Le problème avec tout ce que vous avez lu jusqu’à présent
La plupart des reportages sur le mode IA tombent dans l’un des deux modes d’échec suivants. Le premier est un journalisme de produit haletant qui décrit les fonctionnalités sans expliquer la machine sous-jacente. Le second consiste en des prises de position rassurantes de la part de praticiens qui ont absorbé les points de vue de Google et les ont transmis - "le SEO standard est tout ce dont vous avez besoin", "le contenu de qualité l’emporte", "rien n’a fondamentalement changé".
Dans les deux cas, il s’agit d’une erreur qui coûtera de l’argent aux marques.
Cet article va au-delà du marketing. Il s’appuie sur les dépôts de brevets de Google, sur des études quantitatives vérifiées et sur quelques conclusions que la communauté au sens large a manifestement omis de prendre au sérieux. L’objectif est simple : à la fin, vous devriez comprendre exactement comment fonctionne le mode AI, pourquoi il rompt avec l’orthodoxie SEO traditionnelle et ce qu’il faut faire à ce sujet.
Nous allons couvrir un grand nombre de sujets. Commencez par le point le plus important, que presque tout le monde a mal compris.
Ce qu’est le mode IA (et ce qu’il n’est pas)
Voici l’idée fausse la plus coûteuse dans votre secteur à l’heure actuelle : le mode IA est une version plus intelligente de quelque chose que vous connaissez déjà.
En fait, ce n’est pas le cas. Et l’amalgame avec des systèmes familiers a été à l’origine de véritables erreurs stratégiques - les marques optimisant la visibilité des aperçus AI et supposant qu’elle se transfère, les équipes SEO citant le comportement du ChatGPT comme analogue, les praticiens traitant le mode AI comme un Featured Snippet plus sophistiqué. Il s’agit d’erreurs de catégorie. Elles conduisent à de mauvaises décisions d’investissement et à de mauvais cadres de mesure.
Soyons donc chirurgicaux en ce qui concerne la taxonomie.
Recherche classique
Un système de recherche de documents. Vous saisissez une requête ; il vous renvoie une liste d’URL classées. Le travail de Google s’arrête à la SERP. Ce que vous faites des liens bleus est votre affaire. Le jeu de l’optimisation est stable depuis vingt ans : signaler l’autorité au robot d’exploration, correspondre à l’intention du mot clé, gagner des signaux d’engagement. Vous connaissez ce système.
Aperçus sur l’IA (AIO)
Une couche générative boulonnée au-dessus de la recherche classique. AIO reprend les résultats de recherche existants de Google et les synthétise dans un paragraphe de synthèse, en s’inspirant presque exclusivement des pages déjà les mieux classées - 76,1 % des citations de l’aperçu AI proviennent des 10 premiers résultats. Il s’agit d’une fonctionnalité de l’interface utilisateur, et non d’un nouveau système de recherche. Considérez-le comme un extrait intelligent dont le texte est rédigé par un modèle linguistique. L’index qui se trouve en dessous est inchangé ; les signaux de classement qui se trouvent en dessous sont inchangés. Le SEO classique, bien appliqué, est largement suffisant pour l’éligibilité à l’AIO.
SGE (Search Generative Experience)
Mort. L’expérience des laboratoires qui a duré jusqu’en 2023-2024. Cessez d’y faire référence comme à un système vivant.
Gémeaux (autonome)
Un assistant LLM. Pas de connexion permanente à l’index de recherche en direct de Google. Pas d’intégration du Knowledge Graph. Pas de Shopping Graph. Ses réponses sont tirées de données d’entraînement, et non de recherches en temps réel. Un pipeline d’inférence complètement différent de tous les autres produits de cette liste.
Perplexité et recherche ChatGPT
Les systèmes de génération augmentée par récupération (RAG) qui puisent dans les index Web publics et synthétisent les réponses. Perplexity utilise une exploration en temps réel ; ChatGPT récupère le contenu complet de l’URL au moment de l’exécution par le biais de l’API Bing. Leur recherche est relativement simple - pas de modèle d’utilisateur persistant, pas d’infrastructure de connaissances à plusieurs niveaux, pas de contexte d’état à travers les sessions.
Mode AI
Aucune de ces réponses.
AI Mode est un moteur de recherche et de synthèse en plusieurs étapes, avec état, personnalisé et au niveau du passage, qui lance plusieurs sous-requêtes parallèles dans l’infrastructure de connaissance complète de Google - index de recherche, Knowledge Graph, Shopping Graph (plus de 50 milliards de produits) et Maps -, rassemble un corpus personnalisé de passages récupérés, les reclasse à l’aide d’un LLM par paire et génère une réponse avec une vérification de la citation au niveau des fragments.
Il ne s’agit pas d’une enveloppe autour de la recherche classique. Il s’agit d’un système de recherche parallèle qui se trouve à l’intérieur du même produit. Et le numéro qui devrait vous arrêter net :
Seuls 14 % des URL cités par AI Mode se classent dans le top 10 traditionnel de Google.
Pour les aperçus d’IA, ce chiffre est de 76 %. L’écart entre ces deux chiffres n’est pas une erreur d’arrondi. Il s’agit d’une constatation architecturale qui vous indique que le mode IA ne trouve pas le contenu par le biais des signaux de classement classiques. Il trouve le contenu par le biais d’un pipeline de recherche complètement différent - et les stratégies d’optimisation qui vous ont permis d’atteindre la première page peuvent être largement sans rapport avec le fait que vous soyez cité ou non.
