Il problema di tutto ciò che hai letto finora
La maggior parte della copertura della modalità AI cade in una delle due modalità di fallimento. La prima è il giornalismo di prodotto senza fiato che descrive le funzionalità senza spiegare la macchina sottostante. La seconda è costituita da articoli rassicuranti di professionisti che hanno assorbito i punti di vista di Google e li hanno trasmessi: "la SEO standard è tutto ciò che serve", "i contenuti di qualità vincono", "nulla è cambiato in modo sostanziale".
Entrambe le cose sono sbagliate e costeranno ai marchi.
Questo articolo va al di là del marketing. Si basa sui brevetti depositati da Google, su studi quantitativi verificati e su alcune scoperte che la comunità più ampia non ha preso sul serio. L’obiettivo è semplice: alla fine dovrai capire esattamente come funziona l’AI Mode, perché infrange la tradizionale ortodossia SEO e cosa fare al riguardo.
Ci occuperemo di molte cose. Inizia con la cosa più importante, che quasi tutti hanno sbagliato.
Cos’è in realtà la modalità AI (e cosa non lo è)
Ecco l’idea sbagliata più costosa nel tuo settore in questo momento: che la modalità AI sia una versione più intelligente di qualcosa che già conosci.
In realtà, non è così. E il fatto di confonderlo con sistemi già noti ha causato veri e propri errori strategici: i brand che ottimizzano la visibilità di AI Overviews dando per scontato che si trasferisca, i team SEO che citano il comportamento di ChatGPT come analogo, i professionisti che trattano la modalità AI come un Featured Snippet più sofisticato. Questi sono errori di categoria. Portano a decisioni di investimento sbagliate e a quadri di misurazione errati.
Quindi cerchiamo di essere chirurgici sulla tassonomia.
Ricerca classica
Un sistema di recupero di documenti. Tu inserisci una query e lui ti restituisce un elenco di URL classificati. Il lavoro di Google termina con la SERP. Quello che fai con i link blu è affar tuo. Il gioco dell’ottimizzazione in questo caso è stabile da vent’anni: segnalare l’autorità al crawler, soddisfare l’intento delle parole chiave, ottenere segnali di coinvolgimento. Conosci questo sistema.
Panoramica sull’AI (AIO)
Un livello generativo aggiunto alla ricerca classica. AIO prende i risultati di ricerca esistenti di Google e li sintetizza in un paragrafo riassuntivo, attingendo quasi interamente dalle pagine già in cima alla classifica: il 76,1% delle citazioni di AI Overview proviene dai primi 10 risultati. Si tratta di una funzione dell’interfaccia utente, non di un nuovo sistema di ricerca. Consideralo come uno snippet intelligente con un modello linguistico che scrive il testo. L’indice sottostante è invariato; i segnali di ranking sottostanti sono invariati. Il SEO classico, applicato bene, è ampiamente sufficiente per l’idoneità AIO.
SGE (Search Generative Experience)
Morto. L’esperimento dei Laboratori è durato fino al 2023-2024. Smetti di fare riferimento a questo sistema come a un sistema vivo.
Gemelli (standalone)
Un assistente LLM. Nessuna connessione persistente all’indice di ricerca live di Google. Nessuna integrazione del Knowledge Graph. Nessun Shopping Graph. Le sue risposte provengono da dati di formazione, non da ricerche in tempo reale. Una pipeline di inferenza completamente diversa da tutto il resto di questo elenco.
Ricerca Perplexity e ChatGPT
Sistemi di generazione aumentata del recupero (RAG) che attingono da indici web pubblici e sintetizzano le risposte. Perplexity utilizza un crawl in tempo reale; ChatGPT recupera il contenuto completo dell’URL in fase di esecuzione attraverso l’API di Bing. Il loro reperimento è relativamente semplice: nessun modello utente persistente, nessuna infrastruttura di conoscenza multi-tier, nessun contesto statico tra le sessioni.
Modalità AI
Nessuna delle precedenti.
