Когда Google внедрил AI-обзоры почти в половину всех результатов поиска, на стол каждого SEO-специалиста лег неудобный вопрос: если ответ находится на странице, зачем вообще щелкать по ней? Честный ответ заключается в том, что большинство пользователей этого не делают. Количество органических кликов падает на 61%, когда срабатывает AI-обзор. Но бренды, которые цитируются в этих резюме, сгенерированных искусственным интеллектом, получают на 35% больше органических кликов, чем те, которые не цитируются.
Этот промежуток - между обобщением и цитированием - теперь решает, куда направляется поисковый трафик. Чтобы понять, как оказаться на правильной стороне этого разрыва, мы изучили закономерности, зафиксированные в последних исследованиях AI-обзоров, и сравнили, какие источники цитируются, а какие обходят стороной. Полученные результаты противоречат нескольким распространенным предположениям о том, как появиться в SEO-планах обзоров AI SEO.
Из чего черпают информацию AI-обзоры (это не только рейтинг №1)
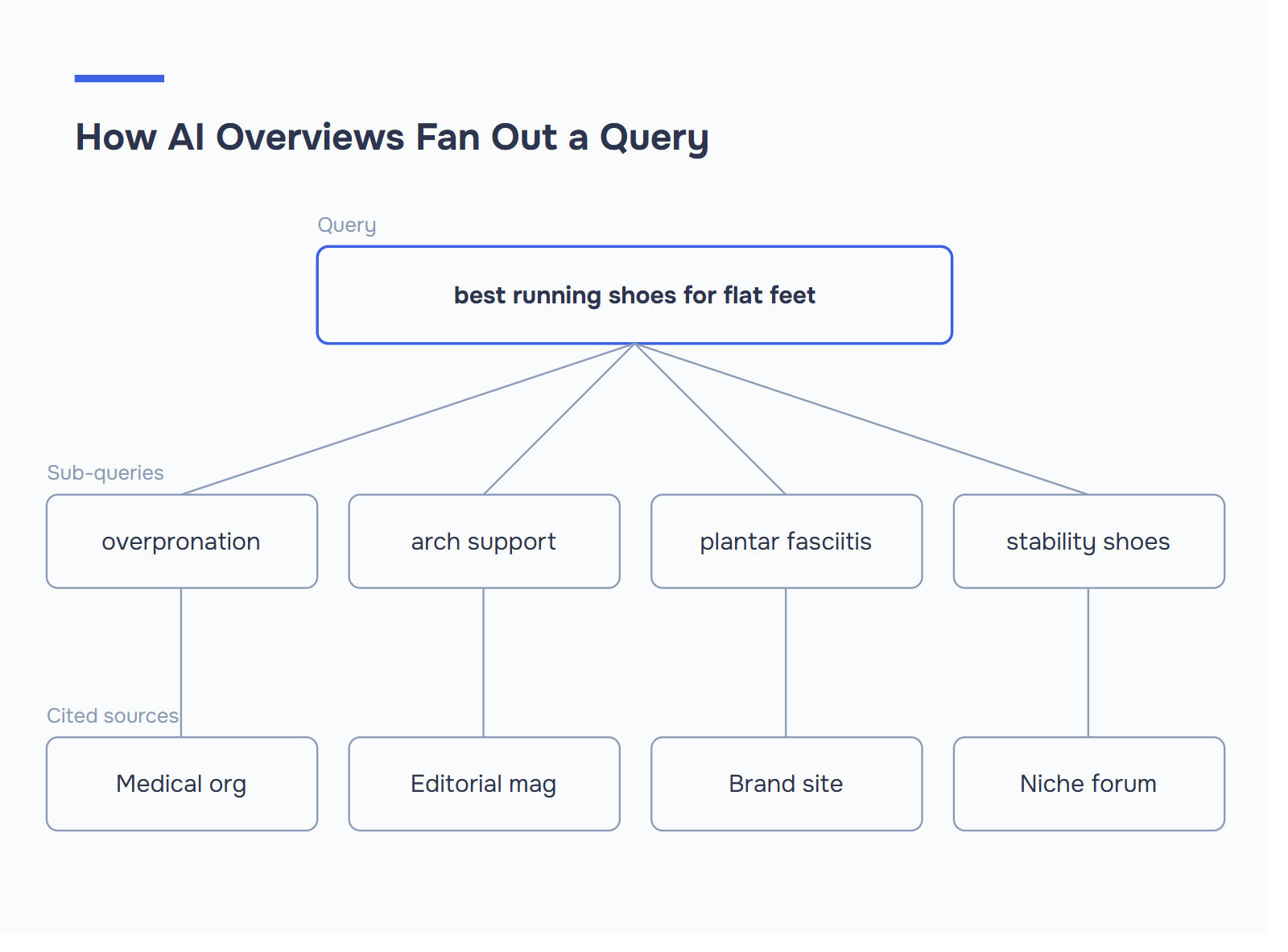
ИИ-обзоры не просто отбирают лучший органический результат. Они декомпозируют запрос на подвопросы, ищут каждый из них отдельно, а затем собирают цитаты из источников, которые лучше всего отвечают на каждый фрагмент - этот процесс Google называет веером запросов.
