers não os vão ver.
- Abre o acesso ao rastreador. Este é o ponto em que a maioria dos sítios se engana.
Em 2026, "acessível" significa acessível a uma dúzia de agentes de utilizador diferentes. Um robots.txt limpo que dá explicitamente as boas-vindas aos bots de IA é agora a base de referência. Aqui está uma configuração que permite a citação de pesquisa de IA sem permitir o treino de modelos:
# Allow AI search crawlers
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: ClaudeBot
Allow: /
# Disallow training-only crawlers (optional, based on policy)
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
O Perplexity respeita as diretivas robots.txt e o PerplexityBot não indexa nenhum site que não o permita. Por isso, se o PerplexityBot estiver bloqueado - acidentalmente ou não - serás invisível para as citações do Perplexity.
O que deves evitar: Conteúdo fraco, Paywalls, informações contraditórias
As sínteses de IA filtram agressivamente os conteúdos em que não se pode confiar para serem completos, consistentes ou acessíveis. Alguns padrões fazem com que as páginas sejam silenciosamente excluídas:
- Conteúdo superficial. As páginas que apenas reafirmam a pergunta sem a responder, ou que se enchem de coisas sem importância antes de chegarem à substância, quase nunca aparecem nas fontes citadas. Um post de 600 palavras que gasta 400 palavras no enquadramento "o que é X" antes de chegar à resposta real perde para um post de 600 palavras que responde no primeiro parágrafo.
- Paredes de pagamento e portas de acesso. Se o rastreador da IA atingir uma barreira de autenticação, a página é tratada como inacessível. Os paywalls suaves (pré-visualização + CTA) são bons; os paywalls rígidos desqualificam-te.
- Informações contraditórias em todo o sítio. A tua página inicial diz "fundada em 2018″, um post no blogue diz "estamos cá desde 2017″, a página Sobre diz "há mais de cinco anos". A IA desprioriza os três. A consistência das entidades - entre datas, declarações e descrições de produtos - é mais importante do que as pessoas imaginam.
- Conteúdo obsoleto. As páginas que não são actualizadas trimestralmente têm cerca de 3 vezes mais probabilidades de perder citações. As sínteses de IA favorecem sinais recentes.
- Falta o sinal E-E-A-T. A estrutura E-E-A-T do Google tornou-se efetivamente um filtro de classificação e não apenas uma diretriz de qualidade. As páginas com indicadores E-E-A-T fortes apresentam uma visibilidade visivelmente mais elevada nos resultados gerados pela IA.
- Autoria vaga. As páginas sem assinatura de autor, sem biografia e sem ligação a uma entidade de autor parecem poder ser geradas por qualquer pessoa - incluindo, ironicamente, por IA.
- Esquema desalinhado. Marcar conteúdo que não existe na página é pior do que não ter nenhum esquema. A versão mais comum: Esquema FAQPage com perguntas e respostas que não são realmente visíveis para um leitor em qualquer parte da página. O teste de pesquisa de resultados avançados assinala-o e as citações desaparecem pouco depois.
O padrão em todos eles: As sínteses de IA citam apenas o que podem verificar. Tudo o que cria ambiguidade é tratado como um sinal de risco.
Monitorização: Como rastrear aparições em visões gerais de IA
Não podes otimizar o que não podes medir - e o acompanhamento da visão geral da IA é mais difícil do que o acompanhamento tradicional da classificação. Os dados estão fragmentados no Google Search Console, em ferramentas de terceiros e em verificações manuais. Aqui tens o panorama honesto.
Consola de pesquisa do Google
O GSC adicionou visibilidade parcial, mas com ressalvas. O filtro Aparência da pesquisa atualizado inclui agora segmentos dedicados para visões gerais de IA e consultas do modo de IA, permitindo-te ver impressões, cliques e CTR especificamente a partir destes formatos gerados por IA, em vez de os ter dobrados em dados agregados de pesquisa na Web.
Para o encontrares: Desempenho → Resultados da pesquisa → Filtro de aparência da pesquisa → "Visão geral da IA". Isto dá-te impressões, cliques, CTR e posição média com o âmbito das consultas em que apareceste dentro de uma Visão geral da IA, separada do resto dos teus dados de pesquisa na Web.
O que deves ver:
- Rácio impressões vs. cliques. Aparecer numa visão geral da IA gera grandes contagens de impressões, mas uma CTR significativamente inferior à das listagens tradicionais. Um pico súbito de impressões com cliques fixos significa normalmente que uma visão geral da IA está a intercetar tráfego.
- A CTR ao nível da consulta desce. É provável que as consultas em que a CTR caiu, mas as impressões permaneceram estáveis, estejam agora a acionar as Visões gerais da IA acima da tua listagem.
- Páginas com impressões crescentes da Visão Geral da IA. Estes são os teus candidatos a citações. Audita a sua estrutura, esquema e atualidade - é aí que as pequenas correcções têm maior influência.