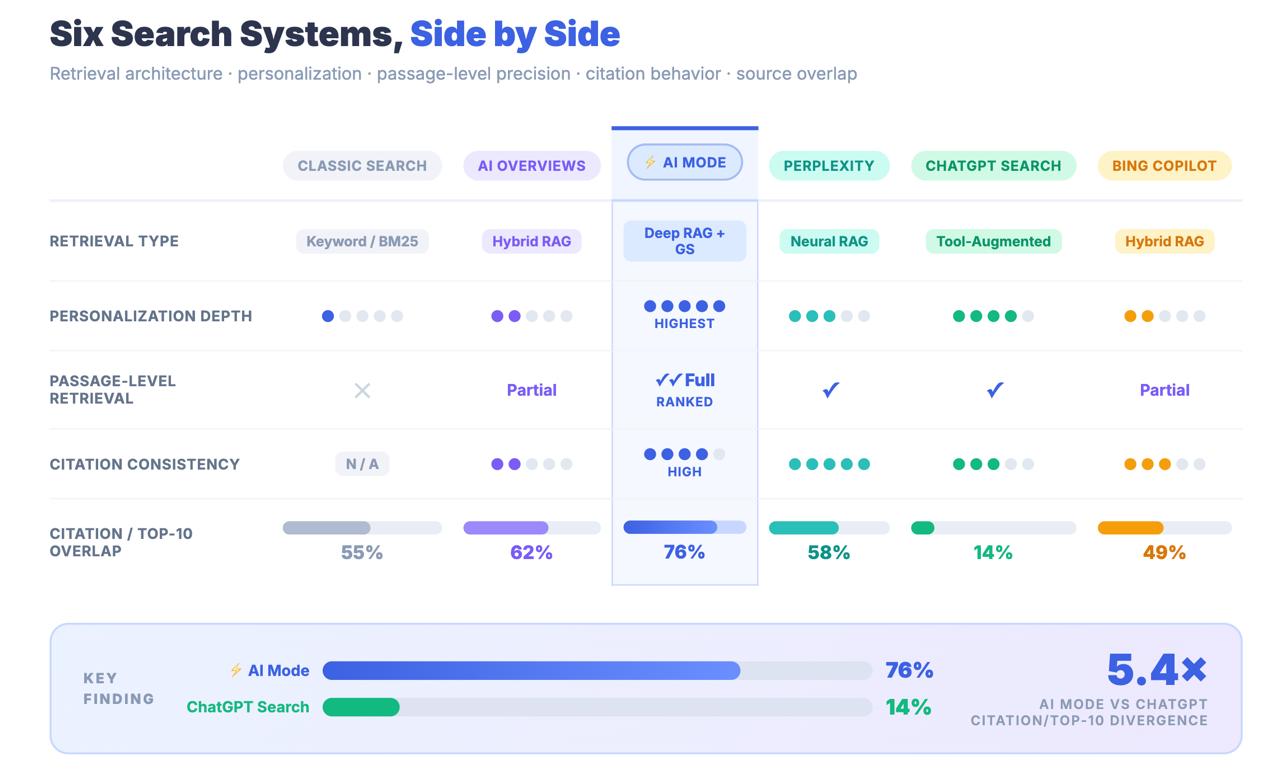
Il est nécessaire d’être sur la première page de Google pour la visibilité de l’aperçu de l’IA ; pour le mode IA, cela n’a guère d’importance.
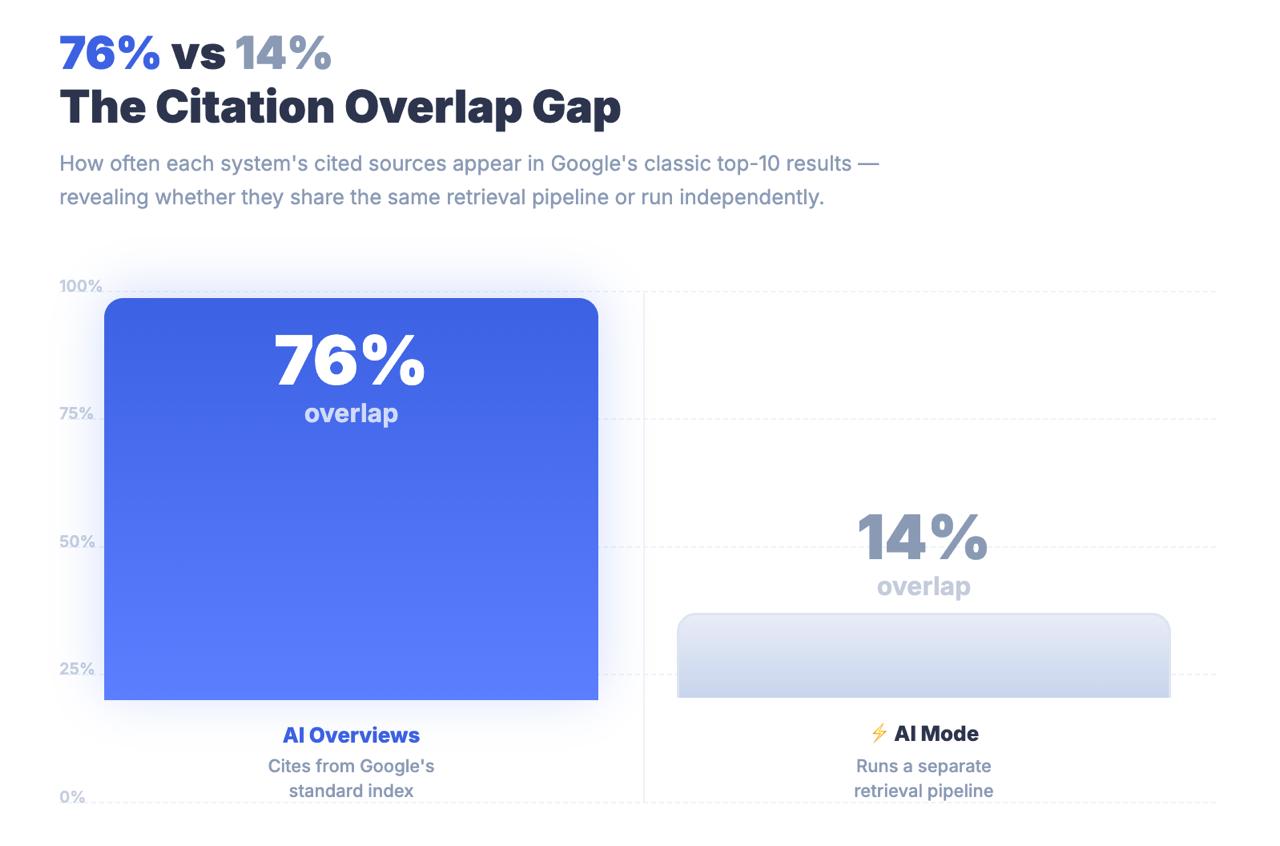
Les systèmes sont liés de la même manière qu’une bibliothèque et un assistant de recherche. Tous deux s’occupent de livres. L’un vous remet une étagère classée. L’autre lit les livres pour vous, synthétise la réponse et décide quels passages méritent d’être cités. Votre travail est fondamentalement différent selon le système pour lequel vous optimisez - et à l’heure actuelle, la plupart des équipes optimisent pour l’étagère alors que l’assistant de recherche est ce que leur public utilise.
Principaux enseignements : AI Mode partage une marque avec Google Search et une URL avec AI Overviews, mais il s’agit d’un système de recherche structurellement distinct. Seulement 14 % des citations d’AI Mode proviennent des résultats traditionnels du top 10, contre 76 % pour AI Overviews. Traiter AI Mode comme une extension AIO est une erreur de mesure qui a de réelles conséquences stratégiques.
L’architecture : Comment une requête devient une réponse
La plupart des explications sur le mode IA décrivent ce qu’il fait de l’extérieur : "il comprend mieux votre requête", "il synthétise des sources multiples", "il fournit des réponses conversationnelles". Ces descriptions ne sont pas fausses. Elles sont inutiles pour l’optimisation.