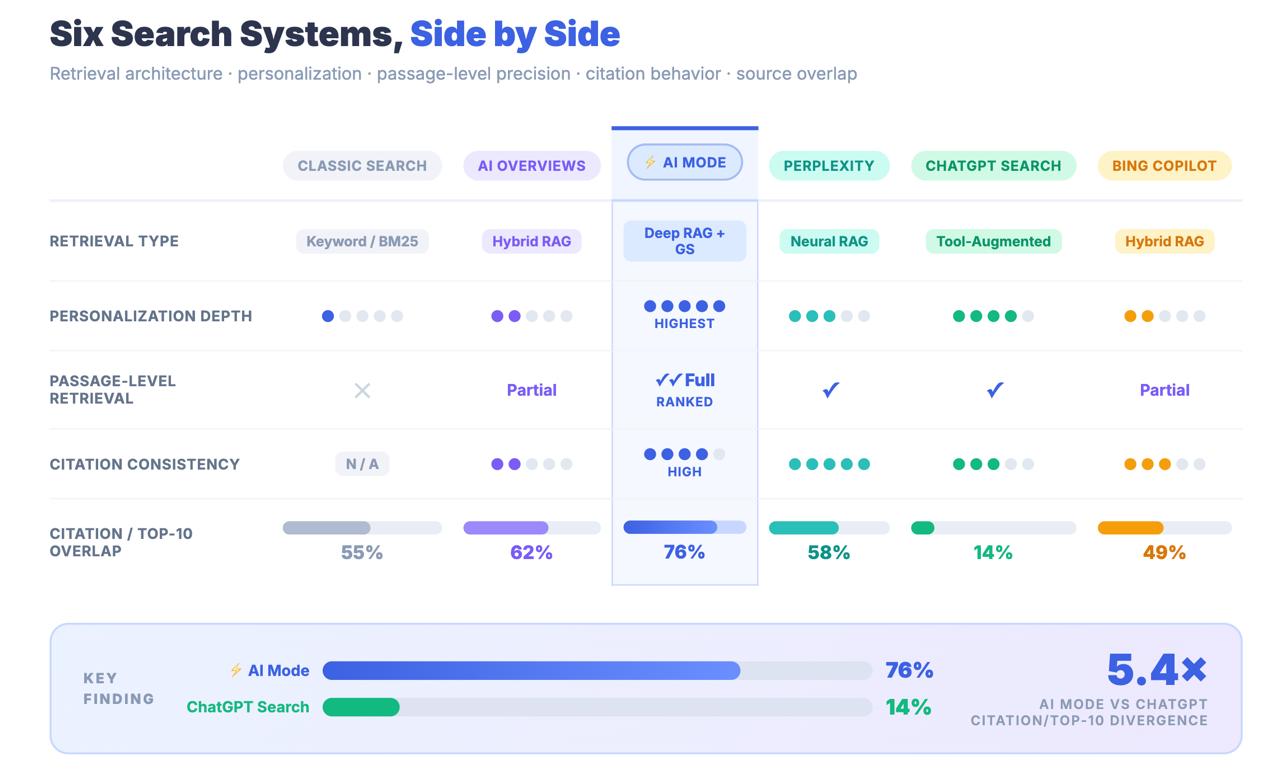
AI Mode è un motore di recupero e sintesi a più stadi, statico, personalizzato e a livello di passaggio, che esegue più sotto-query parallele sull’intera infrastruttura di conoscenza di Google (indice di ricerca, Knowledge Graph, Shopping Graph (oltre 50B prodotti) e Maps), assembla un corpus personalizzato di passaggi recuperati, li ri-classifica utilizzando un LLM a coppie e genera una risposta con verifica delle citazioni a livello di frammento.
Non si tratta di un involucro attorno alla Ricerca Classica. È un sistema di ricerca parallelo che vive all’interno dello stesso prodotto. E il numero che ti dovrebbe far perdere le speranze:
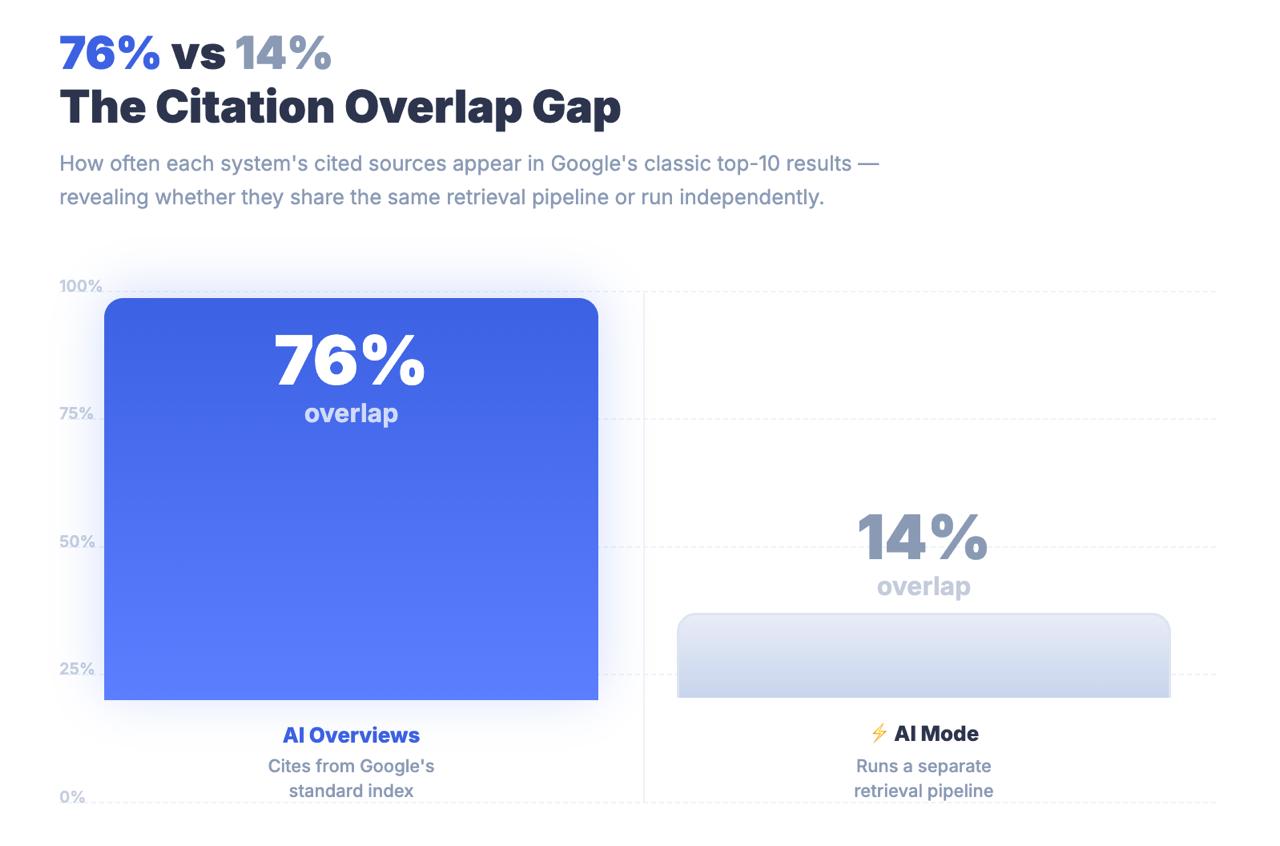
Solo il 14% degli URL citati da AI Mode rientra nella tradizionale top 10 di Google.
