El problema con todo lo que has leído hasta ahora
La mayor parte de la cobertura del Modo IA cae en uno de estos dos modos de fracaso. El primero es el periodismo de producto sin aliento que describe características sin explicar la máquina subyacente. El segundo son las tomas tranquilizadoras de profesionales que han absorbido los temas de conversación de Google y los han transmitido: "SEO estándar es todo lo que necesitas", "el contenido de calidad gana", "nada ha cambiado fundamentalmente".
Ambas cosas son erróneas y costarán dinero a las marcas.
Este artículo va más allá del marketing. Se basa en los archivos de patentes de Google, en estudios cuantitativos verificados y en algunos hallazgos que la comunidad en general no se ha tomado en serio. El objetivo es sencillo: al final, deberías entender exactamente cómo funciona el modo AI SEO, exactamente por qué rompe la ortodoxia tradicional del SEO y exactamente qué hacer al respecto.
Vamos a cubrir mucho terreno. Empezaremos por lo más importante, en lo que casi todo el mundo se ha equivocado.
Qué es realmente el modo IA (y qué no es)
He aquí el concepto erróneo más caro de tu sector en este momento: que el Modo IA es una versión más inteligente de algo que ya conoces.
En realidad, no lo es. Y confundirlo con sistemas conocidos ha estado causando verdaderos errores estratégicos: marcas que optimizan la visibilidad de las Perspectivas AI y asumen que se transfiere, equipos de SEO que citan el comportamiento de ChatGPT como análogo, profesionales que tratan el Modo AI como un Featured Snippet más sofisticado. Son errores de categoría. Conducen a decisiones de inversión erróneas y a marcos de medición equivocados.
Así que seamos quirúrgicos con la taxonomía.
Búsqueda clásica
Un sistema de recuperación de documentos. Introduces una consulta y te devuelve una lista ordenada de URL. El trabajo de Google termina en la SERP. Lo que tú hagas con los enlaces azules es cosa tuya. El juego de la optimización se ha mantenido estable durante veinte años: señalar autoridad al rastreador, hacer coincidir la intención de las palabras clave, obtener señales de compromiso. Conoces este sistema.
Perspectivas generales de la IA (AIO)
Una capa generativa atornillada a la Búsqueda clásica. AIO toma los resultados de recuperación existentes de Google y los sintetiza en un párrafo resumen, extrayéndolos casi en su totalidad de las páginas ya clasificadas en los primeros puestos: el 76,1% de las citas del Resumen AI proceden de los 10 primeros resultados. Es una función de la interfaz de usuario, no un nuevo sistema de recuperación. Piensa en ello como un fragmento inteligente con un modelo lingüístico que escribe la copia. El índice que hay debajo no cambia; las señales de clasificación que hay debajo no cambian. El SEO clásico, bien aplicado, es en gran medida suficiente para la elegibilidad AIO.
SGE (Experiencia Generativa de Búsqueda)
Muerto. El experimento de Labs que funcionó hasta 2023-2024. Deja de referirte a él como un sistema vivo.
Géminis (independiente)
Un asistente LLM. Sin conexión persistente con el índice de búsqueda en directo de Google. Sin integración con Knowledge Graph. Sin Shopping Graph. Sus respuestas se obtienen a partir de datos de entrenamiento, no de recuperaciones en tiempo real. Un proceso de inferencia completamente diferente de todo lo demás de esta lista.
Búsqueda de Perplexity y ChatGPT
Sistemas de generación aumentada de recuperación (RAG) que extraen de índices web públicos y sintetizan las respuestas. Perplexity utiliza un rastreo en tiempo real; ChatGPT obtiene el contenido completo de la URL en tiempo de ejecución a través de la API de Bing. Su recuperación es comparativamente sencilla: sin modelo de usuario persistente, sin infraestructura de conocimiento multinivel, sin contexto de estado entre sesiones.
Modo IA
Ninguna de las anteriores.
AI Mode es un motor de recuperación y síntesis multietapa, estadístico, personalizado y a nivel de pasaje que lanza múltiples subconsultas paralelas contra toda la infraestructura de conocimiento de Google -índice de Búsqueda, Gráfico de Conocimiento, Gráfico de Compras (más de 50.000 productos) y Mapas-, reúne un corpus personalizado de pasajes recuperados, los reordena utilizando un LLM por pares y genera una respuesta con verificación de citas a nivel de fragmento.