Ce qui suit est le pipeline complet, nommé composant par composant, avec les brevets qui régissent chaque étape. C’est ce que l’optimisation signifie réellement pour cibler - parce que vous ne pouvez pas améliorer systématiquement un système que vous ne pouvez pas nommer.
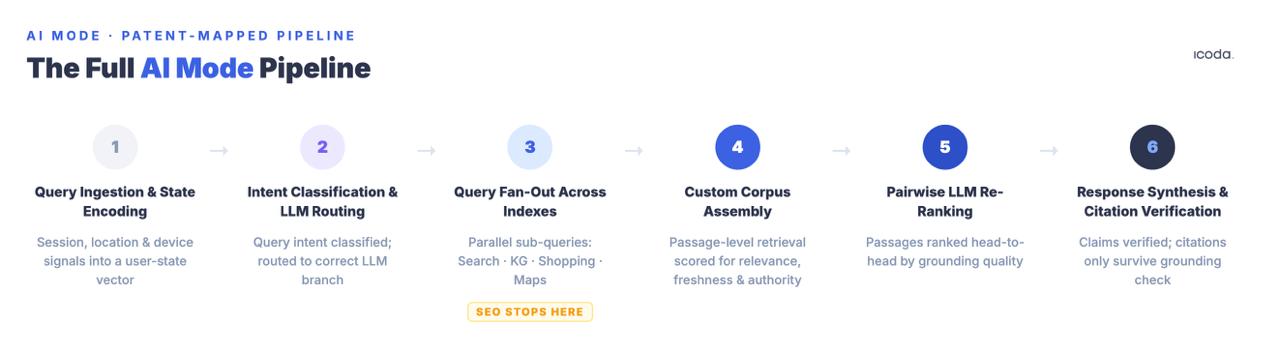
Le pipeline en six étapes est ce pour quoi vous optimisez réellement. La plupart des pratiques actuelles ne concernent qu’une seule étape.
Étape 1 : Ingestion des requêtes et codage de l’état de l’utilisateur
La requête brute n’entre pas directement dans le processus de recherche. Elle est d’abord associée au vecteur contextuel de l’utilisateur - un ensemble dense construit à partir de l’historique des sessions, des requêtes antérieures dans toutes les sessions, de l’appareil, de l’emplacement, de l’heure de la journée et des signaux de l’écosystème Google (Recherche, Maps, Gmail, YouTube). Ce vecteur de personnalisation modifie la signification de cette requête avant le début de la recherche.
Deux utilisateurs qui tapent des requêtes identiques donnent en fait des instructions de recherche différentes. Les implications de ce phénomène sont suffisamment importantes pour mériter leur propre section, qui vient immédiatement après celle-ci.