Per le panoramiche sull’intelligenza artificiale, la percentuale è del 76%. Il divario tra queste due cifre non è un errore di arrotondamento. È un dato architettonico che indica che l’AI Mode non sta trovando i contenuti attraverso i classici segnali di ranking. Sta trovando i contenuti attraverso una pipeline di reperimento completamente diversa e le strategie di ottimizzazione che ti hanno portato alla prima pagina possono essere in gran parte irrilevanti per la possibilità di essere citati.
Essere sulla prima pagina di Google è necessario per la visibilità dell’AI Overview; per l’AI Mode è in gran parte irrilevante.
I sistemi sono collegati come lo sono una biblioteca e un assistente di ricerca. Entrambi si occupano di libri. Uno ti consegna uno scaffale classificato. L’altro legge i libri per te, sintetizza le risposte e decide quali passaggi vale la pena citare. Il tuo lavoro è fondamentalmente diverso a seconda di quale delle due funzioni stai ottimizzando e, al momento, la maggior parte dei team sta ottimizzando per lo scaffale quando l’assistente di ricerca è ciò che il pubblico utilizza.
Aspetto fondamentale: AI Mode condivide un marchio con Google Search e un URL con AI Overviews, ma è un sistema di ricerca strutturalmente distinto. Solo il 14% delle citazioni di AI Mode proviene dai risultati tradizionali della top-10, rispetto al 76% di AI Overviews. Trattare AI Mode come un’estensione di AIO è un errore di misurazione con conseguenze strategiche reali.
L’architettura: Come una domanda diventa una risposta
La maggior parte delle spiegazioni sull’AI Mode descrivono ciò che fa dall’esterno: "capisce meglio la tua domanda", "sintetizza più fonti", "fornisce risposte conversazionali". Queste descrizioni non sono sbagliate. Ma sono inutili ai fini dell’ottimizzazione.
Di seguito è riportata la pipeline completa, denominata componente per componente, con i brevetti che regolano ogni fase. Questo è il vero significato di ottimizzazione per gli obiettivi, perché non è possibile migliorare sistematicamente un sistema a cui non si può dare un nome.
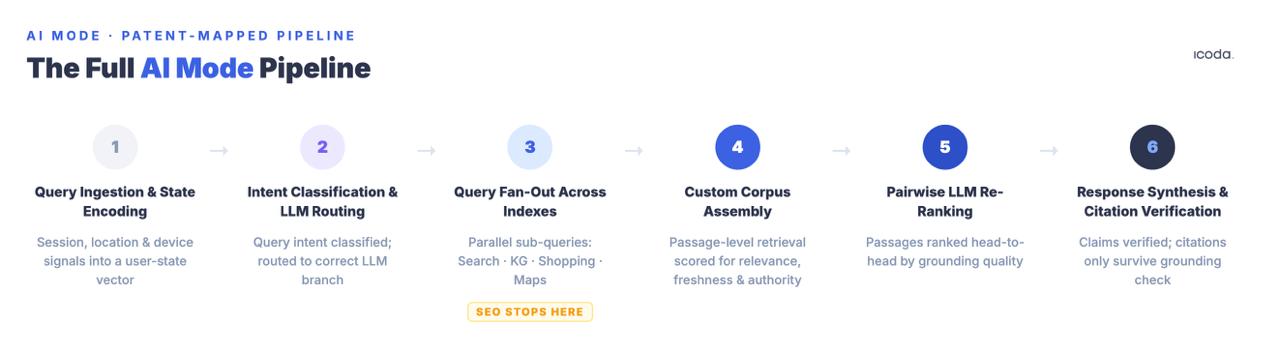
La pipeline a sei fasi è ciò che devi effettivamente ottimizzare. La maggior parte delle pratiche correnti si occupa di una sola fase.
Fase 1: Ingestione delle query e codifica dello stato dell’utente
La query grezza non viene recuperata direttamente. Viene prima abbinata al vettore di contesto statico dell’utente - un denso insieme costruito a partire dalla cronologia delle sessioni, dalle query precedenti in tutte le sessioni, dal dispositivo, dalla posizione, dall’ora del giorno e dai segnali dell’ecosistema Google (Ricerca, Mappe, Gmail, YouTube). Questo vettore di personalizzazione modifica il significato di "questa query" prima che inizi il recupero.
Due utenti che digitano query identiche stanno effettivamente inviando istruzioni di recupero diverse. Le implicazioni di questo fenomeno sono abbastanza significative da meritare una sezione a sé stante, che viene subito dopo questa.