No es una envoltura de la Búsqueda Clásica. Es un sistema de búsqueda paralelo que vive dentro del mismo producto. Y el número que debería pararte los pies
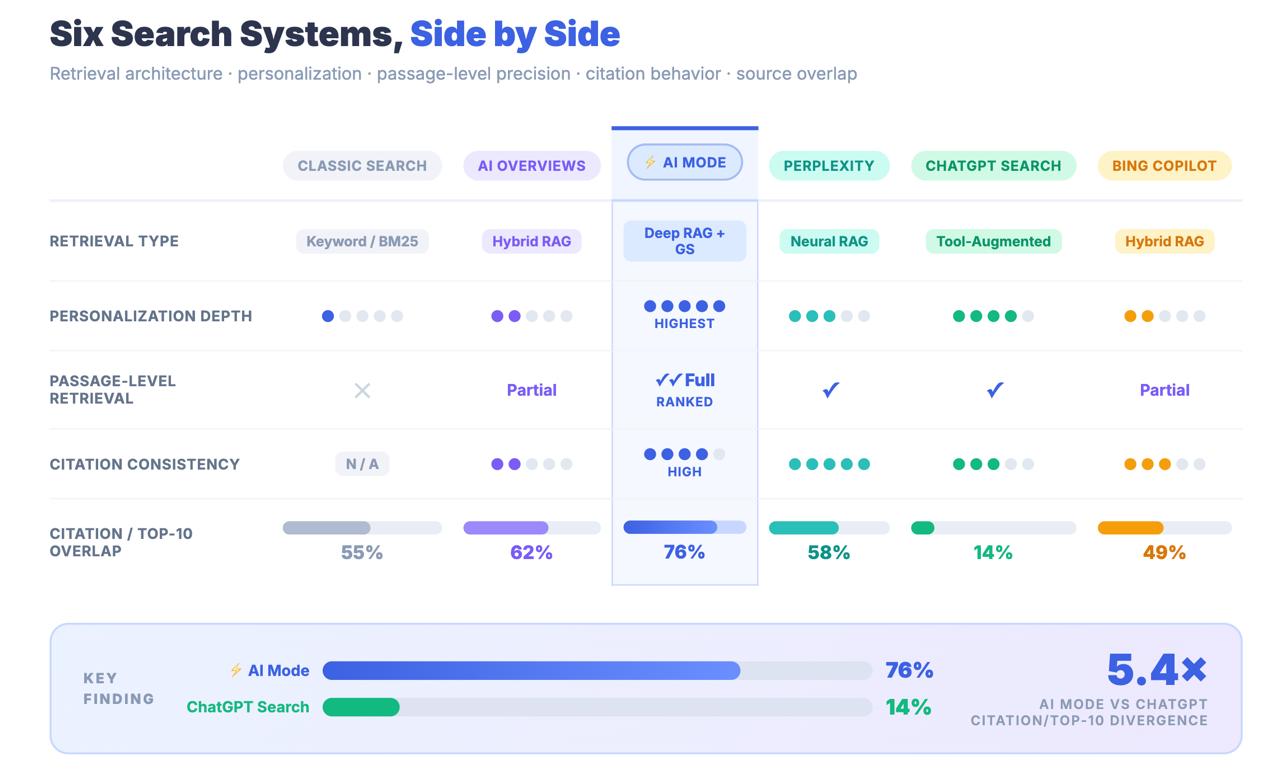
Sólo el 14% de las URL citadas por AI Mode se sitúan en el top 10 tradicional de Google.
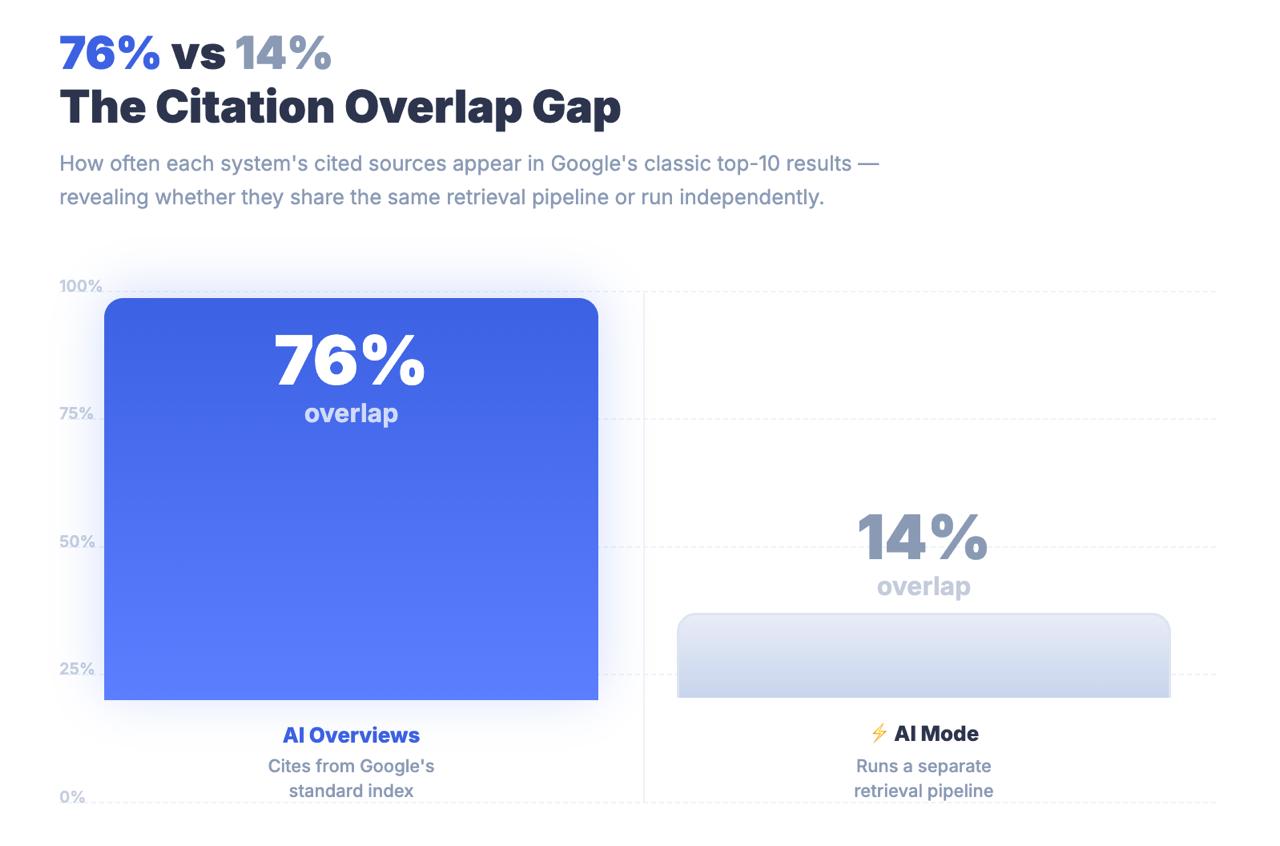
Para los Panoramas de IA, esa cifra es del 76%. La diferencia entre estas dos cifras no es un error de redondeo. Es un hallazgo arquitectónico que te indica que el Modo IA no está encontrando contenidos a través de las señales de clasificación clásicas. Busca el contenido a través de un proceso de recuperación completamente diferente, y las estrategias de optimización que te llevaron a la página uno pueden ser en gran medida irrelevantes para que te citen o no.