Ссылки, занимающие первую позицию, имеют около 53% шансов появиться в обзорах AI, в то время как ссылки, занимающие 10-ю позицию, снижаются примерно до 37%. Что еще более поразительно: более 99% ссылок в AI-обзорах приходятся на страницы, занимающие первые 10 мест в органических результатах, причем совпадение ссылок составляет около 94%. Таким образом, традиционный SEO все еще остается "полом". Просто это уже не потолок.
Среди всех моделей, которые мы рассмотрели, постоянно повторялись три вещи:
- Процитированная страница не всегда занимала самое высокое место. Страницы в позициях 3-8 попадали в обзоры, если их структура была чище, чем у результата №1. ИИ отдает предпочтение самому чистому отрывку, а не самому сильному домену.
- Маленькие сайты выигрывают у больших по целевым запросам. Маленькие бренды появлялись рядом с крупными компаниями, и во многих случаях выбранный источник не был страницей с самым высоким рейтингом.
- Подзапросы раскрывают нишевые цитаты. Широкий запрос о "рейтинге обзоров AI" может привести один источник для алгоритма, другой - для схемы, а третий - для отслеживания. Это и есть веер запросов в действии.
Практический вывод: перестаньте оптимизировать страницы как монолитные ответы. Оптимизируйте разделы - отрывки уровня H2, которые полностью решают по одному подвопросу.
Диагностика веерного выхода. Выберите целевое ключевое слово и запишите 3-5 подзапросов, на которые оно может разложиться. Например, "лучшие кроссовки для плоскостопия": кроссовки при гиперпронации, кроссовки с поддержкой свода стопы, кроссовки при плантарном фасциите, устойчивая и нейтральная обувь. Теперь просканируйте свою собственную страницу. Отвечает ли она на каждый подвопрос в самостоятельном отрывке с четким H2 или H3? Если два из пяти запросов отсутствуют - или похоронены в блоке из 400 слов - это тот случай, когда Вашего конкурента цитируют, а Вас нет.
Требования к формату контента: Структура - новый авторитет
Четкая структура выигрывает у плотности прозы при извлечении ИИ. Самым главным фактором, определяющим, сможет ли ИИ цитировать Ваш контент, является то, сможет ли он извлечь чистый блок ответов без двусмысленностей.
В цитируемых источниках преобладают три структурных паттерна:
- Самостоятельные отрывки с ответами. Исследование, проанализировавшее тысячи ссылок на обзоры ИИ, показывает, что ИИ отдает предпочтение отрывкам, которые полностью отвечают на запросы, состоящие из 130-170 слов. Отрывок, требующий контекста, начиная с трех абзацев, проиграет абзацу, который стоит особняком.
- Иерархическая архитектура H2/H3. На цитируемых страницах в подавляющем большинстве случаев используются H2 в стиле вопросов ("Что такое X?", "Как работает Y?"), за которыми следует прямой ответ в первых 1-2 предложениях. Эта схема настолько последовательна, что почти шаблонна.