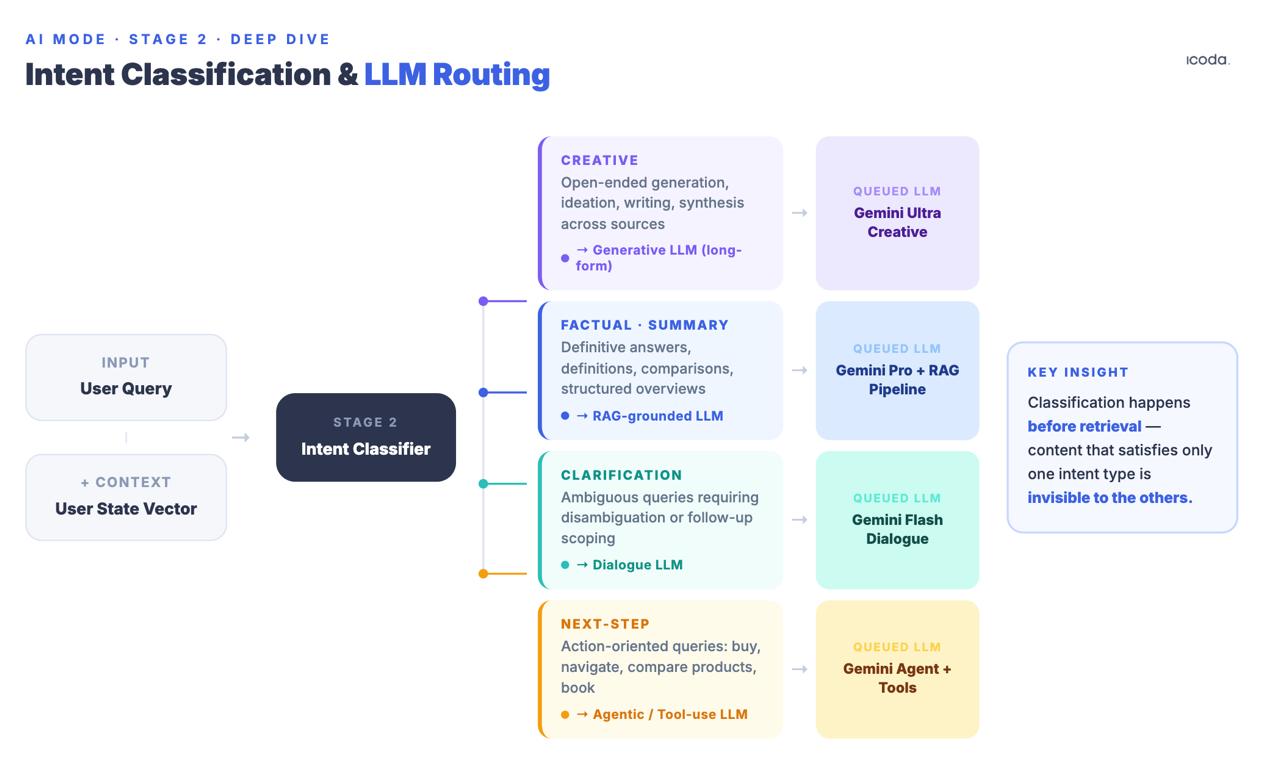
Fase 2: Classificazione dell’intento della richiesta e instradamento LLM
Prima del recupero, il sistema classifica la query in categorie di intenti: creativo, fattuale/riassuntivo, chiarimento o passo successivo/compito. In base a questa classificazione, vengono accodati diversi modelli linguistici a valle. Il brevetto della chat stateful (US20240289407A1) li nomina esplicitamente: Creative Text LLM, SRP Generative LLM, Clarification LLM, Next Step LLM.
Questo avviene prima del recupero. La classificazione determina non solo quale modello sintetizza la risposta, ma anche quali segnali di recupero sono più importanti. Una pagina che si classifica bene per le query informative potrebbe non entrare affatto nel pool dei candidati se il classificatore di intenti indirizza la sessione a un LLM che ottimizza il completamento del compito piuttosto che la sintesi delle informazioni.
Fase 3: Query Fan-Out
Questo è il punto in cui la modalità AI si discosta maggiormente da tutti i sistemi che l’hanno preceduta.
Il sistema genera molteplici sotto-richieste sintetiche a partire dall’originale, coprendo otto tipi di varianti documentate: equivalente, correlata, implicita, comparativa, chiarificatrice, temporale, geografica e di contesto professionale. Da notare la data di deposito. Google costruisce fan-out multi-query da sette anni. AI Mode è il prodotto finale di un lungo percorso architettonico.
I tipi di varianti "implicite" e "comparative" meritano un’attenzione particolare perché generano query che l’utente non ha chiesto ma di cui probabilmente ha bisogno. Se qualcuno cerca "il miglior CRM per le startup", il fan-out genera non solo riformulazioni ma anche query implicite ("quale CRM è in grado di superare la Serie A?"), query comparative ("Salesforce vs. HubSpot per le aziende in fase iniziale"), query temporali ("i prezzi del CRM cambiano nel 2025″) e varianti di contesto professionale che distinguono un fondatore che fa ricerche da un manager RevOps che decide.
Tutte le sotto-query vengono eseguite contemporaneamente nell’indice di ricerca di Google, nel Knowledge Graph, nello Shopping Graph e nelle Mappe. Google ha confermato che la modalità AI può eseguire "centinaia di ricerche" per una singola query complessa. Il brevetto sulla ricerca tematica (US12158907B1) organizza i risultati in cluster semantici; i sottotemi attivano ulteriori cicli di ricerca in modo iterativo, il che significa che la ricerca a ventaglio può ripetersi, non solo scoppiare una volta.