Estar en la página uno de Google es necesario para la visibilidad de AI Overview; para AI Mode, es en gran medida irrelevante.
Los sistemas están relacionados del mismo modo que una biblioteca y un asistente de investigación. Ambos tratan con libros. Uno te entrega una estantería clasificada. El otro lee los libros por ti, sintetiza la respuesta y decide qué pasajes merece la pena citar. Tu trabajo es fundamentalmente diferente dependiendo de para cuál estés optimizando, y ahora mismo, la mayoría de los equipos están optimizando para la estantería cuando el asistente de investigación es lo que su público está utilizando.
Conclusión clave: El Modo IA comparte una marca con la Búsqueda de Google y una URL con los Resúmenes IA, pero es un sistema de recuperación estructuralmente distinto. Sólo el 14% de las citas del Modo IA proceden de los resultados tradicionales del top-10, frente al 76% de las Perspectivas IA. Tratar el Modo IA como una extensión de las OIA es un error de medición con consecuencias estratégicas reales.
La Arquitectura: Cómo una consulta se convierte en una respuesta
La mayoría de las explicaciones del Modo IA describen lo que hace desde fuera: "entiende mejor tu consulta", "sintetiza múltiples fuentes", "proporciona respuestas conversacionales". Estas descripciones no son erróneas. Son inútiles para la optimización.
Lo que sigue es la tubería completa, nombrada componente por componente, con las patentes que rigen cada etapa. Esto es lo que la optimización significa realmente para el objetivo, porque no puedes mejorar sistemáticamente un sistema que no puedes nombrar.
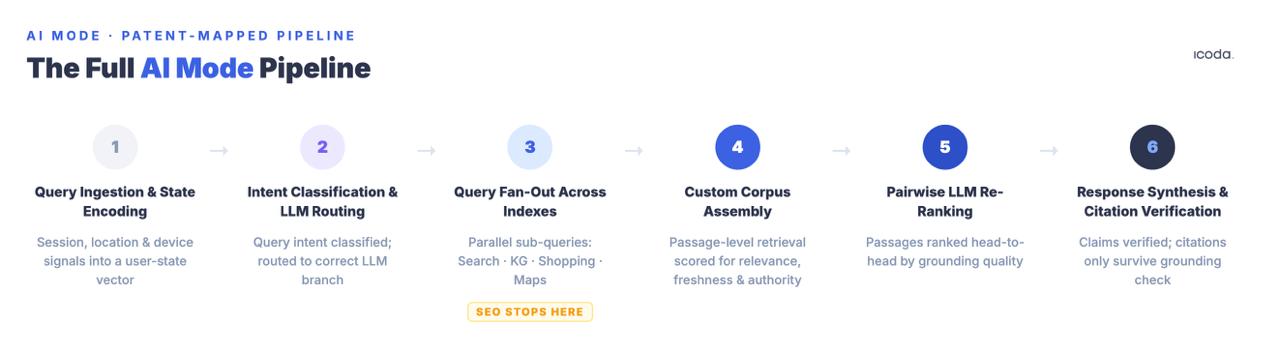
El pipeline de seis etapas es lo que realmente estás optimizando. La mayoría de las prácticas actuales se dirigen a una etapa.
Fase 1: Ingestión de consultas y codificación del estado del usuario
La consulta en bruto no entra directamente en la recuperación. Primero se empareja con el vector de contexto de estado del usuario: una densa incrustación construida a partir del historial de sesiones, las consultas anteriores en todas las sesiones, el dispositivo, la ubicación, la hora del día y las señales del ecosistema de Google (Búsqueda, Mapas, Gmail, YouTube). Este vector de personalización modifica lo que "esta consulta significa" antes de que comience cualquier recuperación.
Dos usuarios que escriban consultas idénticas están emitiendo instrucciones de recuperación diferentes. Las implicaciones de esto son lo suficientemente importantes como para merecer su propia sección, que viene inmediatamente después de ésta.