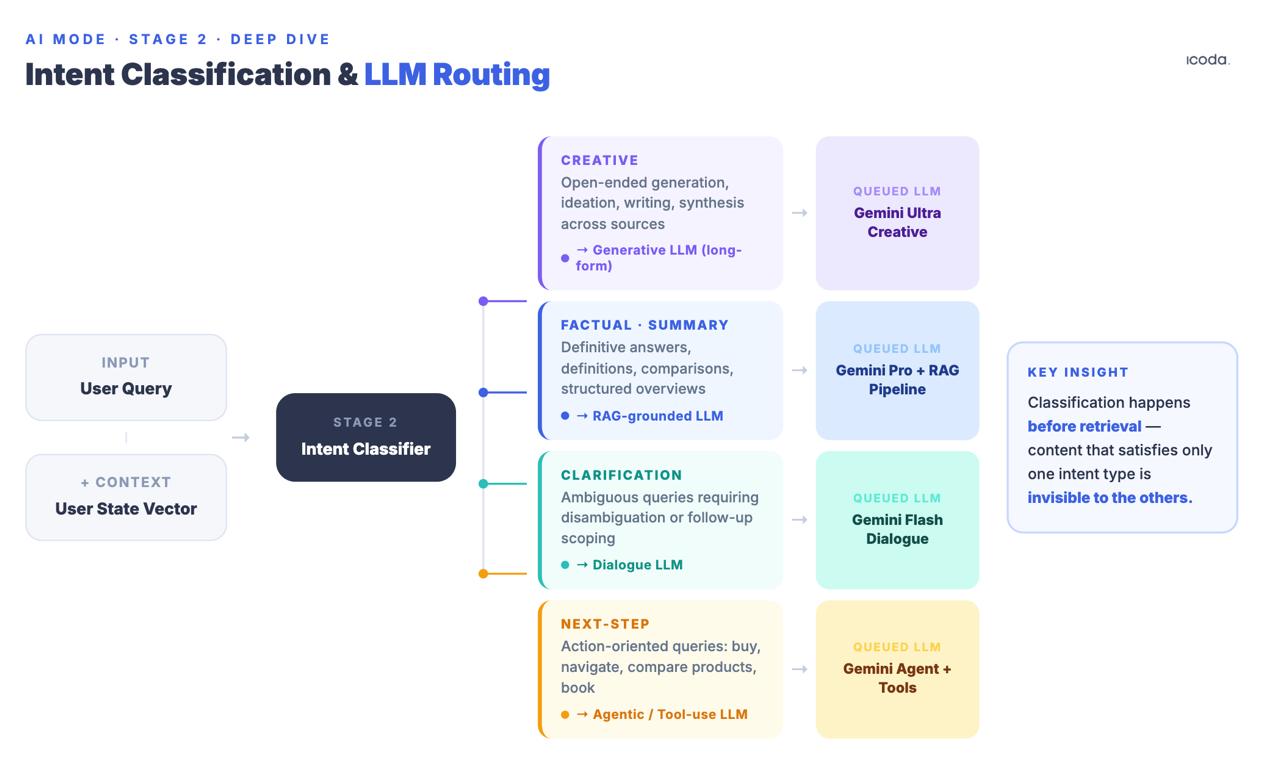
Étape 2 : Classification de l’intention de la requête et routage LLM
Avant la recherche, le système classe la requête en catégories d’intention : créative, factuelle/résumée, clarification ou étape suivante/tâche. En fonction de cette classification, différents modèles linguistiques en aval sont mis en file d’attente. Le brevet sur le chat avec état (US20240289407A1) les nomme explicitement : Creative Text LLM, SRP Generative LLM, Clarification LLM, Next Step LLM.
Cela se produit avant la récupération. La classification détermine non seulement le modèle qui synthétise la réponse, mais aussi les signaux de recherche les plus importants. Une page bien classée pour les requêtes d’information peut ne pas entrer du tout dans le pool de candidats si le classificateur d’intention achemine cette session vers un LLM d’étape suivante optimisant l’achèvement de la tâche plutôt que la synthèse d’informations.
Étape 3 : L’éventail des requêtes
C’est là que le mode IA diverge le plus nettement de tous les systèmes qui l’ont précédé.
Le système génère plusieurs sous-requêtes synthétiques à partir de l’original, couvrant huit types de variantes documentées : équivalent, lié, implicite, comparatif, clarification, temporel, géographique et contexte professionnel. Notez la date de dépôt. Cela fait sept ans que Google construit des fan-out multi-requêtes. AI Mode est le produit de consommation d’une longue piste architecturale.
Les types de variantes "implicites" et "comparatives" méritent une attention particulière car ils génèrent des requêtes que l’utilisateur n’a pas posées mais dont il aurait probablement besoin. Si quelqu’un cherche "le meilleur CRM pour les startups", le fan-out génère non seulement des reformulations mais aussi des requêtes implicites ("quel CRM permet de dépasser la série A ?"), des requêtes comparatives ("Salesforce vs. HubSpot pour les entreprises en phase de démarrage"), des requêtes temporelles ("les prix des CRM changent en 2025″) et des variantes de contexte professionnel qui distinguent un fondateur qui fait une recherche d’un responsable RevOps qui prend une décision.
Toutes les sous-requêtes sont exécutées simultanément dans l’index Google Search, le Knowledge Graph, le Shopping Graph et Maps. Google a confirmé que le mode AI peut exécuter "des centaines de recherches" pour une seule requête complexe. Le brevet de recherche thématique (US12158907B1) organise les résultats en groupes sémantiques ; les sous-thèmes déclenchent des cycles de recherche supplémentaires de manière itérative - ce qui signifie que le fan-out peut se répéter, et pas seulement éclater une fois.