Ferramentas de terceiros
Para o rastreio ao nível das citações (o binário "fui citado ou não?"), o GSC não é suficiente. Esta é a lacuna que as ferramentas de AI SEO foram concebidas para preencher - Semrush, Ahrefs e SISTRIX têm funcionalidades para rastrear quando e onde as AI Overviews aparecem para palavras-chave específicas. Cruzar estas informações com os dados do GSC é a melhor forma gratuita de estimar o impacto.
As plataformas dedicadas de visibilidade de IA (Otterly, OmniSEO, Wellows e outras) vão mais longe, sondando diretamente os motores de IA e registando se o teu domínio aparece nas visões gerais de IA do Google, Perplexity, ChatGPT Search e Gemini.
Controlos manuais pontuais
O método menos escalável, mas também o mais fiável. Escolhe 20-30 consultas alvo. Executa-as no Google AI Overviews, Perplexity, ChatGPT Search e Gemini. Regista:
- O teu domínio foi citado?
- Que URL específico?
- Em que posição da lista de citações?
- Que citações da concorrência estão ao lado das tuas?
Uma simples folha do Google com essas colunas e a data - actualizada mensalmente - supera a maioria das ferramentas pagas para compreender os teus padrões de citação reais. Não estás à procura de uma semana má; estás à procura de quais as consultas que sistematicamente falhas e quais os concorrentes que continuam a ocupar o teu lugar.
Um quadro de KPI útil
Segue estas quatro métricas:
- Taxa de presença - % das tuas consultas controladas em que apareces como uma citação
- Posição de citação - em que posição na lista de citações te encontras (a primeira fonte tem mais peso)
- Taxa de acionamento - % das tuas consultas rastreadas que accionam uma visão geral da IA
- Sobreposição de concorrentes - que domínios são citados ao teu lado e quais estão a ocupar o teu lugar
Verifica se és realmente elegível
A maioria dos conselhos de SEO sobre como aparecer nas visões gerais da AI SEO centra-se no conteúdo e no trabalho de estrutura que se compõe ao longo de meses. A questão fundamental - será que os bots conseguem chegar às tuas páginas em primeiro lugar? - recebe muito menos atenção. E pode ser respondida em cinco minutos.
Se o PerplexityBot, o OAI-SearchBot ou o Google-Extended estiverem bloqueados no teu robots.txt, todas as outras optimizações deste guia são discutíveis. O teu conteúdo não está a ser indexado, não está a ser citado e és invisível para um canal que já representa quase metade da pesquisa.
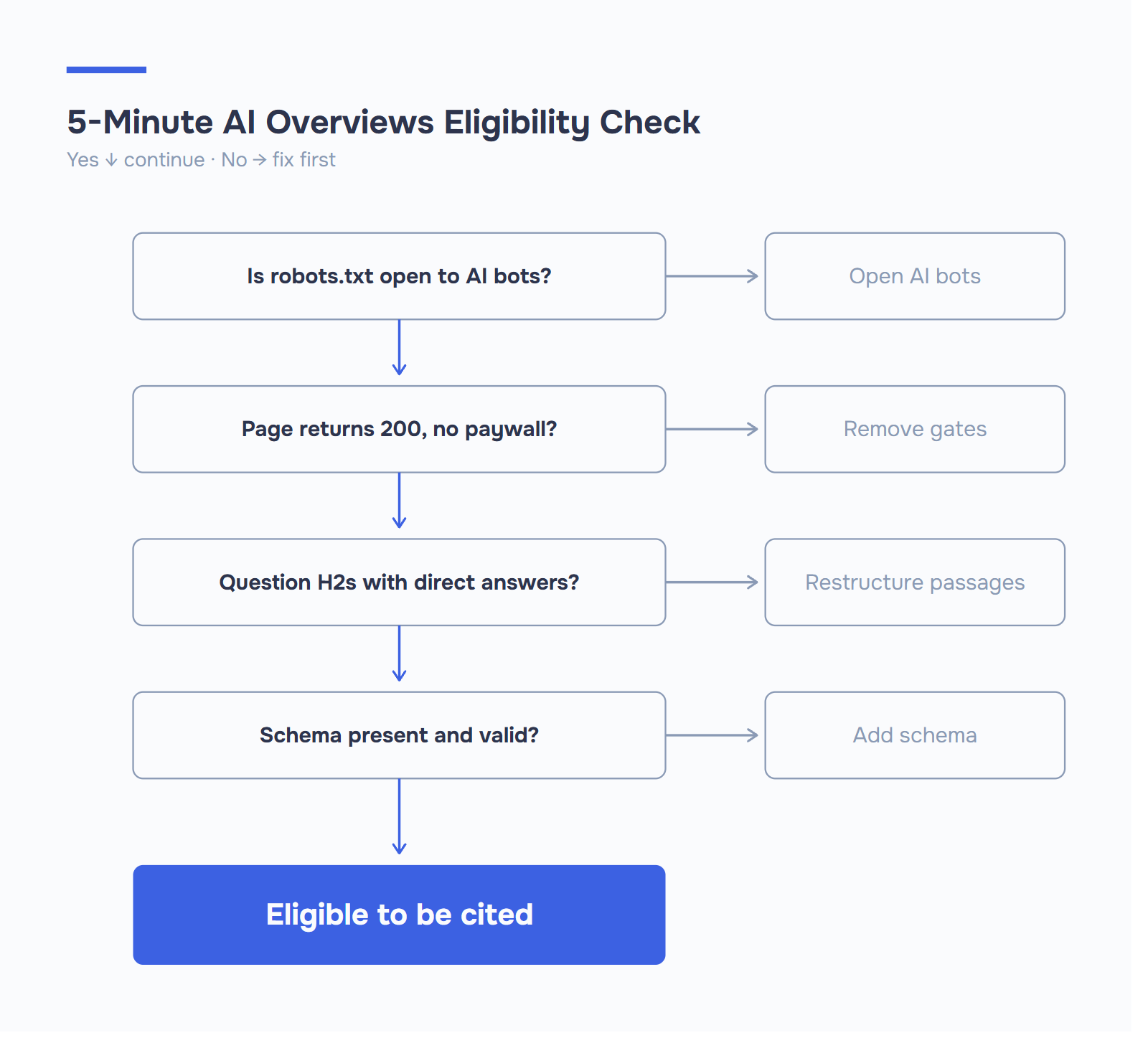
Executa uma verificação do acesso de crawlers ao teu domínio. A ferramenta de Visibilidade de IA da ICODA testa se os principais bots de pesquisa de IA conseguem realmente aceder às suas páginas - PerplexityBot, OAI-SearchBot, GPTBot, Google-Extended, ClaudeBot - e assinala o esquema e os sinais técnicos que cada bot utiliza para decidir se o cita ou não. A maioria dos sítios que auditámos encontrou pelo menos um bloqueio acidental que não sabia que tinha.