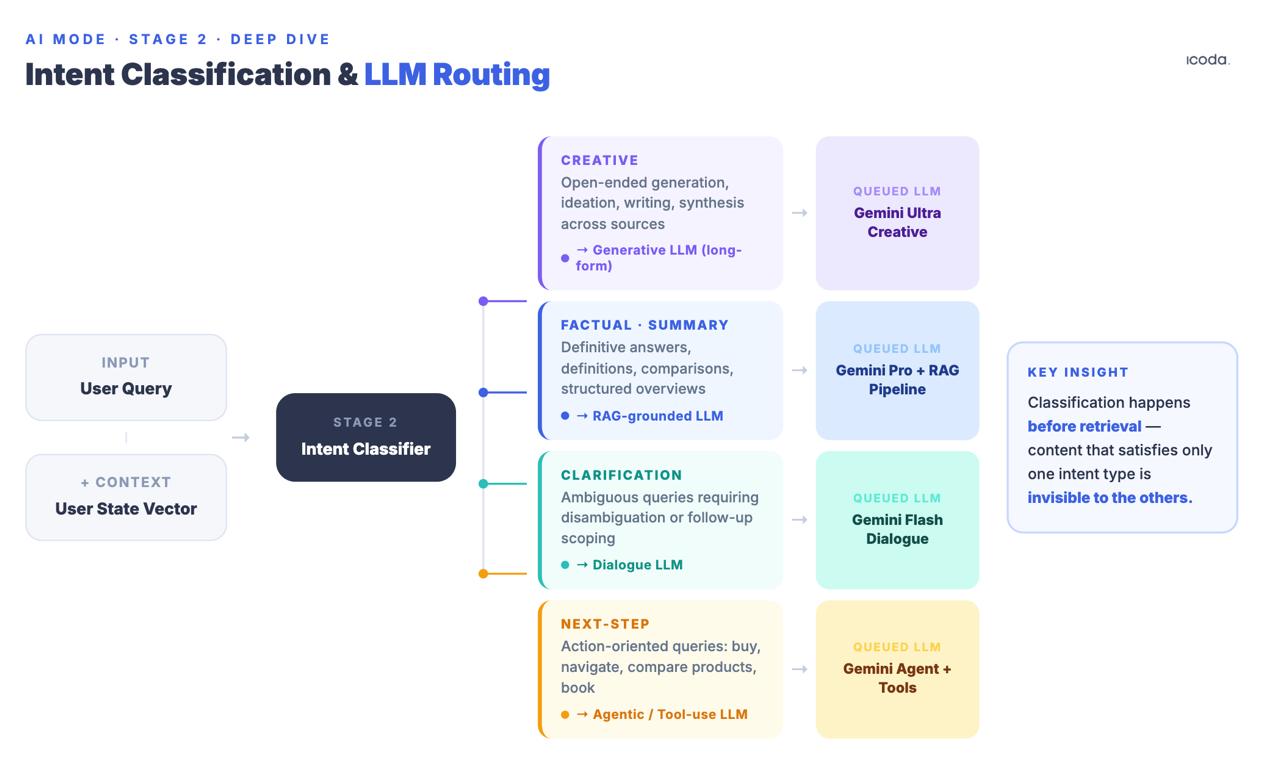
Fase 2: Clasificación de la intención de consulta y enrutamiento LLM
Antes de la recuperación, el sistema clasifica la consulta en categorías de intención: creativa, factual/resumen, aclaración o siguiente paso/tarea. En función de esta clasificación, se ponen en cola distintos modelos lingüísticos descendentes. La patente del chat con estado (US20240289407A1) los nombra explícitamente: LLM de Texto Creativo, LLM Generativo SRP, LLM de Aclaración, LLM de Siguiente Paso.
Esto ocurre antes de la recuperación. La clasificación determina no sólo qué modelo sintetiza la respuesta, sino qué señales de recuperación importan más. Una página que se clasifica bien para consultas informativas puede no entrar en el grupo de candidatos si el clasificador de intención dirige esta sesión a un LLM del siguiente paso que optimiza la realización de la tarea en lugar de la síntesis de la información.
Fase 3: Abanico de consultas
Aquí es donde el Modo IA diverge más marcadamente de todos los sistemas que le precedieron.
El sistema genera múltiples subconsultas sintéticas a partir del original, que abarcan ocho tipos de variantes documentadas: equivalentes, relacionadas, implícitas, comparativas, aclaratorias, temporales, geográficas y de contexto profesional. Fíjate en la fecha de presentación. Google lleva siete años construyendo fan-out de consultas múltiples. El Modo IA es el producto de consumo de una larga carrera arquitectónica.
Los tipos de variantes "implícitas" y "comparativas" merecen especial atención porque generan consultas que el usuario no ha hecho, pero que probablemente necesitará. Si alguien busca "el mejor CRM para startups", el fan-out genera no sólo reformulaciones, sino consultas implícitas ("¿qué CRM escala más allá de la Serie A?"), consultas comparativas ("Salesforce frente a HubSpot para empresas en fase inicial"), consultas temporales ("los precios de los CRM cambian en 2025″) y variantes de contexto profesional que distinguen a un fundador que investiga de un director de RevOps que decide.
Todas las subconsultas se ejecutan simultáneamente en el índice de Búsqueda de Google, Knowledge Graph, Shopping Graph y Mapas. Google ha confirmado que el Modo IA puede ejecutar "cientos de búsquedas" para una única consulta compleja. La patente de Búsqueda temática (US12158907B1) organiza los resultados en grupos semánticos; los subtemas desencadenan rondas de recuperación adicionales de forma iterativa, lo que significa que el abanico puede recurrir, no sólo estallar una vez.