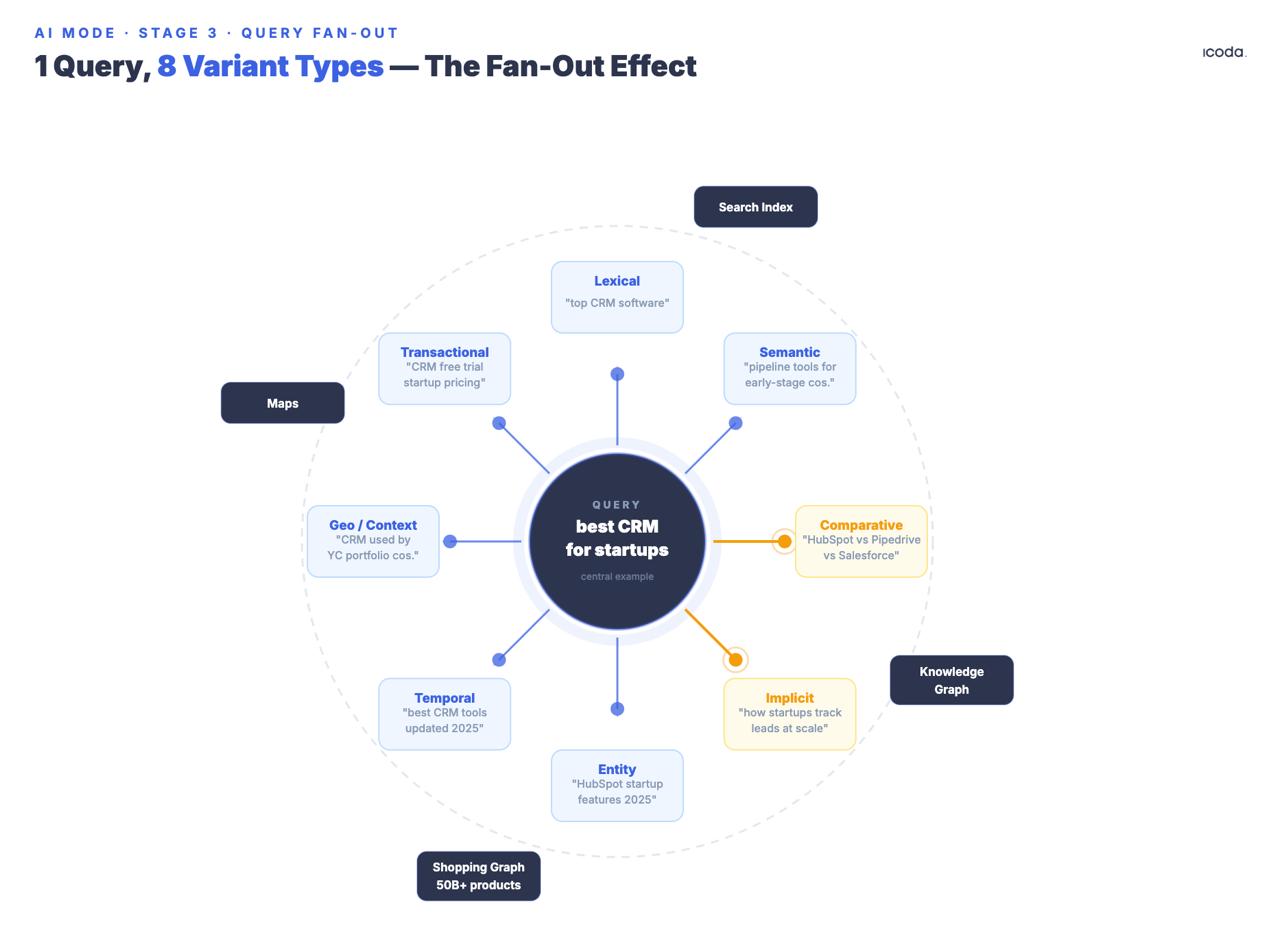
Google a déposé le brevet fondateur du fan-out en 2018 - AI Mode est le produit de consommation d’une construction architecturale qui a duré sept ans.
Une marque qui dispose d’un contenu faisant autorité sur le "meilleur CRM", mais qui n’a rien de comparatif, rien de temporel et rien de ciblant des variantes de contexte professionnel, est absente de plusieurs types de requêtes qui se déclenchent lors de chaque session pertinente. Le fan-out ne se préoccupe pas de l’autorité de votre domaine - il se préoccupe de savoir si chaque sous-requête de variante fait apparaître un passage qui remporte la comparaison par paire.
Étape 4 : Assemblage d’un corpus personnalisé
Les passages récupérés - pas des documents, mais des passages - sont assemblés dans un corpus personnalisé. Le brevet WO2024064249A1 décrit comment le système peut récupérer jusqu’à cinq morceaux adjacents autour d’un passage pertinent afin de préserver la cohérence contextuelle. Cela signifie que la fluidité de la prose dans une section de document est importante. Un argument bien structuré qui donne lieu à une recherche entraîne les paragraphes environnants dans le corpus.
Le corpus est personnalisé. Chaque utilisateur, chaque session, chaque requête en produit un différent. Il n’y a pas de fonds documentaire universel dans lequel votre contenu est en concurrence - il y a des millions de fonds spécifiques à l’utilisateur qui sont assemblés à la demande.