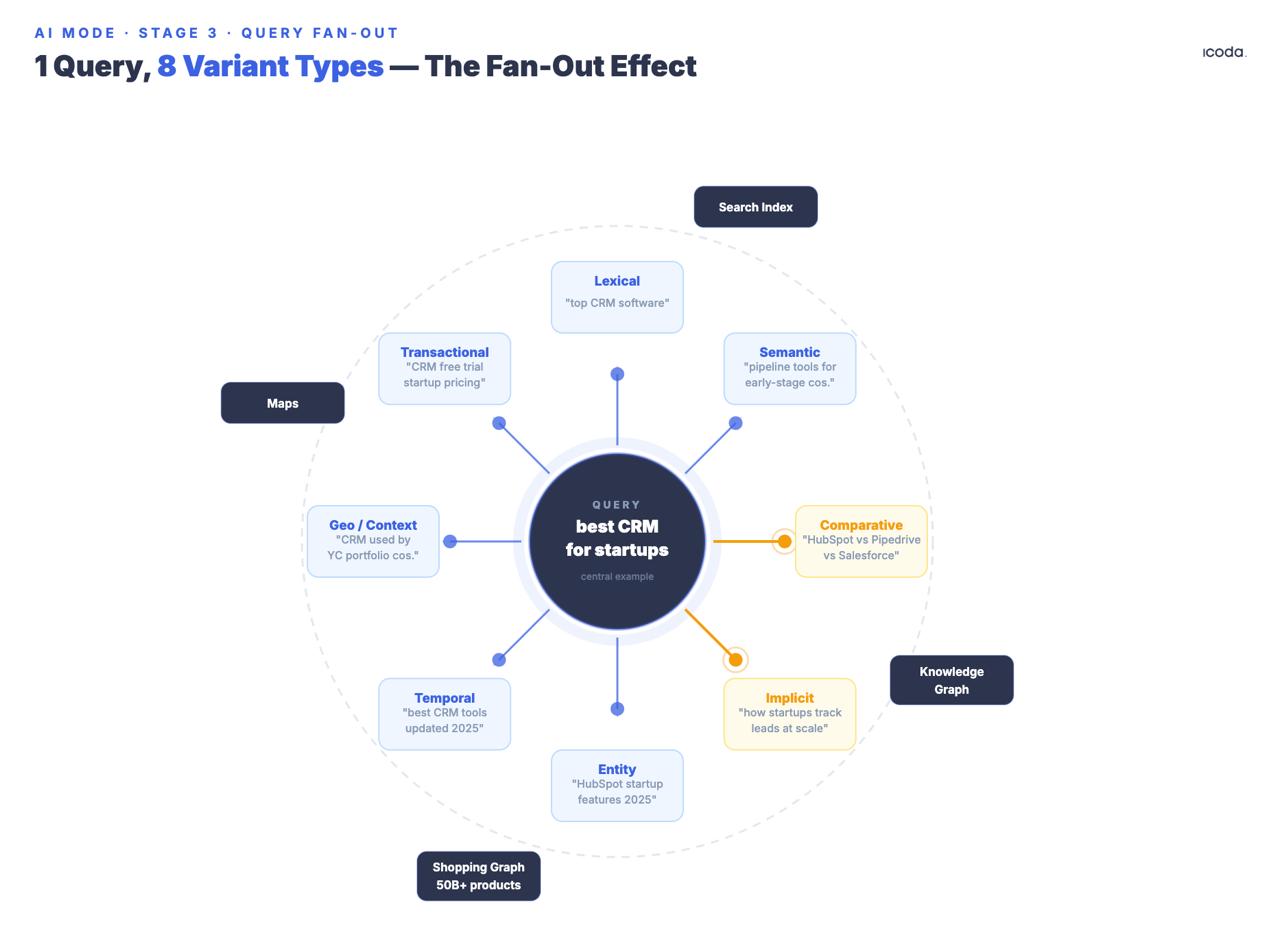
Google ha depositato il brevetto fondamentale del fan-out nel 2018 - AI Mode è il prodotto di consumo di una costruzione architettonica durata sette anni.
Un marchio che ha contenuti autorevoli sul "miglior CRM", ma nulla di comparativo, nulla di temporale e nulla di mirato alle varianti del contesto professionale, è assente da più tipi di query che si attivano in ogni sessione pertinente. Al fan-out non interessa l’autorità del tuo dominio: gli interessa che ogni sotto-query di variante faccia emergere un passaggio che vinca il confronto a coppie.
Fase 4: Assemblaggio del corpus personalizzato
I passaggi recuperati - non documenti, passaggi - vengono assemblati in un corpus personalizzato. Il brevetto WO2024064249A1 descrive come il sistema possa recuperare fino a cinque brani adiacenti intorno a un passaggio rilevante per preservare la coerenza contestuale. Ciò significa che il flusso della prosa in una sezione del documento è importante. Un’argomentazione ben strutturata che ottiene un risultato positivo nel recupero, trascina con sé i paragrafi circostanti nel corpus.
Il corpus è personalizzato. Ogni utente, ogni sessione, ogni query ne produce uno diverso. Non esiste un pool universale di documenti in cui i tuoi contenuti competono: ci sono milioni di pool specifici per ogni utente che vengono assemblati su richiesta.