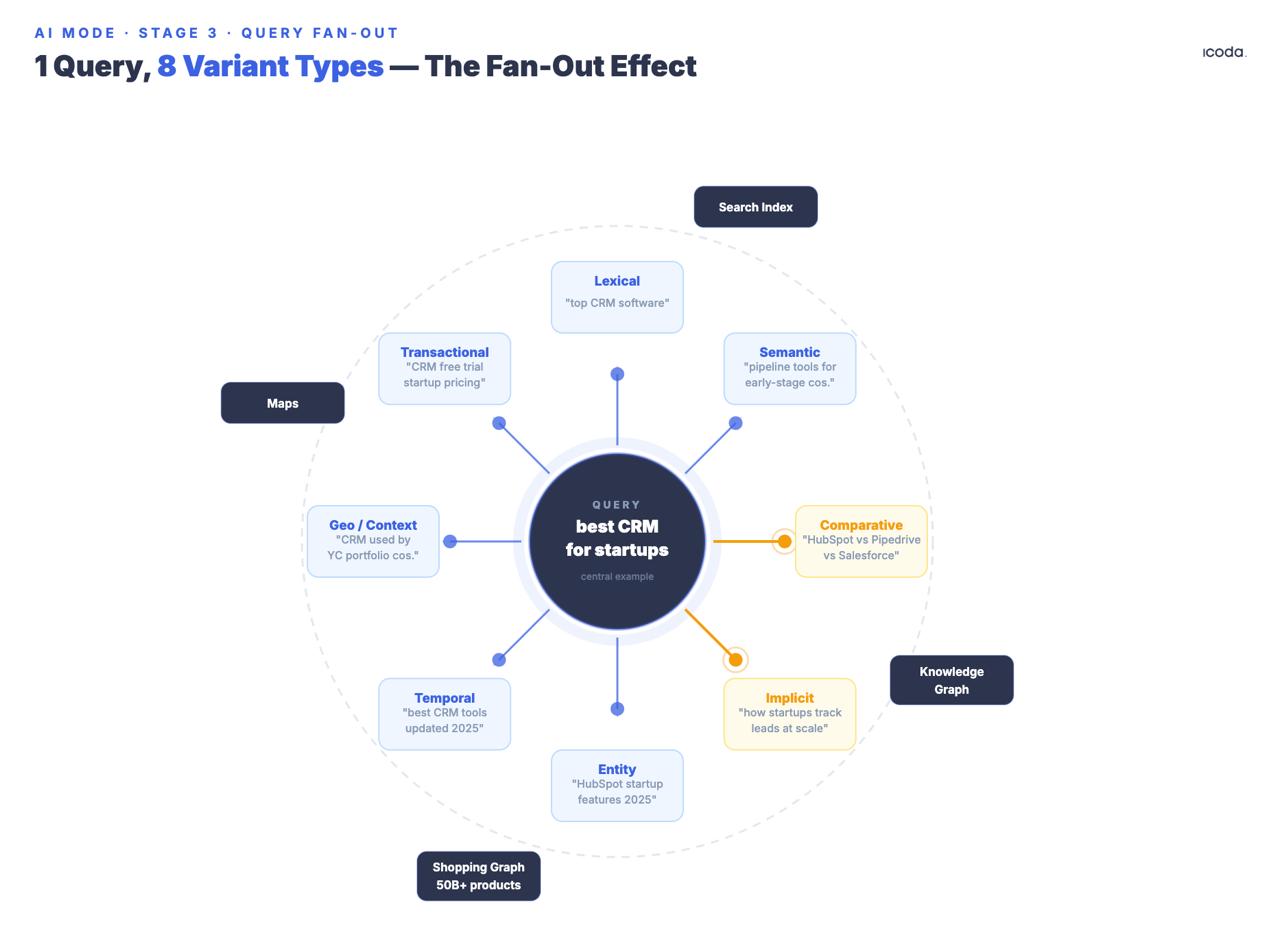
Google presentó la patente fundacional del fan-out en 2018: el Modo IA es el producto de consumo de una construcción arquitectónica de siete años.
Una marca que tiene contenido de autoridad sobre "el mejor CRM", pero nada comparativo, nada temporal y nada dirigido a variantes de contexto profesional, está ausente de múltiples tipos de consulta que se disparan en cada sesión relevante. Al fan-out no le importa la autoridad de tu dominio, sino si cada subconsulta variante hace aflorar un pasaje que gana la comparación por pares.
Fase 4: Montaje del corpus personalizado
Los pasajes recuperados -no documentos, sino pasajes- se reúnen en un corpus personalizado. La patente WO2024064249A1 describe cómo el sistema puede recuperar hasta cinco trozos adyacentes alrededor de un pasaje relevante para preservar la coherencia contextual. Esto significa que el flujo de la prosa a través de la sección de un documento importa. Un argumento bien estructurado que obtiene un resultado en la recuperación arrastra consigo a los párrafos circundantes al corpus.
El corpus es personalizado. Cada usuario, cada sesión, cada consulta produce uno distinto. No existe un corpus universal de documentos en el que compitan tus contenidos, sino millones de corpus específicos de cada usuario, reunidos bajo demanda.