Étape 5 : Re-classement LLM par paire
Les passages de toutes les sous-requêtes en éventail sont en concurrence les uns avec les autres. Le mécanisme de classement n’est pas BM25. Ce n’est pas TF-IDF. Un LLM compare les passages par paires - quel passage satisfait le mieux une sous-requête donnée ? - au cours de plusieurs cycles de comparaison. Les gagnants avancent, les perdants sortent.
C’est à ce stade que la plupart des investissements en SEO ne parviennent pas à établir le contact. Les passages denses, directs et factuels qui répondent à des sous-questions spécifiques dès la première phrase remportent nettement les comparaisons par paires. Les contenus narratifs, discursifs et riches en opinions - le type de contenu qui fonctionne bien dans le SEO éditorial long format - ont tendance à perdre, parce qu’ils font travailler un LLM plus durement pour extraire l’affirmation pertinente. Un fil de discussion Reddit qui s’ouvre sur une réponse directe à une question de niche peut être plus performant qu’un guide de 3 000 mots qui fait autorité et qui enfouit la réponse dans le huitième paragraphe. Le mécanisme des paires récompense le gain immédiat, et non la crédibilité accumulée.
Étape 6 : Synthèse des réponses et vérification des citations
Les passages survivants sont transmis à Gemini. Gemini génère une réponse en langage naturel. Le Response Linkifying Engine effectue ensuite une vérification au niveau des fragments : il compare chaque fragment de la réponse générée à des passages spécifiques du corpus et incorpore les citations en ligne.
Il ne s’agit pas d’une attribution au niveau de la page. Une phrase de la réponse qui correspond à un passage de votre blog mérite d’être citée. Le reste de votre page peut ne pas être référencé du tout. Un article de 400 mots à forte densité factuelle peut citer un guide de 3 000 mots faisant autorité - parce qu’il produit plus de fragments vérifiables par unité de texte. Le mécanisme récompense structurellement la densité des affirmations par rapport à une couverture exhaustive. Il s’agit d’une inversion directe de l’objectif d’optimisation du SEO traditionnel pour les articles longs.
Principaux enseignements : Le mode IA est un pipeline en six étapes. Le SEO traditionnel s’occupe principalement de l’étape 3 (admissibilité à la recherche). La citation est gagnée ou perdue aux étapes 4 à 6 - densité au niveau du passage, concurrence LLM par paire et fondement factuel au niveau du fragment - dont aucune n’est prise en compte par les pratiques d’optimisation standard.
La couche de personnalisation : Pourquoi le Rank Tracking mesure une fiction
Il y a un fait intégré dans l’architecture du mode AI avec lequel l’industrie du SEO n’a pas entièrement pris en compte. Disons-le clairement :
La même requête émise par deux utilisateurs différents produit des ensembles de recherche différents. Pas des classements différents des mêmes documents. Des documents totalement différents.
Le brevet "User Embedding Models" décrit la manière dont Google encode les signaux comportementaux - requêtes, clics, temps d’attente, historique de localisation, activité de Maps, historique de visionnage de YouTube, contenu de Gmail - dans des vecteurs denses qui sont associés à chaque requête entrante. Le vecteur de personnalisation modifie la recherche avant qu’ un signal de classement traditionnel ne soit appliqué.
Vous n’êtes pas dans une course contre des concurrents pour un classement universel. Vous êtes dans une course à la pertinence dans des contextes de requêtes spécifiques d’utilisateurs-personnes que vous ne pouvez pas observer directement, que vous ne pouvez pas mesurer directement et que vous ne pouvez pas reproduire dans un outil de suivi des classements.
Ce qui nourrit l’utilisateur Embedding
Le brevet sur le chat avec état (US20240289407A1) et le brevet sur les modèles d’intégration de l’utilisateur décrivent ensemble une pile de personnalisation s’appuyant sur :
- Historique complet des requêtes dans toutes les sessions de recherche Google (pour les utilisateurs connectés)
- Cliquez, survolez et restez à l’échelle comportementale agrégée
- Type d’appareil et signaux de localisation
- Données de l’écosystème Google : Check-ins sur Maps, temps de visionnage de YouTube par thème, contenu de Gmail
Cette dernière catégorie mérite que l’on s’y attarde. La fonction "Personal Context", présentée en avant-première lors de la conférence Google I/O 2025 et partiellement déployée début 2026, intégrera explicitement les données de Gmail, de l’agenda et du compte Google directement dans la recherche. Lorsqu’elle sera complètement lancée, un utilisateur qui a envoyé un courriel au sujet d’un séjour au ski la semaine dernière obtiendra des réponses différentes à "équipement d’hiver" que celui qui a récemment acheté des chaussures de course sur Google Shopping. Le concept de résultat de recherche canonique pour n’importe quelle requête n’existera plus. Chaque résultat sera le fruit de l’historique comportemental de l’utilisateur dans l’ensemble de l’écosystème Google, et pas seulement de ses requêtes de recherche.