- Списки, таблицы и пошаговые блоки. Плотные абзацы и отсутствующие заголовки затрудняют извлечение контента искусственным интеллектом. Четкие иерархические заголовки, короткие абзацы, маркированные списки и таблицы повышают удобство сканирования - как для людей, так и для моделей извлечения.
Вот что, согласно данным, составляет разницу между "рейтингом" и "цитированием":
| Элемент | Занимает высокие позиции, но не цитируется | Занимает высокие позиции и цитируется в обзорах по искусственному интеллекту |
|---|---|---|
| Вступительное предложение в разделе H2 | Устанавливает контекст | Прямой ответ на вопрос, вынесенный в заголовок |
| Длина абзаца | 150-300+ слов | 40-80 слов, по одной идее |
| Списки и таблицы | Редкие или декоративные | Используется для структурирования сравнений и шагов |
| Рубрики | Общие ("Обзор", "Преимущества") | Форма вопроса ("Как работает Х?") |
| Внутренние ссылки | "Как мы уже говорили выше…" | Каждый раздел стоит особняком |
| Мультимодальные элементы | Только текст | Текст + изображение + структурированные данные |

Страницы, сочетающие в себе текст, изображения, видео и структурированные данные, демонстрируют значительно более высокую вероятность выбора в многочисленных исследованиях AI Overview. Мультимодальный контент - это не украшение, а сигнал к цитированию.
Schema Markup That Helps: FAQPage, HowTo, Article
Разметка Schema больше не является "приятной мелочью". Это слой, который сообщает системам искусственного интеллекта, что на самом деле представляет собой Ваш контент. Три типа схем выполняют тяжелую работу по обеспечению соответствия требованиям AI Overview.

Схема FAQPage
Почему это работает: она предварительно формирует Ваш контент в виде пар "вопрос-ответ" - именно так системы искусственного интеллекта извлекают и представляют информацию. Когда Вы внедряете схему FAQPage, Вы прямо указываете платформам искусственного интеллекта, что такое вопрос, что такое авторитетный ответ и как эти элементы связаны между собой. Это снимает бремя интерпретации.
Совет по применению: для оптимального извлечения информации держите ответы в пределах 40-60 слов. Согласно независимым исследованиям, средний эффект от применения FAQPage в плане повышения уровня цитируемости AI составляет около 30%.
Минимальный блок выглядит следующим образом:
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "How do I get cited in Google AI Overviews?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Rank in the top 10 for the target query, use question-form H2s with direct-answer first sentences, and add FAQPage or HowTo schema that mirrors the visible content."
}
}]
}
Поместите его на страницу <head> в виде блока <script type="application/ld+json">, а затем проверьте с помощью теста Google Rich Results Test перед отправкой.
HowTo Schema
Почему она работает: она отображает пошаговые инструкции в последовательности, которую ИИ может мгновенно интерпретировать. В обзорах AI часто приводятся процедуры из 3-7 шагов, что делает этот тип схемы особенно ценным для технического контента.
Совет по внедрению: используйте пронумерованные шаги, а не заспамленные параграфы. Схема отражает то, что ИИ все равно собирается визуализировать - сделайте так, чтобы они совпадали.
Схема статьи (с указанием автора)
Почему это работает: это устанавливает, что контент является редакционным, прикрепляет сущность автора и соединяет с организацией. Схема Article идентифицирует тип контента; FAQPage позволяет извлекать вопросы и ответы; схема HowTo отображает пошаговые инструкции. Вместе они охватывают большую часть того, что может быть обнаружено в обзоре AI.
Совет по внедрению: всегда включайте author, datePublished, dateModified, и publisher. Страницы, не содержащие их, систематически лишаются приоритета.
Вместе эти три типа схем - разница между тем, чтобы быть упомянутым и быть невидимым. Одна оговорка: схема работает только тогда, когда она соответствует тому, что на самом деле находится на странице. Разметка часто задаваемых вопросов, которые не видны пользователям, приведет к тому, что Вас накажут, а не повысят.