Fase 5: Reclasificación LLM por parejas
Los pasajes de todas las subconsultas en abanico compiten entre sí. El mecanismo de clasificación no es BM25. No es TF-IDF. Un LLM compara pasajes por pares -¿qué pasaje satisface mejor una subconsulta determinada? - en varias rondas de comparación. Los ganadores avanzan; los perdedores salen.
En esta fase es donde actualmente la mayor parte de la inversión en SEO no consigue entrar en contacto. Los pasajes densos, directos y basados en hechos que responden a subpreguntas específicas en la primera frase ganan limpiamente las comparaciones por pares. El contenido narrativo, discursivo y cargado de opiniones -el tipo de contenido que funciona bien en el SEO editorial de formato largo- tiende a perder, porque hace que un LLM tenga que esforzarse más para extraer la afirmación relevante. Un hilo de Reddit que se abre con una respuesta directa a una pregunta de nicho puede superar a una guía autorizada de 3.000 palabras que entierra la respuesta en el párrafo ocho. El mecanismo de pares recompensa la recompensa inmediata, no la credibilidad acumulada.
Fase 6: Síntesis de respuestas y verificación de citas
Los pasajes supervivientes se envían a Géminis. Gemini genera una respuesta en lenguaje natural. A continuación, el Motor de Vinculación de Respuestas realiza una verificación a nivel de fragmento: coteja cada fragmento de la respuesta generada con pasajes específicos del corpus e incrusta las citas en línea.
No se trata de una atribución a nivel de página. Una frase de la respuesta que coincida con un pasaje de tu blog merece una cita. El resto de tu página puede no estar referenciada en absoluto. Un artículo de 400 palabras denso en datos puede citar más que una guía autorizada de 3.000 palabras, porque produce más fragmentos verificables por unidad de texto. El mecanismo recompensa estructuralmente la densidad de afirmación frente a la cobertura exhaustiva. Esto es una inversión directa de lo que optimiza el SEO tradicional de formato largo.
Conclusión clave: El Modo IA es una canalización de seis etapas. El SEO tradicional aborda principalmente la Etapa 3 (elegibilidad para la recuperación). Las citas se ganan o se pierden en las Etapas 4-6 -densidad a nivel de pasaje, competencia entre pares LLM y fundamentación factual a nivel de fragmento-, ninguna de las cuales se aborda en la práctica de optimización estándar.
La capa de personalización: Por qué el Rastreo de Posiciones es una Ficción de Medición
Hay un hecho incrustado en la arquitectura del Modo AI con el que la industria del SEO no ha contado del todo. Digámoslo claramente:
La misma consulta emitida por dos usuarios distintos produce conjuntos de recuperación diferentes. No clasificaciones diferentes de los mismos documentos. Documentos totalmente distintos.
La patente Modelos de incrustación de usuarios describe cómo Google codifica las señales de comportamiento -consultas, clics, tiempo de permanencia, historial de ubicaciones, actividad de Maps, historial de visionados de YouTube, contenido de Gmail- en vectores densos que se emparejan con cada consulta entrante. El vector de personalización modifica la recuperación antes de que se aplique cualquier señal de clasificación tradicional.
No estás compitiendo por una posición universal. Estás en una carrera por la relevancia dentro de contextos de consulta específicos del usuario-persona que no puedes observar directamente, medir directamente ni replicar en una herramienta de seguimiento del rango.
Lo que alimenta al usuario Incrustación
La patente del chat con estado (US20240289407A1) y la patente de los modelos de incrustación de usuarios describen conjuntamente una pila de personalización basada en:
- Historial completo de consultas en todas las sesiones de la Búsqueda de Google (para usuarios registrados)
- Patrones de click, hover y dwell a escala de comportamiento agregado
- Tipo de dispositivo y señales de localización
- Datos del ecosistema Google: Comprobaciones de Maps, tiempo de visionado de YouTube por temas, contenido de Gmail
Merece la pena detenerse en esta última categoría. La función "Contexto personal" -presentada en Google I/O 2025 y en despliegue parcial a principios de 2026- incorporará explícitamente datos de Gmail, Calendar y cuentas de Google directamente en la recuperación. Cuando se lance por completo, un usuario que envió un correo electrónico sobre viajes de esquí la semana pasada obtendrá respuestas diferentes en el Modo IA a "ropa de invierno para exteriores" que alguien que compró recientemente zapatillas de correr en Google Shopping. El concepto de un resultado de búsqueda canónico para cualquier consulta estará funcionalmente muerto. Cada resultado será producto del historial de comportamiento del usuario en todo el ecosistema de Google, no sólo de sus consultas de búsqueda.