Fase 5: Riclassificazione LLM a coppie
I passaggi di tutte le sottoquery a ventaglio competono tra loro. Il meccanismo di classificazione non è BM25. Non è TF-IDF. Un LLM confronta i passaggi a coppie - quale passaggio soddisfa meglio una determinata sotto-query? - in più turni di confronto. I vincitori avanzano, i perdenti escono.
Questa è la fase in cui la maggior parte degli investimenti SEO non riesce ad entrare in contatto. I passaggi densi, diretti e fattuali che rispondono a specifiche sotto-domande nella prima frase vincono nettamente i confronti a coppie. I contenuti narrativi, discorsivi e ricchi di opinioni - il tipo di contenuti che funzionano bene nella SEO editoriale a lungo termine - tendono a perdere, perché fanno lavorare più duramente un LLM per estrarre l’affermazione pertinente. Un thread su Reddit che si apre con una risposta diretta a una domanda di nicchia può superare una guida autorevole di 3.000 parole che seppellisce la risposta nel paragrafo otto. Il meccanismo a coppie premia il guadagno immediato, non la credibilità accumulata.
Fase 6: Sintesi delle risposte e verifica delle citazioni
I passaggi superstiti vengono inviati a Gemini. Gemini genera una risposta in linguaggio naturale. Poi il Response Linkifying Engine esegue una verifica a livello di frammenti: confronta ogni frammento della risposta generata con specifici passaggi del corpus e inserisce le citazioni in linea.
Non si tratta di un’attribuzione a livello di pagina. Una frase della risposta che corrisponde a un passaggio del tuo blog vale come citazione. Il resto della pagina potrebbe non essere citato affatto. Un articolo di 400 parole denso di fatti può superare una guida autorevole di 3.000 parole, perché produce più frammenti verificabili per unità di testo. Il meccanismo premia strutturalmente la densità delle affermazioni rispetto alla completezza della trattazione. Si tratta di un’inversione diretta di ciò che la SEO tradizionale ottimizza per le forme lunghe.
Aspetto fondamentale: La modalità AI è una pipeline a sei fasi. Il SEO tradizionale si occupa principalmente della fase 3 (idoneità al recupero). Le citazioni si vincono o si perdono nelle fasi 4-6 - densità a livello di passaggio, competizione a coppie LLM e fondamento fattuale a livello di frammento - nessuna delle quali viene affrontata dalle pratiche di ottimizzazione standard.
Il livello di personalizzazione: Perché il Rank Tracking sta misurando una finzione
C’è un fatto incorporato nell’architettura dell’AI Mode che il settore SEO non ha ancora preso in considerazione. Diciamolo chiaramente:
La stessa query emessa da due utenti diversi produce set di recupero diversi. Non classifiche diverse degli stessi documenti. Documenti completamente diversi.
Il brevetto User Embedding Models descrive il modo in cui Google codifica i segnali comportamentali - query, clic, tempo di permanenza, cronologia della posizione, attività di Maps, cronologia di YouTube, contenuti di Gmail - in vettori densi che vengono abbinati a ogni query in arrivo. Il vettore di personalizzazione modifica il recupero prima che venga applicato un segnale di ranking tradizionale.
Non si tratta di una gara contro i concorrenti per ottenere una posizione universale in classifica. Si tratta di una gara di rilevanza all’interno di specifici contesti di query dell’utente-persona che non puoi osservare direttamente, non puoi misurare direttamente e non puoi replicare in uno strumento di monitoraggio del ranking.
Cosa alimenta l’utente Embedding
Il brevetto Stateful Chat (US20240289407A1) e il brevetto User Embedding Models descrivono insieme uno stack di personalizzazione che attinge da:
- Cronologia completa delle query in tutte le sessioni di ricerca di Google (per gli utenti che hanno effettuato il login)
- Modelli di click, hover e dwell a scala comportamentale aggregata
- Tipo di dispositivo e segnali di posizione
- Dati dell’ecosistema Google: Check-in di Maps, tempo di visione di YouTube per argomento, contenuti di Gmail
Vale la pena soffermarsi su quest’ultima categoria. La funzione "Personal Context", presentata in anteprima al Google I/O 2025 e in fase di implementazione parziale a partire dall’inizio del 2026, incorporerà esplicitamente i dati di Gmail, Calendario e account Google direttamente nel reperimento. Quando sarà completamente lanciata, un utente che ha inviato un’email per una gita sugli sci la scorsa settimana riceverà risposte diverse dall’AI Mode per "attrezzatura invernale per esterni" rispetto a chi ha recentemente acquistato scarpe da corsa su Google Shopping. Il concetto di risultato di ricerca canonico per qualsiasi query sarà funzionalmente morto. Ogni risultato sarà il prodotto della storia comportamentale dell’utente nell’intero ecosistema Google, non solo delle sue ricerche.