Технические факторы: Скорость страницы, HTTPS, мобильность и удобство для просмотра.
Прежде чем любой сигнал будет иметь значение, краулер AI должен добраться до Вашей страницы. Это звучит очевидно. Но именно здесь удивительное количество сайтов тихо дисквалифицируют себя.
Если бот не может получить Ваш URL, ничто другое из этого списка не поможет. Страницы должны возвращать чистый код состояния 200, загружаться без стен аутентификации и оставаться доступными как во время тренировочного просмотра, так и в режиме реального времени.
Непременная техническая основа:
- HTTPS повсюду. Небезопасные страницы систематически лишаются приоритета на всех поверхностях ИИ.
- Перспективный для мобильных устройств рендеринг. Google индексирует мобильную версию. Если Ваш мобильный макет сворачивает таблицы или прячет часто задаваемые вопросы за тапом по расширению, ИИ видит свернутую версию.
- Показатели Core Web Vitals в зеленом цвете. LCP менее 2,5 с, INP менее 200 мс, CLS менее 0,1. Медленные страницы просматриваются реже и реже обновляются - а в обзорах AI, где свежесть имеет значение, менее частые просмотры означают несвежие цитаты.
- Серверный рендеринг HTML для критически важного содержимого. Если Ваши абзацы с ответами появляются только после увлажнения JavaScript, предположите, что некоторые краулеры их не увидят.
- Открытый доступ для гусениц. Большинство сайтов ошибаются именно в этом.
В 2026 году слово "доступный" означает доступный для дюжины различных пользовательских агентов. Чистый robots.txt, который явно приветствует ботов ИИ, теперь является базовым. Вот конфигурация, которая разрешает поисковое цитирование ИИ без разрешения на обучение модели:
# Allow AI search crawlers
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: ClaudeBot
Allow: /
# Disallow training-only crawlers (optional, based on policy)
User-agent: GPTBot
Disallow: /
User-agent: CCBot
Disallow: /
Perplexity уважает директивы robots.txt, и PerplexityBot не будет индексировать сайты, которые запрещены. Поэтому, если PerplexityBot заблокирован - случайно или иным образом - Вы будете невидимы для цитирования Perplexity.
Чего следует избегать: Тонкий контент, платные стены, противоречивая информация
AI-обзоры агрессивно отфильтровывают контент, которому нельзя доверять в плане полноты, последовательности или доступности. Несколько шаблонов исключают страницы:
- Тонкий контент. Страницы, которые только повторяют вопрос, не отвечая на него, или которые наполнены партнерским пухом, прежде чем перейти к сути, почти никогда не появляются в цитируемых источниках. Пост в 600 слов, который тратит 400 слов на фрейм "что такое X", прежде чем перейти к реальному ответу, проигрывает посту в 600 слов, который отвечает в первом абзаце.
- Платные стены и ворота для входа. Если краулер AI натыкается на стену аутентификации, страница считается недоступной. Мягкие платные стены (превью + CTA) - это нормально; жесткие платные стены дисквалифицируют Вас.
- Противоречивая информация по всему сайту. На Вашей главной странице написано "основан в 2018 году", в блоге - "мы существуем с 2017 года", на странице "О компании" - "более пяти лет". ИИ отдает приоритет всем трем словам. Согласованность сущностей - дат, заявлений и описаний продуктов - имеет большее значение, чем люди думают.
- Несвежий контент. Страницы, не обновляемые ежеквартально, примерно в 3 раза чаще теряют цитируемость. AI-обзоры предпочитают свежие сигналы.
- Отсутствие сигналов E-E-A-T. Система E-E-A-T от Google фактически стала фильтром ранжирования, а не просто рекомендацией по качеству. Страницы с высокими показателями E-E-A-T заметно лучше видны в результатах, генерируемых искусственным интеллектом.
- Неясное авторство. Страницы без авторского заголовка, биографии и ссылки на автора выглядят так, будто их мог создать кто угодно - включая, как ни странно, искусственный интеллект.