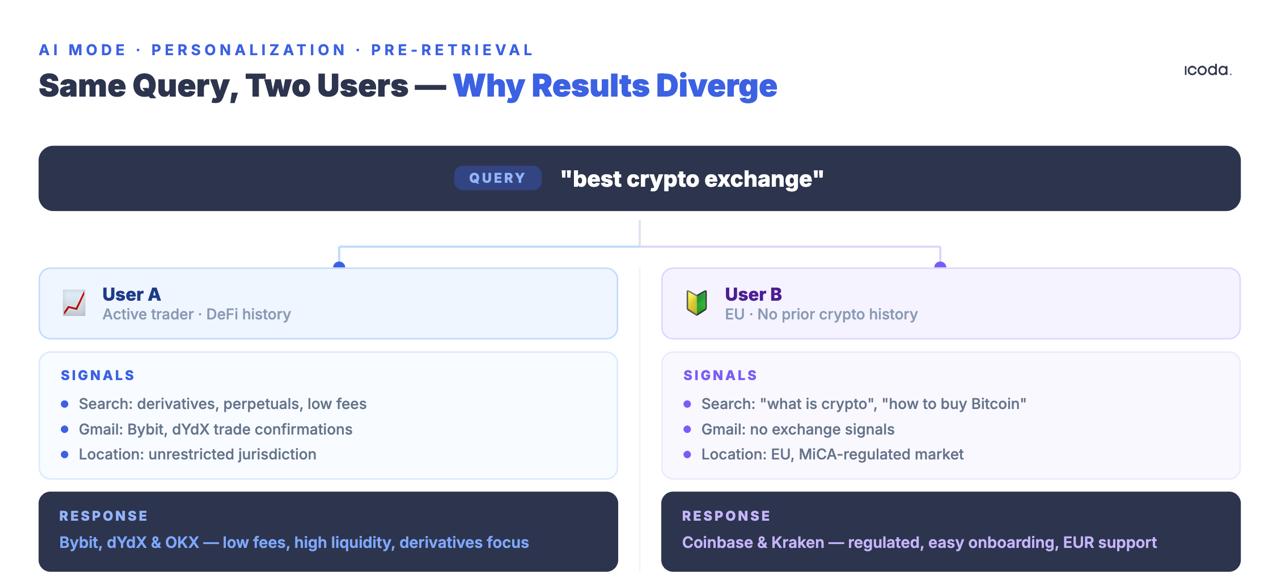
La consecuencia de la medición
Las herramientas de seguimiento de rango consultan desde entornos de sala blanca, descontextualizados. Los usuarios reales están profundamente contextualizados. La herramienta mide una posición hipotética que ningún usuario real ve.
No es una queja de precisión. Es una queja de validez. La medición no es imprecisa, sino que mide algo totalmente erróneo. Un número de seguimiento de posición de un rastreador de rango que se ejecuta contra el Modo IA representa la experiencia de un usuario sin historial de búsqueda, sin señal de ubicación, sin datos de ecosistema y sin contexto de sesión. Ese usuario no existe en ningún volumen significativo.
La sentencia antimonopolio agudiza este punto de forma irónica. La solución de diciembre de 2025 obliga a Google a compartir su índice de búsqueda con sus competidores dos veces en cinco años. Pero no puede compartir los modelos de incrustación de usuarios. Los datos del índice -que ahora se están convirtiendo en una mercancía- no son lo que impulsa la personalización del Modo IA. Es el volante de aprendizaje: 14.000 millones de consultas diarias, que alimentan continuamente incrustaciones de usuario actualizadas que ningún competidor puede reproducir. Los competidores obtienen una instantánea de la estantería. Google se queda con el bibliotecario que ha leído la cara de cada cliente.
Lo que realmente funciona para medir
Las marcas mejor posicionadas para navegar por esto no son las que tienen el seguimiento de rango de mayor fidelidad. Son las que han aceptado que la recuperación personalizada de la IA requiere un paradigma de medición diferente y han construido hacia él. Los cuatro proxies que tienen una señal real:
Participación de la marca en las respuestas de la IA, rastreada mediante herramientas de terceros (Profound, ZipTie, Ahrefs Brand Radar). Son aproximaciones basadas en muestreos, no una cobertura completa, pero miden la presencia de citas, que es la variable de salida correcta. Realiza el seguimiento en comparación con los competidores, no con una puntuación absoluta.
Desacoplamiento impresión/clic GSC a nivel de segmento de consulta. Las consultas informativas que muestran un aumento de las impresiones con un descenso del CTR son la principal firma visible de la canibalización del Modo IA. Segmenta por tipo de intención; observa cómo se agudiza la divergencia con el tiempo.
Auditorías manuales de citas en modo IA para tus 20 consultas más importantes desde el punto de vista comercial. Observa qué páginas se citan, qué pasajes aparecen en la respuesta y si tu marca aparece en subconsultas de fan-out centradas en la competencia, porque a veces es así. El Modo IA genera una media de 3,3 menciones de entidades por respuesta, frente a 1,3 para las Perspectivas Generales de la IA. Tu marca puede estar presente en sesiones en las que nunca se hace clic en tu dominio.
El volumen de búsqueda de marca como señal descendente. Si el Modo IA está generando conciencia de marca sin impulsar los clics directos -lo que la arquitectura sugiere que hace cada vez más-, el volumen de búsqueda de marca debería moverse como un indicador rezagado a lo largo de una ventana de 60-90 días.