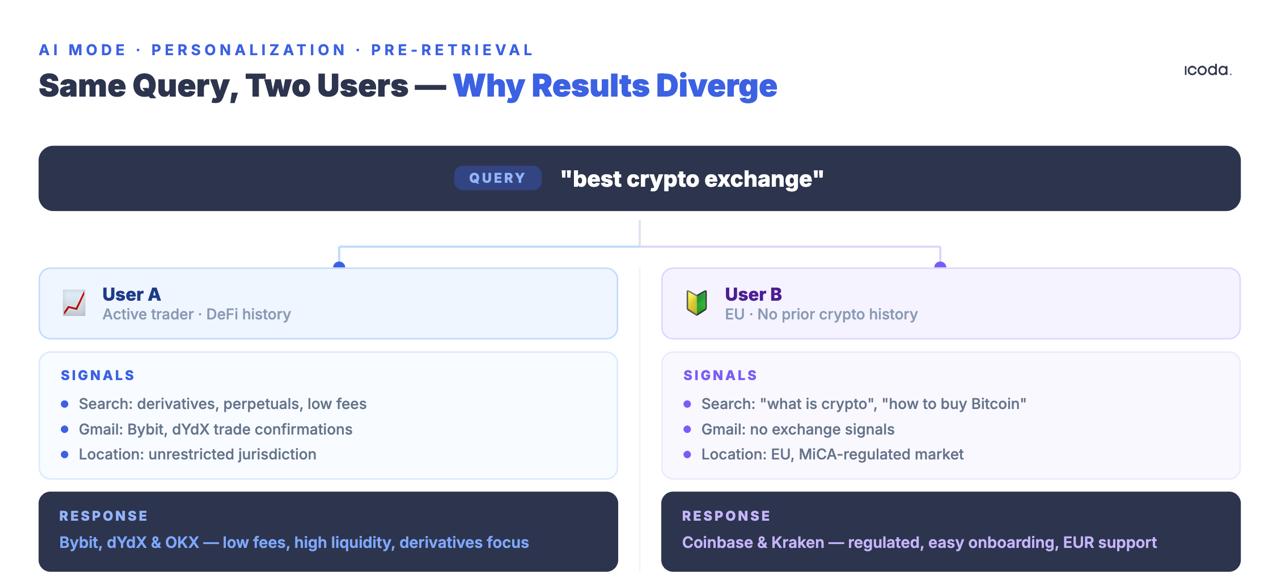
La conseguenza della misurazione
Gli strumenti di tracciamento delle classifiche interrogano ambienti puliti e non contestualizzati. Gli utenti reali sono profondamente contestualizzati. Lo strumento misura una posizione ipotetica che nessun utente reale vede.
Non si tratta di un reclamo di precisione. È un reclamo di validità. La misurazione non è imprecisa: sta misurando una cosa completamente sbagliata. Un numero di tracciamento della posizione di un tracker di posizione che si confronta con la modalità AI rappresenta l’esperienza di un utente senza cronologia di ricerca, senza segnale di posizione, senza dati dell’ecosistema e senza contesto di sessione. Quell’utente non esiste in nessun volume significativo.
La sentenza dell’antitrust sottolinea questo punto in modo ironico. Il rimedio del dicembre 2025 prevede che Google condivida il suo indice di ricerca con i concorrenti per due volte nell’arco di cinque anni. Ma non può condividere i modelli di incorporazione degli utenti. I dati dell’indice - che ora stanno diventando una merce - non sono il motore della personalizzazione della modalità AI. È il volano dell’apprendimento: 14 miliardi di query giornaliere, che alimentano continuamente le integrazioni degli utenti aggiornate che nessun concorrente può replicare. I concorrenti ottengono un’istantanea dello scaffale. Google conserva il bibliotecario che ha letto il volto di ogni cliente.
Cosa funziona davvero per la misurazione
I marchi meglio posizionati per affrontare questa situazione non sono quelli che hanno il monitoraggio del ranking con la più alta fedeltà. Sono quelli che hanno accettato il fatto che il reperimento personalizzato dell’intelligenza artificiale richiede un paradigma di misurazione diverso e si sono orientati verso di esso. Le quattro proxy che hanno un segnale reale:
Quota di voce del marchio nelle risposte dell’AI, monitorata tramite strumenti di terze parti (Profound, ZipTie, Ahrefs Brand Radar). Si tratta di approssimazioni basate sul campionamento, non di una copertura completa - ma misurano la presenza di citazioni, che è la variabile di output corretta. Tieni traccia di questo dato rispetto ai concorrenti, non rispetto a un punteggio assoluto.
Disaccoppiamento impressioni/click GSC a livello di segmento di query. Le query informative che mostrano impressioni in aumento e CTR in calo sono la principale firma visibile della cannibalizzazione della modalità AI. Segmenta per tipo di intento e osserva la divergenza che si accentua nel tempo.
Audit citazionale manuale in modalità AI per le tue 20 query più importanti dal punto di vista commerciale. Nota quali pagine sono citate, quali passaggi compaiono nella risposta e se il tuo marchio compare nelle sotto-query di fan-out della concorrenza, perché a volte è così. La modalità AI genera in media 3,3 menzioni di entità per risposta, contro le 1,3 delle panoramiche AI. Il tuo marchio potrebbe essere presente in sessioni in cui il tuo dominio non viene mai cliccato.
Il volume di ricerca del marchio come segnale a valle. Se l’AI Mode sta generando brand awareness senza generare click diretti - e l’architettura suggerisce che lo fa sempre più spesso - il volume di ricerca brandizzato dovrebbe muoversi come indicatore ritardato nell’arco di 60-90 giorni.