- Несоответствующая схема. Разметка контента, которого нет на странице, хуже, чем полное отсутствие схемы. Наиболее распространенный вариант: Схема FAQPage с вопросами и ответами, которые на самом деле не видны читателю нигде на странице. Rich Results Test отметит их, и вскоре после этого ссылки иссякнут.
Во всех этих случаях наблюдается закономерность: ИИ-обзоры приводят только то, что они могут проверить. Все, что создает двусмысленность, рассматривается как сигнал риска.
Мониторинг: Как отслеживать появление в обзорах ИИ
Вы не можете оптимизировать то, что не можете измерить - а отслеживание обзоров с помощью AI сложнее, чем традиционное отслеживание рангов. Данные разбросаны по Google Search Console, сторонним инструментам и ручным проверкам. Вот честная картина.
Google Search Console
GSC добавила частичную видимость, но с оговорками. Обновленный фильтр Search Appearance теперь включает специальные сегменты для AI Overviews и AI Mode запросов, позволяя Вам видеть показы, клики и CTR именно по этим форматам, созданным искусственным интеллектом, а не встраивать их в общие данные веб-поиска.
Чтобы найти его: Производительность → Результаты поиска → Фильтр "Внешний вид поиска" → "Обзор AI". Это даст Вам данные о показах, кликах, CTR и средней позиции по запросам, в которых Вы появились в AI Overview, отделенные от остальных данных поиска в Интернете.
На что обратить внимание:
- Соотношение впечатлений и кликов. Появление в AI-обзоре приводит к большому количеству показов, но значительно более низкому CTR, чем в традиционных объявлениях. Внезапный всплеск количества впечатлений при низком уровне кликов обычно означает, что AI Overview перехватывает трафик.
- CTR на уровне запросов падает. Запросы, по которым CTR упал, а впечатления остались прежними, скорее всего, теперь вызывают AI-обзоры над Вашим объявлением.
- Страницы с растущими впечатлениями от обзора AI. Это Ваши кандидаты на цитирование. Проверьте их структуру, схему и свежесть - именно здесь небольшие исправления дают наибольший эффект.
Инструменты сторонних производителей
Для отслеживания уровня цитирования (двоичного "процитировали меня или нет?") GSC недостаточно. Именно этот пробел призваны заполнить инструменты SEO AI Overviews - Semrush, Ahrefs и SISTRIX имеют функции для отслеживания того, когда и где появляются AI Overviews по определенным ключевым словам. Перекрестное сопоставление этих данных с данными GSC - лучший бесплатный способ оценить влияние.
Специальные платформы для создания видимости ИИ (Otterly, OmniSEO, Wellows и другие) идут дальше, напрямую опрашивая ИИ-двигатели и записывая, появляется ли Ваш домен в обзорах ИИ Google, Perplexity, ChatGPT Search и Gemini.
Ручные выборочные проверки
Наименее масштабируемый метод, но при этом самый надежный. Выберите 20-30 целевых запросов. Запустите их в Google AI Overviews, Perplexity, ChatGPT Search и Gemini. Запись:
- Ваш домен был процитирован?
- Какой именно URL?
- Какое место в списке цитирования?
- Какие ссылки конкурентов расположены рядом с Вашими?
Простая таблица Google с этими столбцами и датой - обновляемая ежемесячно - превосходит большинство платных инструментов для понимания Ваших реальных моделей цитирования. Вам нужна не одна неудачная неделя; Вам нужно понять, какие запросы Вы систематически пропускаете и какие конкуренты продолжают занимать Ваше место.
Полезная схема KPI
Отслеживайте эти четыре показателя:
- Коэффициент присутствия - % отслеживаемых запросов, в которых Вы появляетесь в качестве ссылки
- Позиция цитирования - Ваше место в списке цитирования (первый источник имеет наибольший вес)
- Количество срабатываний - % Ваших отслеживаемых запросов, по которым срабатывает AI-обзор.