As marcas que ganharão as citações da Visão Geral da IA em 2026 não são as que têm os maiores domínios. São aquelas cujas páginas são limpas, estruturadas, rastreáveis e fiáveis - ao nível da passagem, não apenas ao nível da página. O trabalho é exequível. A questão é se começas agora ou depois de mais um trimestre de erosão da CTR.
Perguntas frequentes (FAQ)
Precisas de estar entre os 10 primeiros, mas não necessariamente em primeiro lugar. As páginas nas posições 3-8 são regularmente puxadas para as visões gerais da IA quando a sua estrutura é mais limpa do que a do resultado principal. A IA escolhe a passagem extraível mais clara, não a autoridade de domínio mais forte. A posição 1 dá-te cerca de 53% de hipóteses de citação; a posição 10 dá-te cerca de 37%. Essa diferença é real, mas não intransponível.
Sim, e é um dos poucos sítios onde os sítios pequenos têm uma vantagem estrutural. As sínteses de IA decompõem as consultas em subquestões através do "fan-out da consulta" e, em seguida, obtêm a resposta mais clara para cada fragmento, independentemente do tamanho do domínio. Uma página focada de 600 palavras que responda completamente a uma sub-pergunta restrita num bloco H2 limpo supera uma página empresarial inchada que enterra a mesma resposta no sétimo parágrafo.
O esquema FAQPage tem um aumento mensurável - estudos independentes apontam para cerca de 30% nas taxas de citação. Funciona porque pré-formata o teu conteúdo como pares de perguntas e respostas, que é exatamente a forma como os sistemas de IA extraem e apresentam informações. Dito isto, o esquema só funciona se refletir o que é realmente visível na página. Marcar FAQs que não existem no teu HTML faz com que sejas penalizado, não promovido.
Bloquear o PerplexityBot torna-te completamente invisível nas citações do Perplexity - respeita rigorosamente as diretivas robots.txt. Especificamente para o Google AI Overviews, tens de verificar se Google-Extended e Googlebot são permitidos. Estes são bots separados com regras separadas, e é comum encontrar bloqueios acidentais de configurações antigas de robots.txt que são anteriores aos rastreadores de IA. Executa uma auditoria de acesso aos rastreadores antes de qualquer outra coisa - qualquer outra otimização é discutível se os bots não conseguirem aceder às tuas páginas.
Quase de certeza que sim. Quando uma visão geral da IA é acionada para uma consulta em que estás classificado, o GSC conta duas impressões, mas apenas uma oportunidade de clique - e a maioria dos utilizadores não clica. A impressão digital é: as impressões aumentam, os cliques permanecem estáveis ou diminuem, a CTR cai, a posição média mantém-se ou melhora. Verifica o filtro Aparência da pesquisa no GSC e filtra por "Visão geral da IA" para confirmar quais as consultas que te estão a fazer isto.
Partilhar


Avaliar o artigo