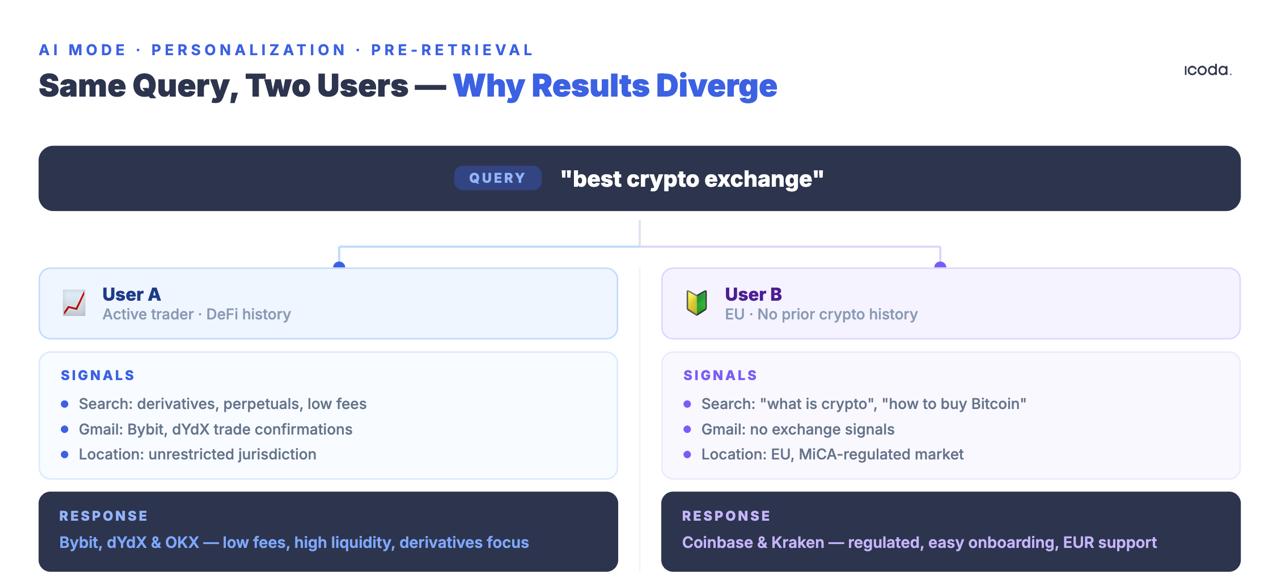
La conséquence de la mesure
Les outils de suivi des classements interrogent les utilisateurs dans des salles blanches, dans des environnements non contextualisés. Les utilisateurs réels sont profondément contextualisés. L’outil mesure une position hypothétique qu’aucun utilisateur réel ne voit.
Il ne s’agit pas d’un problème de précision. Il s’agit d’un problème de validité. La mesure n’est pas imprécise - elle mesure la mauvaise chose. Un numéro de suivi de position provenant d’un tracker de classement fonctionnant en mode IA représente l’expérience d’un utilisateur sans historique de recherche, sans signal de localisation, sans données d’écosystème et sans contexte de session. Cet utilisateur n’existe pas dans un volume significatif.
La décision antitrust souligne ce point d’une manière ironique. La mesure corrective de décembre 2025 exige que Google partage son index de recherche avec ses concurrents à deux reprises sur une période de cinq ans. Mais il ne peut pas partager les modèles d’intégration des utilisateurs. Les données de l’index - qui sont en train de devenir une marchandise - ne sont pas le moteur de la personnalisation du mode IA. C’est le volant d’apprentissage qui l’est : 14 milliards de requêtes quotidiennes, qui alimentent en permanence des modèles d’intégration des utilisateurs mis à jour, qu’aucun concurrent ne peut reproduire. Les concurrents obtiennent un aperçu de l’étagère. Google conserve le bibliothécaire qui a lu le visage de chaque utilisateur.
Ce qui fonctionne réellement pour les mesures
Les marques les mieux placées pour naviguer dans ce contexte ne sont pas celles qui disposent du suivi de classement le plus fidèle. Ce sont celles qui ont accepté que la recherche d’IA personnalisée nécessite un paradigme de mesure différent et qui l’ont mis en place. Les quatre indicateurs qui ont un signal réel :
Part de voix de la marque dans les réponses de l’IA, suivie par des outils tiers (Profound, ZipTie, Ahrefs Brand Radar). Il s’agit d’approximations basées sur l’échantillonnage et non d’une couverture complète, mais elles mesurent la présence des citations, ce qui est la bonne variable de sortie. Faites le suivi par rapport aux concurrents, et non par rapport à un score absolu.
Découplage impression/clic GSC au niveau du segment de requête. Les requêtes informatives dont les impressions augmentent avec un CTR en baisse sont la première signature visible de la cannibalisation du mode IA. Segmentez par type d’intention ; observez la divergence s’accentuer au fil du temps.
Audits manuels de citations en mode IA pour vos 20 requêtes les plus importantes sur le plan commercial. Notez quelles pages sont citées, quels passages apparaissent dans la réponse et si votre marque apparaît dans des sous-requêtes en éventail axées sur la concurrence - car c’est parfois le cas. Le mode AI génère en moyenne 3,3 mentions d’entités par réponse, contre 1,3 pour les aperçus AI. Votre marque peut être présente dans des sessions où votre domaine n’est jamais cliqué.
Le volume de recherche de marque comme signal en aval. Si le mode IA génère une notoriété de marque sans générer de clics directs - ce que l’architecture suggère de plus en plus - le volume de recherche de marque devrait évoluer en tant qu’indicateur retardé sur une fenêtre de 60 à 90 jours.