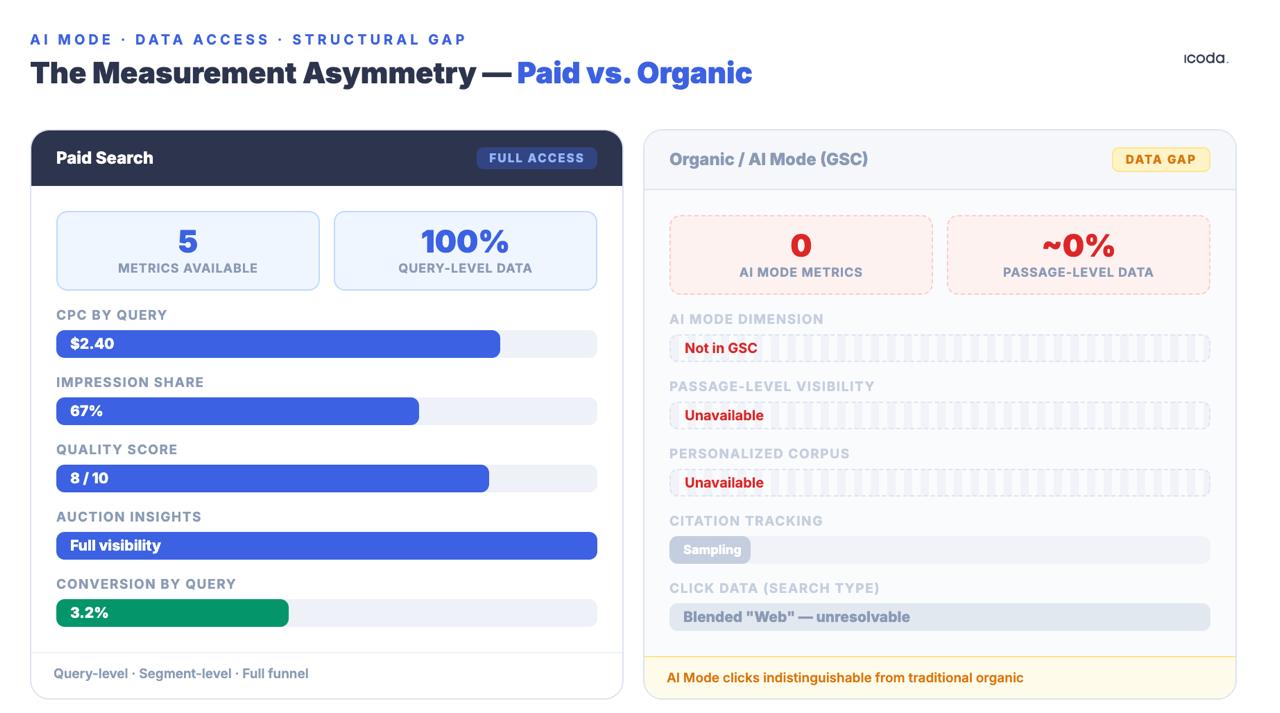
La brecha de medición entre la búsqueda de pago y la orgánica existe desde hace años. El modo IA lo ha ampliado hasta convertirlo en un abismo estructural.
Ninguno de ellos es perfecto. La asimetría con los equipos de búsqueda de pago es estructural y significativa: los equipos de pago tienen datos de CPC, cuota de impresiones, puntuaciones de calidad y conocimientos de subastas a nivel de consulta. Los equipos orgánicos obtienen datos de GSC que están deliberadamente agregados, muestreados y anonimizados, y los clics de AI Mode se mezclan en el tipo de búsqueda genérica "Web", indistinguible del tráfico orgánico tradicional. Esta brecha no es un problema temporal de herramientas. Es una decisión deliberada de arquitectura del producto, y se está ampliando a medida que el Modo IA hace que la recuperación orgánica sea más opaca, no menos.
La respuesta honesta es que actualmente no puedes medir con precisión la visibilidad de tu Modo IA. Puedes medir los proxies. Puedes rastrear la presencia de marca. Puedes observar cómo se deteriora la relación impresión/clic en tiempo real y utilizarla para establecer prioridades. Pero no debes confundir la medición de proxies con la verdad sobre el terreno, y debes dejar de pretender que un rastreador de rangos dirigido a una consulta no contextualizada te dice algo significativo sobre cómo un usuario real, conectado y contextualizado experimenta tu contenido dentro del Modo IA.
Conclusión clave: Los vectores de incrustación del usuario modifican la recuperación del Modo AI antes de que se apliquen las señales de clasificación clásicas, lo que convierte el seguimiento de la clasificación -tal como se practica actualmente- en una medición de un usuario que no existe. Cambia la medición primaria de la posición a la cuota de voz de la marca en las respuestas de la IA, complementada con señales de desacoplamiento del SGC y auditorías manuales de citas.
Conclusión
El Modo IA no es una Búsqueda Clásica más inteligente. Es un sistema de recuperación independiente -seis etapas, a nivel de pasaje, personalizado antes de que se aplique ninguna señal de clasificación- y ya está decidiendo qué marcas existen en las respuestas que está leyendo tu audiencia.
La superposición del 14% de citas con los resultados tradicionales del top-10 lo dice todo: la clasificación y las citas son ahora variables independientes. Puedes ser el dueño de la página uno y ser invisible en el Modo IA. Puedes estar en la posición 47 y obtener citas constantes si tu contenido produce pasajes que ganan comparaciones LLM por pares para las variantes de subconsulta adecuadas.
La arquitectura está documentada. Las patentes son públicas. La ventana para adaptarse antes de que el Modo IA se convierta en la experiencia de búsqueda por defecto se mide en trimestres, no en años.
Lo que ocurra a continuación es una elección.
Compartir


Valora el artículo