- Перекрытие конкурентов - какие домены цитируются рядом с Вами, а какие занимают Ваше место
Проверьте, действительно ли Вы имеете на это право
Большинство советов по SEO, как появиться в обзорах AI SEO, сосредоточены на работе над контентом и структурой, которая развивается в течение нескольких месяцев. Основополагающий вопрос - могут ли боты вообще попасть на Ваши страницы? - уделяется гораздо меньше внимания. А ведь на него можно ответить за пять минут.
Если PerplexityBot, OAI-SearchBot или Google-Extended заблокированы на Вашем сайте robots.txt, то любая другая оптимизация в этом руководстве не имеет смысла. Ваш контент не индексируется, на него не ссылаются, и Вы невидимы для канала, который уже составляет почти половину поиска.
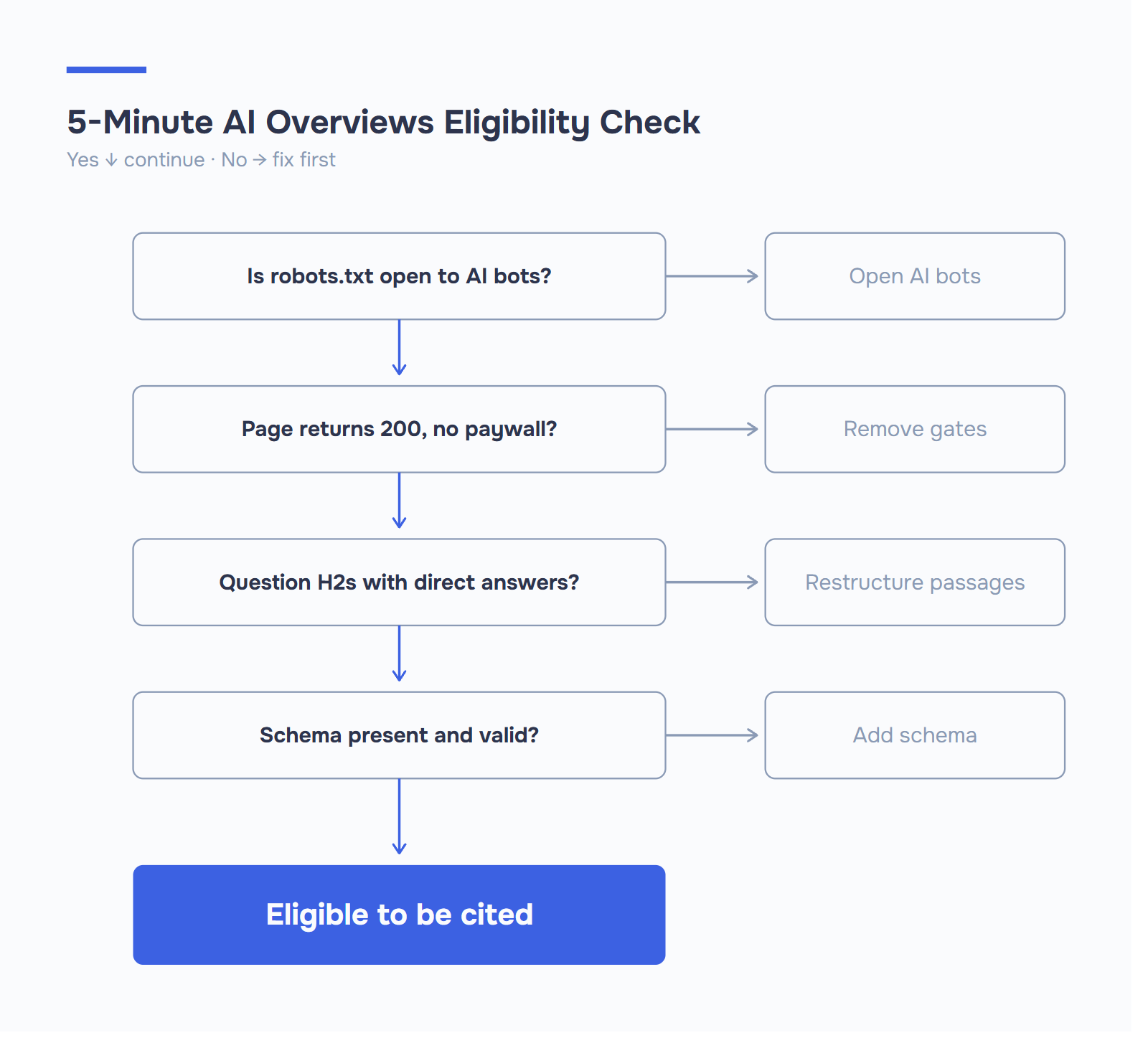
Выполните проверку доступа поисковых ботов к Вашему домену. Инструмент AI Visibility от ICODA проверяет, могут ли основные поисковые боты AI добраться до Ваших страниц - PerplexityBot, OAI-SearchBot, GPTBot, Google-Extended, ClaudeBot - и отмечает схему и технические сигналы, которые каждый бот использует, чтобы решить, стоит ли ссылаться на Вас. Большинство сайтов, которые мы проверяли, обнаружили хотя бы один случайный блок, о котором они не знали.