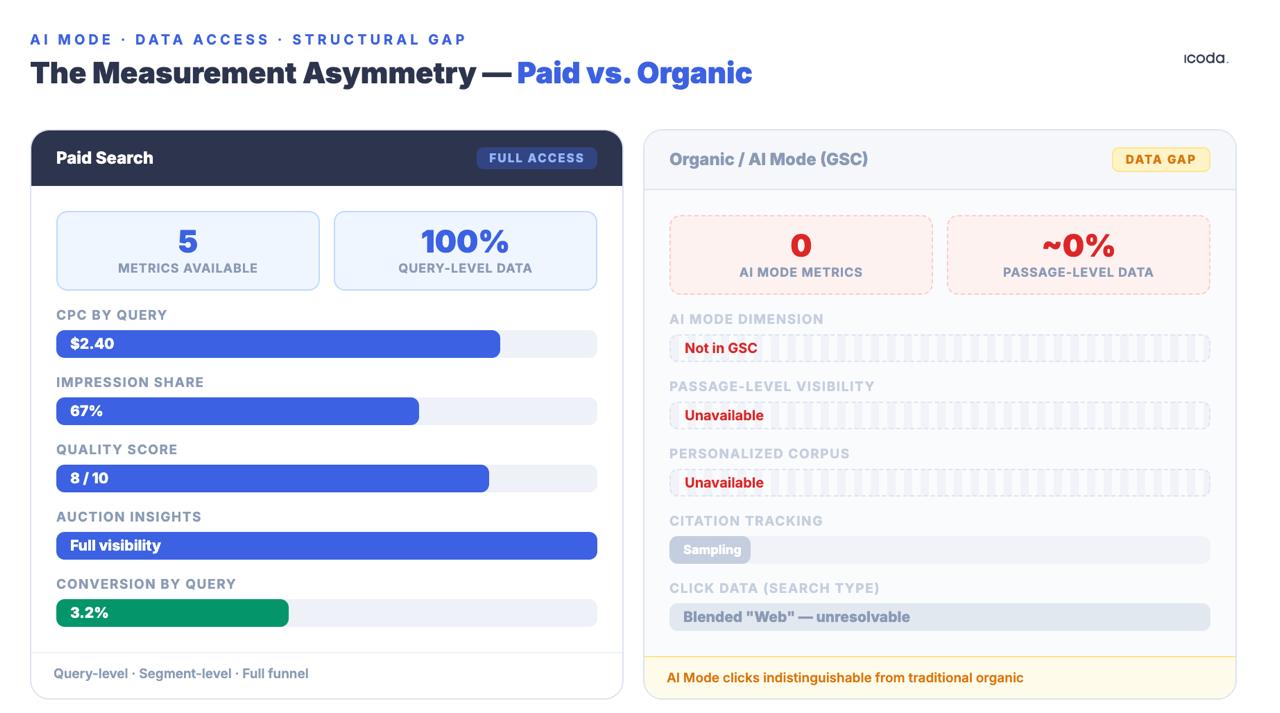
L’écart de mesure entre la recherche payante et la recherche organique existe depuis des années. Le mode IA l’a élargi pour en faire un gouffre structurel.
Aucun de ces éléments n’est parfait. L’asymétrie avec les équipes de recherche payante est structurelle et significative : les équipes de recherche payante disposent de données CPC, de parts d’impression, de scores de qualité et d’informations sur les enchères au niveau des requêtes. Les équipes organiques obtiennent des données GSC qui sont délibérément agrégées, échantillonnées et anonymisées - et les clics du mode IA sont mélangés dans le type de recherche générique " Web ", impossible à distinguer du trafic organique traditionnel. Cette lacune n’est pas un problème temporaire d’outillage. Il s’agit d’une décision délibérée de l’architecture du produit, et elle se creuse à mesure que le mode IA rend la recherche organique plus opaque, et non moins.
La réponse honnête est que vous ne pouvez pas actuellement mesurer avec précision la visibilité de votre mode IA. Vous pouvez mesurer les proxys. Vous pouvez suivre la présence de la marque. Vous pouvez observer la détérioration du ratio impression/clic en temps réel et l’utiliser pour établir des priorités. Mais vous ne devez pas confondre la mesure de proxy avec la vérité de terrain - et vous devez cesser de prétendre qu’un tracker de rang pointé sur une requête non contextualisée vous dit quelque chose de significatif sur la façon dont un utilisateur réel, connecté et contextualisé expérimente votre contenu dans le mode AI.
Principaux enseignements : Les vecteurs d’intégration de l’utilisateur modifient le mode de récupération de l’IA avant que les signaux de classement classiques ne s’appliquent, ce qui fait du suivi du classement - tel qu’il est pratiqué actuellement - une mesure d’un utilisateur qui n’existe pas. Déplacez la mesure principale de la position vers la part de voix de la marque dans les réponses de l’IA, complétée par les signaux de découplage du GSC et les audits manuels des citations.
Conclusion
Le mode AI n’est pas une recherche classique plus intelligente. Il s’agit d’un système de recherche distinct - six étapes, au niveau du passage, personnalisé avant l’application de tout signal de classement - et il décide déjà quelles marques existent dans les réponses que votre public est en train de lire.
Le chevauchement de 14 % des citations avec les résultats traditionnels du top 10 est révélateur : le classement et les citations sont désormais des variables indépendantes. Vous pouvez occuper la première page et être invisible en mode IA. Vous pouvez occuper la position 47 et obtenir des citations régulières si votre contenu produit des passages qui remportent des comparaisons LLM par paire pour les bonnes variantes de sous-questions.
L’architecture est documentée. Les brevets sont publics. La fenêtre d’adaptation avant que le mode IA ne devienne l’expérience de recherche par défaut se mesure en trimestres, et non en années.
La suite est un choix.
Partager


Notez l'article