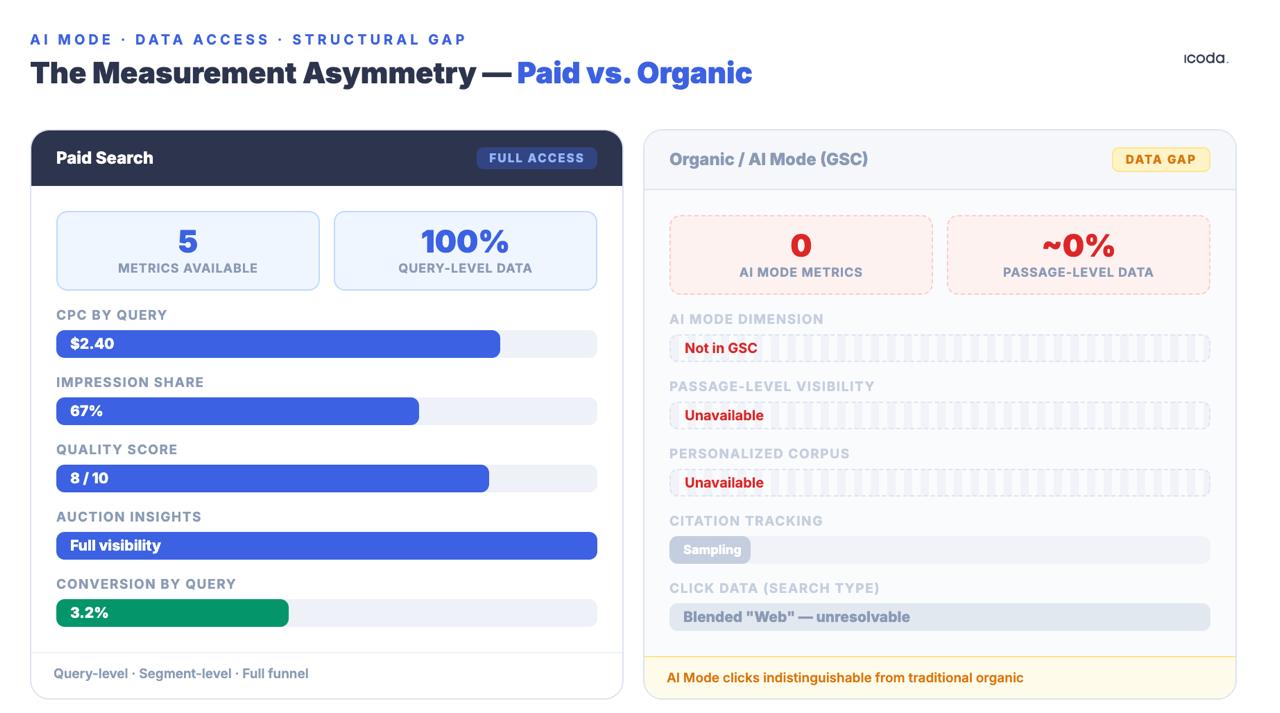
Il divario di misurazione tra la ricerca a pagamento e quella organica esiste da anni. L’AI Mode lo ha ampliato fino a farlo diventare un abisso strutturale.
Nessuno di questi è perfetto. L’asimmetria con i team di ricerca a pagamento è strutturale e significativa: i team a pagamento dispongono di dati CPC, impression share, punteggi di qualità e informazioni sulle aste a livello di query. I team che si occupano di ricerca organica ottengono dati GSC che sono deliberatamente aggregati, campionati e resi anonimi - e i clic di AI Mode sono mescolati nella tipologia di ricerca generica "Web", indistinguibile dal traffico organico tradizionale. Questa lacuna non è un problema temporaneo di strumenti. Si tratta di una decisione deliberata dell’architettura del prodotto e si sta ampliando man mano che AI Mode rende più opaca la ricerca organica, non meno.
La risposta onesta è che attualmente non è possibile misurare con precisione la visibilità della modalità AI. Puoi misurare i proxy. Puoi monitorare la presenza del marchio. Puoi osservare il deterioramento del rapporto impressioni/click in tempo reale e usarlo per stabilire le priorità. Ma non devi confondere la misurazione dei proxy con la verità di base e devi smettere di fingere che un rank tracker puntato su una query non contestualizzata ti dica qualcosa di significativo su come un utente reale, connesso e contestualizzato vive i tuoi contenuti all’interno dell’AI Mode.
Aspetto fondamentale: I vettori di incorporazione dell’utente modificano il recupero dell’AI Mode prima che si applichino i classici segnali di ranking, rendendo il monitoraggio del rank - come attualmente praticato - una misurazione di un utente che non esiste. Spostare la misurazione primaria dalla posizione alla quota di voce del marchio nelle risposte dell’AI, integrata dai segnali di disaccoppiamento GSC e dalle verifiche manuali delle citazioni.
Conclusione
La modalità AI non è una ricerca classica più intelligente. Si tratta di un sistema di recupero separato - sei fasi, livello di passaggio, personalizzato prima di applicare qualsiasi segnale di ranking - e sta già decidendo quali marchi esistono nelle risposte che il tuo pubblico sta leggendo.
Il 14% di sovrapposizione di citazioni con i risultati tradizionali della top-10 ti dice tutto: ranking e citazioni sono ora variabili indipendenti. Puoi occupare la prima pagina ed essere invisibile in modalità AI. Puoi occupare la posizione 47 e guadagnare citazioni consistenti se i tuoi contenuti producono passaggi che vincono i confronti LLM a coppie per le giuste varianti di sotto-query.
L’architettura è documentata. I brevetti sono pubblici. La finestra per adattarsi prima che la modalità AI diventi l’esperienza di ricerca predefinita si misura in trimestri, non in anni.
Quello che succede dopo è una scelta.
Condividi


Valuta l'articolo