Бренды, выигрывающие в цитировании AI Overview в 2026 году, - это не те, у кого самые большие домены. Это те, чьи страницы чисты, структурированы, легко ползают и заслуживают доверия - на уровне прохода, а не только на уровне страницы. Эта работа вполне выполнима. Вопрос в том, начнете ли Вы сейчас или после еще одного квартала эрозии CTR.
Часто задаваемые вопросы (FAQ)
Вам нужно занять место в топ-10 - но не обязательно №1. Страницы на позициях 3-8 регулярно попадают в обзоры ИИ, если их структура чище, чем у верхнего результата. ИИ выбирает наиболее четкий отрывок, а не самый сильный авторитет домена. Позиция 1 дает Вам примерно 53% шансов на цитирование; позиция 10 - около 37%. Этот разрыв реален, но не непреодолим.
Да, и это одно из немногих мест, где небольшие сайты имеют структурное преимущество. AI-обзоры декомпозируют запросы на подвопросы с помощью "веерного раскрытия запроса", а затем извлекают наиболее четкий ответ для каждого фрагмента - независимо от размера домена. Целенаправленная страница в 600 слов, которая полностью отвечает на один узкий подзапрос в чистом блоке H2, победит раздутую страницу корпоративного уровня, на которой тот же ответ размещен в седьмом абзаце.
Схема FAQPage дает ощутимый эффект - по данным независимых исследований, ее влияние на цитируемость составляет около 30%. Она работает потому, что предварительно формирует Ваш контент в виде пар "вопрос-ответ", а именно так системы искусственного интеллекта извлекают и представляют информацию. Тем не менее, схема работает только в том случае, если она отражает то, что действительно видно на странице. Разметка часто задаваемых вопросов, которых нет в Вашем HTML, приведет к тому, что Вы будете наказаны, а не продвинуты.
Блокировка PerplexityBot делает Вас совершенно невидимым при цитировании Perplexity - он строго соблюдает директивы robots.txt. В частности, для обзоров Google AI Вам необходимо убедиться, что Google-Extended и Googlebot разрешены. Это отдельные боты с отдельными правилами, и часто можно обнаружить случайные блокировки из старых конфигураций robots.txt, которые появились раньше, чем краулеры AI. Проведите аудит доступа краулеров прежде всего - любая другая оптимизация не имеет смысла, если боты не могут попасть на Ваши страницы.
Почти наверняка да. Когда AI-обзор срабатывает для запроса, в котором Вы занимаете определенное место, GSC считает два показа, но только одну возможность клика - и большинство пользователей не кликают. Отпечаток таков: количество показов растет, количество кликов остается неизменным или падает, CTR падает, средняя позиция сохраняется или улучшается. Проверьте фильтр "Внешний вид поиска" в GSC и отфильтруйте по "Обзору AI", чтобы убедиться, какие запросы так с Вами поступают.
Поделиться


Оцените статью












